이번 주도 시각화의 연속...
한 번 열심히 복습해보자!

가장 먼저 다뤄본 데이터는
전국 신규 민간 아파트 분양가격 데이터이다!
데이터는 https://www.data.go.kr/data/15061057/fileData.do
주택도시보증공사_전국 신규 민간아파트 분양가격 동향_20211231
주택분양보증을 받아 분양한 전체 민간 신규아파트 분양가격 동향으로 지역별, 면적별 분양가격 등의 자료를 제공합니다.<br/>해당 데이터는 주택도시보증공사 홈페이지 및 통계청 KOSIS에서도
www.data.go.kr
이곳 에서 다운받았다!
일단 필요라이브러리 호출!
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
import koreanize_matplotlib
# 그래프에 retina display 적용
%config InlineBackend.figure_format = 'retina'
glob을 이용해 데이터를 로드하고
최근 데이터(2015년 이후)데이터를 df_last에
그 이전 데이터를 df_first에 할당해주자!
from glob import glob
file_names = glob('data/apt*.csv')
df_last = pd.read_csv(file_names[1], encoding='cp949')
df_first = pd.read_csv(file_names[0], encoding='cp949')
df_last를 살펴보면...
df_last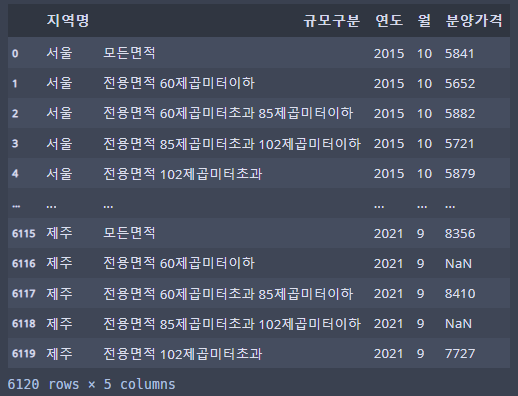
집계 데이터는 아니고 약간 깔끔한 것 같다!
df_last는...
df_first
집계 데이터라서 melt가 필요할 것 같다!
먼저 df_last전처리를 해보자!
info()를 통해 결측치 확인!
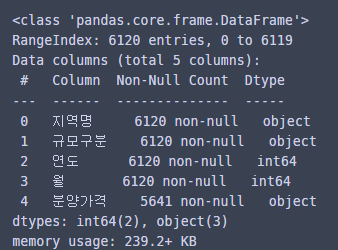
분양가격에 결측치가 있다!
결측치 비율을 보면...
# 결측치 비율
df_last.isna().mean()
분양 가격이 8퍼센트가 조금 안되게 결측된 것을 확인할 수 있다!
분양 가격이 object형식이기 때문에 pd.to_numeric을 통해 float형식으로 바꿔줄건데...
결측치가 포함되어 있으니 errors='coerce'를 통해 강제로 실행시켜주자!
df_last['분양가격'] = pd.to_numeric(df_last['분양가격'], errors='coerce')
또 df_first에는
평당분양가격만 나와있기 때문에 3.3을 곱해서 평당분양가격 컬럼을 생성해주자!
df_last['평당분양가격'] = df_last['분양가격'] * 3.3
df_last의 규모구분 컬럼의 유일값을 확인!
df_last['규모구분'].unique()
규모구분을 범위로 바꿔서 전용면적 컬럼을 생성해주자!
df_last['전용면적'] = df_last['규모구분'].str.replace('전용면적|제곱미터|이하| ', '', regex=True)
df_last['전용면적'] = df_last['전용면적'].str.replace('초과', '~')
그 다음 필요 없는 컬럼인 규모구분과 분양가격을 제거해주면...
df_last = df_last.drop(['규모구분', '분양가격'], axis=1)
df_last
df_last의 전처리는 요정도 까지 해봤다!
df_last의 히스토 그램을 그려보면...

수치형 데이터의 빈도수를 확인할 수 있다!
이번엔 seaborn의 pairplot으로
모든 수치형 변수의 관계를 지역별로 살펴보면...
sns.pairplot(df_last, hue='지역명', corner=True);
이렇다!
이번엔 df_first(2015년 이전)의 데이터를 전처리해보자!
df_first.isna().sum()
일단 결측치는 없다!
id_vars를 지역명으로 해서 일단 녹여보자!
df_first_melt = pd.melt(df_first, id_vars='지역')
df_first_melt
variable 컬럼에 연도월데이터가 들어가있고...
value 컬럼에 평당분양가격이 들어가있다!
컬럼명을 바꿔주면...
df_first_melt.columns = ["지역명", "기간", "평당분양가격"]
df_first_melt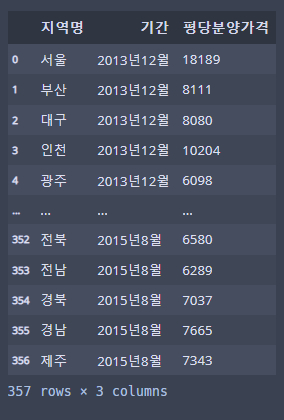
데이터 프레임이 요정도!가 된다!
이제 연도 월을 분리해보자!
연도와 월을 분리시키는 함수를 만들고...
def parse_year(date):
return int(date.split('년')[0])
def parse_month(date):
return int(date.split('년')[1].replace('월', ''))
apply로 컬럼에 적용시켜 연도와 월 파생변수를 만들자!
df_first_melt['연도'] = df_first_melt['기간'].apply(parse_year)
df_first_melt['월'] = df_first_melt['기간'].apply(parse_month)
이제 df_first, df_last를 조인하기 위해 준비해보자!
남길 컬럼만 지정해준뒤
df_last에서는 전용면적이 모든면적인 데이터만 뽑아오자
cols = ['지역명', '연도', '월', '평당분양가격']
df_last_prepare = df_last.loc[df_last['전용면적'] == '모든면적', cols]
df_first_prepare = df_first_melt[cols].copy()
df_last_prepare을 보면...
df_last_prepare
이렇고
df_first_prepare은...
df_first_prepare
이렇다!
concat으로 데이터를 합치면...
df = pd.concat([df_first_prepare, df_last_prepare])
df
분석해볼 데이터프레임 완성!
일단 연도별 데이터 개수를 확인하자!
df['연도'].value_counts().sort_index()
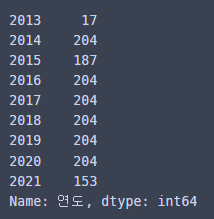
2013년이 좀 적다!
이제 groupby로 지역별 평당분양가격의 평균을 막대그래프로 시각화해보자!
df.groupby(['지역명'])['평당분양가격'].mean().plot.bar(rot=0, figsize=(10, 5), title='지역별 평당분양가격');
서울이 가장 비싸네?...
이번엔 연도별 지역별 평당분양가격의 평균을 groupby로 살펴보자!
yprice = df.groupby(['연도', '지역명'])['평당분양가격'].mean().unstack()
yprice
연도별로 서울, 경기, 제주만 선그래프로 비교해보면...

2020년 이후로 제주의 집값이 많이 오른 것을 확인할 수 있다!
이번엔 연도별 지역별 평당분양가격의 평균을 그룹바이로 만들어보자!
g = df.groupby(["연도", "지역명"])["평당분양가격"].mean()
g
이것을 보기 편하게 전치행렬로 히트맵을 만들어보면...

이렇다!
pivot_table로도 똑같이 해볼 수 있다!
연도를 인덱스로, 지역명을 컬럼으로 평당분양가격을 values로 설정하면...
# 연도를 인덱스로, 지역명을 컬럼으로 평당분양가격을 피봇테이블로 그려봅니다.
p = df.pivot_table(values='평당분양가격', index='연도', columns='지역명')
p
이렇게 똑같이 나오고!
이번엔 히트맵에 수치까지 넣어서 그려보면...

이렇다!
서울이 제일 비싼 것을 볼 수 있고 2021년 제주 집값이 상당하다는 것을 알 수 있다!
이번에는 연도별 평당분양가격의 평균을 막대그래프와 선그래프로 보자!
먼저 막대그래프!
# barplot 으로 연도별 평당분양가격 그리기
plt.figure(figsize=(12, 4))
sns.barplot(data=df, x='연도', y='평당분양가격', ci=None).set_title('연도별 평균 평당분양가격1');
선그래프!
# pointplot 으로 연도별 평당분양가격 그리기
plt.figure(figsize=(12, 4))
sns.pointplot(data=df, x='연도', y='평당분양가격', ci=None).set_title('연도별 평균 평당분양가격2');
두 그래프를 통해 평균 평당분양가격이 증가추세임을 알 수 있다!
이번엔 연도별 평당분양가격의 분포를 boxplot과 violinplot, swarmplot으로 그려보자!
boxplot!
# 연도별 평당분양가격 boxplot 그리기
plt.figure(figsize=(12, 4))
sns.boxplot(data=df, x='연도', y='평당분양가격').set_title('연도별 평당분양분양가격 분포1');
violinplot!
# 연도별 평당분양가격 violinplot 그리기
plt.figure(figsize=(12, 4))
sns.violinplot(data=df, x='연도', y='평당분양가격').set_title('연도별 평당분양분양가격 분포2');
swarmplot
# 연도별 평당분양가격 swarmplot 그리기
plt.figure(figsize=(30, 10));
sns.swarmplot(data=df, x='연도', y='평당분양가격').set_title('연도별 평당분양분양가격 분포3');
평당분양가격의 분포가 시간이 지날수록 점점 위쪽에 분포하는 것을 알 수 있다!
지역별 평당분양가격의 평균도 막대그래프로 보자!
내림차순으로 정렬도 해줬다!
region_price = df.groupby("지역명")["평당분양가격"].mean().sort_values(ascending=False)
region_price.index
plt.figure(figsize=(12, 4))
sns.barplot(data=df, x='지역명', y='평당분양가격', order=region_price.index, ci=None).set_title('지역별 평균 평당분앙갸격');
서울이 제일 높고 충북이 가장 낮다!
마지막으로 지역별 평당분양가격의 분포도 살펴보자!
swarmplot으로 보면...
# swarmplot 으로 지역별 평당분양가격을 그려봅니다.
plt.figure(figsize=(12, 4))
figure = sns.swarmplot(data=df, x='지역명', y='평당분양가격', order=region_price.index, size=1.2).set_title('지역별 평당분앙갸격 분포3');
서울이 가장 비싸게 분포해있고 제주의 비싸게 분포한 점들(2021년) 등을 관찰할 수 있다!
전국 평균 분양가격 데이터는 요정도? 살펴봤다!

두번째로 다뤄본 데이터는...
https://kosis.kr/statHtml/statHtml.do?orgId=115&tblId=DT_115012_A002&conn_path=I2
KOSIS
kosis.kr
코시스의 데이터이다!
일단 필요 라이브러리 호출!
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
import plotly.express as px
import koreanize_matplotlib
# 그래프에 retina display 적용
%config InlineBackend.figure_format = 'retina'
csv파일로 저장해논 데이터를 불러오자!
from glob import glob
file_name = glob("data/kosis*.csv")[0]
raw = pd.read_csv(file_name, encoding='cp949')
raw
월별 전산업, 소부장의 수입, 수출액이 나와있는 데이터이다.
결측치를 알단 확인해보고...
# 결측치 합계 구하기
raw.isna().sum()
결측치를 히트맵으로도 확인해보자!
# 결측치 시각화
sns.heatmap(raw.isnull(), cmap='gray_r');
코시스데이터는 집계 데이터를 제공하기 때문에
Tidy data로 melt해줘야한다!
집계 데이터를 tidy data로 만들어보면...
# melt 로 깔끔한 데이터(tidy data)만들기
df = raw.melt(id_vars=raw.columns[:4], var_name='연월', value_name='달러')
df
한 컬럼에 한가지 변수만 있게 된다!
info를 확인!
# info 로 요약정보 보기
df.info()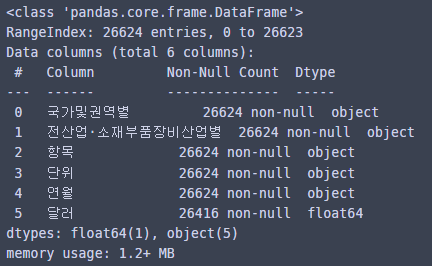
결측치를 제거해준다!
# 결측치가 있다면 제거하기
df = df.dropna()
df.info()
유일값의 수도 확인!
# 유일값의 수 구하기
df.nunique()
필요없는 단위 컬럼 제거!
# 단위는 사용하지 않기 때문에 drop으로 제거하기
df = df.drop(columns='단위')
df
좀 깔끔한 데이터프레임이 되었다!
이제 항목에서 액과 [$]를 제거하고 수출, 수입만 남게 하자!
정규표현식을 사용해 제거해주고...
# 항목에서 액$ 제거
df["항목"] = df["항목"].replace('액|\$|\[|\]', '', regex=True)연월에서 월을 제거 한 후 연, 월 파생변수를 만들어주자!
# 연월에서 월 제거
df["연월"] = df['연월'].str.replace(' 월', '')
# 연, 월 파생변수 만들기
df["연"] = df['연월'].str.split('.', expand=True)[0].astype(int)
df["월"] = df['연월'].str.split('.', expand=True)[1].astype(int)
1, 2번째 컬럼명을 각각 국가권역, 산업으로 바꿔주고 데이터프레임을 확인하면...
df = df.rename(columns={"국가및권역별": "국가권역", "전산업·소재부품장비산업별":"산업"})
df
시각화해볼 데이터가 완성!

먼저 수치형 데이터와 범주형 데이터의 기술통계값을 확인하자!
# describe
df.describe()
# describe
df.describe(include='O')
기술통계를 확인해봤다!
이제 국가권역의 유일값을 확인해보면...
df["국가권역"].unique()
이렇다!
여기서 소부장(소재·부품·장비산업) 데이터만 국가권역별로 합계 달러값이 top20인 데이터만 보자!
# 국가권역 달러 합계 금액 상위 20개
# 소재·부품·장비산업 텍스트가 길고 실수할 것 같다면 간단한 단어로 전산업 외 데이터를 보는 방법으로 구했습니다.
# KOSIS 데이터를 볼 때 주의할 점은 제공된 데이터가 평균인지 합계인지를 구분할 필요가 있습니다.
# 제공된 데이터는 합계 데이터 입니다.
# (주의!) 평균을 합계를 내면 값이 왜곡될 수 있습니다.
top20 = df[df["산업"] != "전산업"].groupby(["국가권역"])["달러"].sum().nlargest(20)
top20
결과가 이렇게 나왔고...
수평 막대그래프로 시각화해보면...
# df_top20
top20.plot(kind='barh');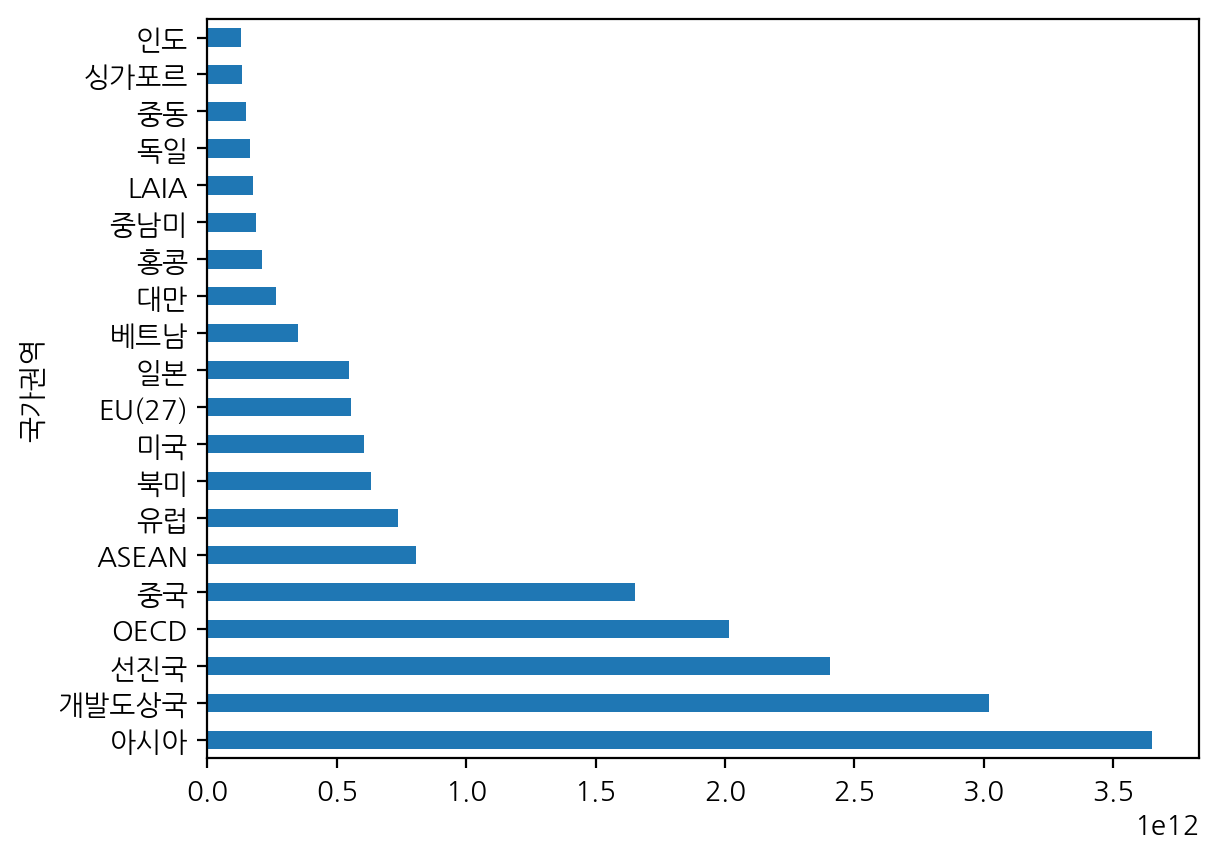
아시아로의 수출 수입액 전체 합계가 가장 많다!
이제 대륙별? 데이터로 시각화 해볼건데...
일단 world리스트를 생성하자!
world = ['아시아', '중동', '유럽', '북미', '중남미', '아프리카',
'오세아니아', '기타지역', 'EU(27)', 'OECD', 'ASEAN',
'LAIA', '선진국', 'OPEC', '개발도상국']
국가 권역이 이 월드 리스트 안에 있는 것만 깊은 복사로 df_world로...
국가 권역이 월드 리스트 안에 있지 않은 것은 깊은 복사로 df_country로 지정하고 shape을 확인해보자!
df_world = df[df['국가권역'].isin(world)].copy()
df_country = df[~df['국가권역'].isin(world)].copy()
df_world.shape, df_country.shape
국가 데이터가 2배 이상 많은 것을 볼 수 있다!
이제 plotly으로...
x는 달러, y는 국가권역으로...
histofunc='count'로 지정한뒤 히스토그램을 그려보자!
# 수치형 일때는 기본값이 sum
px.histogram(df, x='달러', y='국가권역', histfunc='count')
각 국가권역 별로 빈도수가 508개씩 있다!
이번엔 역시 plotly로 x는 달러, y는 국가권역, histfunc='sum', color='항목'으로 지정한뒤...
y축을 오름차순으로 정렬해서 시각화해보자!
px.histogram(df_country, x='달러', y='국가권역',
histfunc='sum', color='항목',
height=700).update_yaxes(categoryorder='total ascending')
각 국가별 전체 수출 수입액 합계가 색으로 구분되어 시각화된다!
이번엔 위에 시각화에서 barmode='group'으로 지정하여 시각화해보자!
px.histogram(df_country, x='달러', y='국가권역',
color='항목', barmode='group',
histfunc='sum',
height=700).update_yaxes(categoryorder='total ascending')
앞선 시각화와 구별되는 점은 수입 수출액이 각각 표시된다는 점이다!
이번엔 barmode='group' 대신 facet_col='항목'으로 해서 subplot으로 그려보자!
px.histogram(df_country, x='달러', y='국가권역',
color='항목', facet_col='항목', height=700)
이렇게 수입과 수출이 각각 subplot으로 그려지게 된다!
이번엔 전산업과, 소부장 산업별로 수입, 수출액 합계를 구해보자!
px.histogram(df_country, x='달러', y='국가권역',
color='항목', facet_col='산업', height=700)
facet_col을 산업으로 해서 전산업과 소부장이 각각 subplot으로 그려졌다!
이번엔 facet_col대신 facet_row를 넣어서 그래프가 상하로 2개 보이게 해보자!
x.histogram(df_country, x='달러', y='국가권역',
color='항목', facet_row='산업', height=700)
같은 시각화지만 위아래로 표시된다!
이번엔 2번째로 해본 시각화(plotly로 x는 달러, y는 국가권역, histfunc='sum', color='항목')에서...
marginal='violin'파라미터를 추가해 준 뒤 분포도 같이 볼 수 있게 그려보자!
px.histogram(df_country, x='달러', y='국가권역',
color='항목', marginal='violin', height=700)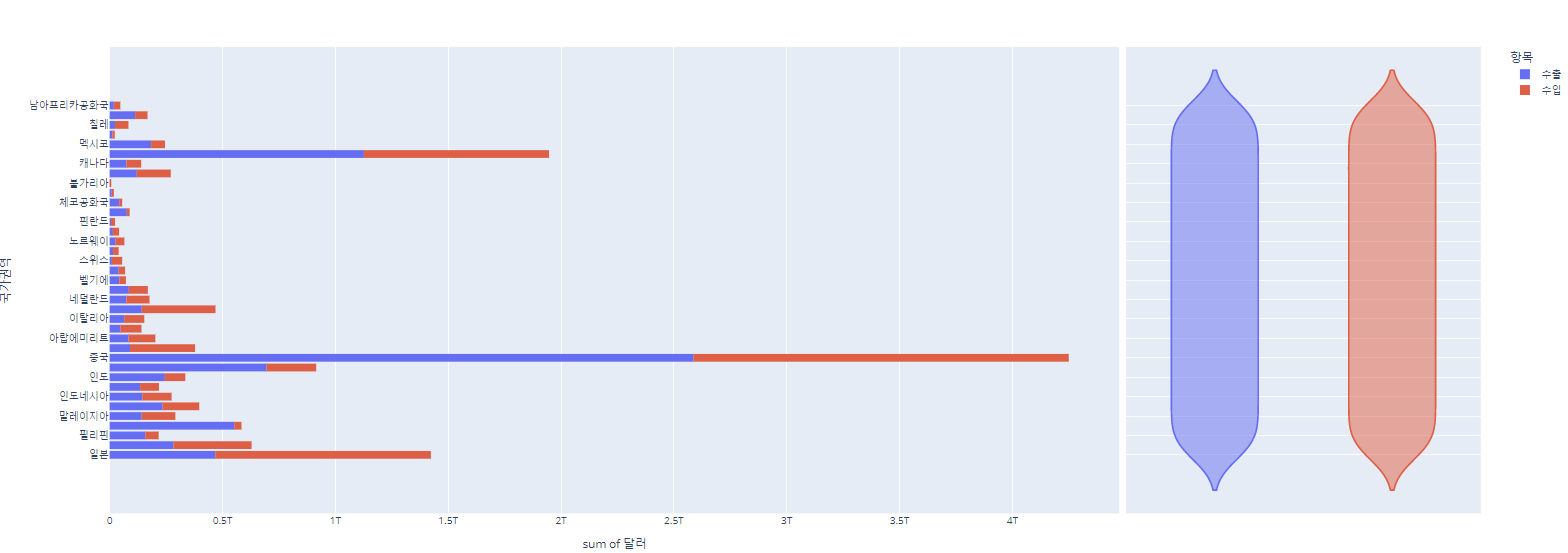
오른쪽에 바이올린 그림이 들어가있다!
이번엔 seaborn의 catplot으로 연도별 수입수출액을 볼건데..
col='산업'으로 해서 전산업, 소부장으로 나눠볼 수 있게하고...
col_wrap=2로 한줄에 2개까지 표시하게 하고...
estimator=np.sum으로 지정해 합계를 볼수 있게 해보자!
kind='point'로 해주자!
sns.catplot(data=df, x='연', y='달러', hue='항목',
col='산업', estimator=np.sum, col_wrap=2, ci=None, kind="point");
2021년 수입수출액이 높은 것을 알 수 있다!
마지막으로 연도별 일본, 중국, 미국, 러시아의 수입, 수출액 합계를 봐보자!
sns.catplot(data=df_country[df_country['국가권역'].isin(['일본', '중국', '미국', '러시아'])],
x='연', y='달러', hue='항목',col='국가권역',
estimator=np.sum, col_wrap=2, ci=None, kind="point", sharex=False);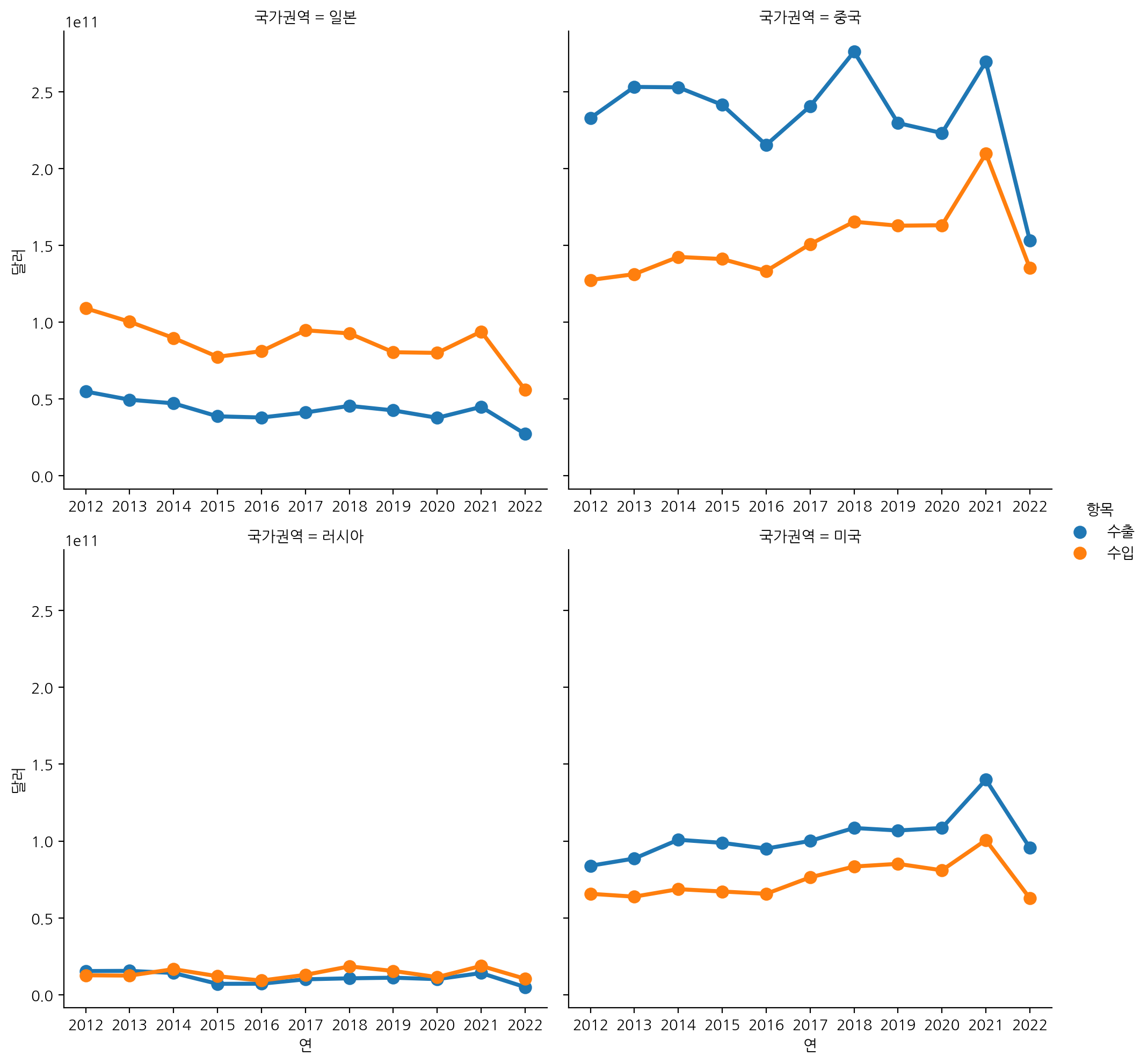
중국 의존도가 상당히 높은 것을 알 수 있다!
코시스 데이터 시각화는 요정도! 해봤다!

마지막으로 다뤄본 데이터는
https://www.data.go.kr/data/15083033/fileData.do
소상공인시장진흥공단_상가(상권)정보_20221231
영업 중인 전국 상가업소 데이터를 제공합니다.<br/>(상호명, 업종코드, 업종명, 지번주소, 도로명주소, 경도, 위도 등)
www.data.go.kr
이 데이터인데...
여기서 맥도날드, 버거킹, 롯데리아, KFC데이터만 뽑아서 버거지수를 구하고 시각화 해봤다!
필요 라이브러리 로드하고
# glob, pandas, numpy, seaborn, koreanize_matplotlib
from glob import glob
import pandas as pd
import numpy as np
import seaborn as sns
import koreanize_matplotlib
파일 목록을 불러와보자!
file_names = glob('data/store/*.csv')
file_names = sorted(file_names)
file_names
데이터가 지역별로 나눠져 있다!
반복문을 사용해서 전체 파일 로드하고 concat으로 합쳐보자!
df_list = [pd.read_csv(fn) for fn in file_names]
df=pd.concat(df_list)
df
250만행이 넘는 큰 데이터이다!
결측치를 한번 확인해 보자!
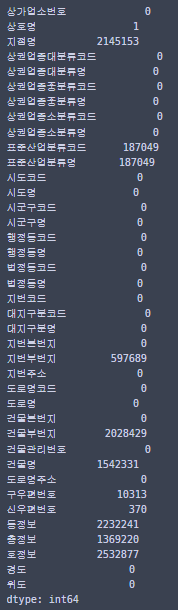
요정도 결측치가 있다!
이제 본격적으로 전처리를 해보자!
일단 우리가 사용할 컬럼만 남겨보자!
cols = ['상호명', '상권업종대분류명', '시도명', '시군구명', '도로명주소', '경도', '위도']
df = df[cols]
df
7컬럼만 남겼다!
결측치 수를 보면...
df.isna().sum()
상호명 없는게 1개 있으니 제거해준다!
df = df[df["상호명"].notnull()]
상호명이 소문자인 데이터도 있을것이니 모두 대문자로 변경해준다!
df["상호명_대문자"] = df['상호명'].str.upper()
그리고 burger리스트를 만들어준다!
burger = ["버거킹", "맥도날드", "KFC", "롯데리아"]
버거킹, BKR, 맥도날드, 멕도날드, 맥도널드, 롯데리아, KFC 케이에프시가 상호명이고...
상권업종대분류명이 음시, 소매, 생활서비스인 것만 추려서 df_b에 저장하자!
df_b = df[df['상호명_대문자'].str.contains(
'버거킹|BKR|맥도날드|멕도날드|맥도널드|롯데리아|KFC|케이에프씨')
& (df['상권업종대분류명'].isin(['음식', '소매', '생활서비스']))
]
df_b
2100개 조금 넘는 매장이 나온다!
브랜드 파생변수를 만들어서 상호명_대문자에 있는 것들을 burger리스트에 있는 것들로 통일해주자!
bmkl = {'버거킹' : '버거킹|BKR',
'맥도날드' : '맥도날드|멕도날드|맥도널드',
'롯데리아' : '롯데리아',
'KFC' : 'KFC|케이에프씨'}
for brand, val in bmkl.items():
df_b.loc[df_b['상호명_대문자'].str.contains(val), '브랜드'] = brand
df_b
브랜드 컬럼이 생성되었다!
그럼 브랜드 컬럼을 통해 전국 브랜드별 매장수를 파악해보면...
df_b['브랜드'].value_counts()
롯데리아가 가장 많고 맥도날드와 버거킹이 나름? 비슷한 것을 볼 수 있다!
이제 groupby로 시도별 브랜드별 개수를 알아보자!
결측치는 0으로 채워줬고, 합계 컬럼도 넣어줬다!
df_skorea = df_b.groupby(['시도명', '브랜드'])['상호명'].count().unstack()
df_skorea = df_skorea.fillna(0)
df_skorea['합계'] = df_skorea.sum(axis=1)
df_skorea = df_skorea.astype(int)
df_skorea
세종에 맥도날드와 롯데리아가 없는 것이 신기하다?
합계를 제외하고 히트맵을 그려보면...
sns.heatmap(df_skorea.iloc[:, :4], annot=True, cmap="Blues", fmt=".0f");
전국 브랜드별 매장 개수를 한눈에 파악할 수 있고!
경기도에 롯데리아가 엄청 많다는 것을 알 수 있다!
이번엔 앞에서 구한 데이터프레임(시도별 브랜드별 개수)에 버거지수 컬럼을 추가하자!
버거지수 : (버거킹 + 맥도날드 + KFC) / 롯데리아
df_skorea["버거지수"] = (df_skorea['버거킹'] + df_skorea['맥도날드'] + df_skorea['KFC']) / df_skorea['롯데리아']
df_skorea['버거지수'] = df_skorea['버거지수'].round(2)
df_skorea = df_skorea.sort_values('버거지수', ascending=False)
df_skorea
서울 특별시가 버거지수가 가장 높다!
좀 이따 지도에 쓸 위도, 경도를 구할 건데...
시도별 매장 위도, 경도의 평균으로 구해보자!
df_skorea_latlong = df_b.groupby('시도명').agg({'위도':'mean', '경도':'mean'})
df_skorea_latlong
위도 경도값을 기존 df_skorea에 추가해주자!
df_skorea = df_skorea.merge(df_skorea_latlong, on='시도명')
df_skorea
다음으로 시군구별로 브랜드별 매장수 와 버거지수까지 구해보자!
df_dist_count = df_b.groupby(['시도명', '시군구명', '브랜드']
)['상호명'].count().unstack().fillna(0).astype(int)
df_dist_count["버거지수"] = (df_dist_count['버거킹']
+ df_dist_count['맥도날드']
+ df_dist_count['KFC']) / df_dist_count['롯데리아']
df_dist_count['버거지수'] = df_dist_count['버거지수'].round(2)
df_dist_count = df_dist_count.sort_values('버거지수', ascending=False)
df_dist_count
롯데리아가 없는 곳은 inf로 표시된다!
전국은 너무 많으니까 서울시만 봐보자!
df_seoul_gu = df_dist_count.loc['서울특별시']
df_seoul_gu
서초구가 버거지수가 제일 높다!
이번엔 서울 구별 매장수를 히트맵으로 그려보면...
sns.heatmap(df_seoul_gu[burger], annot=True, fmt='.0f', cmap='Blues');
강남에 버거킹이랑 KFC가 많은 것을 볼 수 있다!
상관계수도 한번 구해보자!
먼저 전국 매장의 브랜드별 상관관계를 구해보자!
앞에서 구한 df_dist_count(시도, 시군구별, 브랜드 빈도수)를 통해 구한다!
corr = df_dist_count[burger].corr()
corr
KFC와 버거킹의 상관계수가 크다!
pairplot으로 시각화해보면...
sns.pairplot(df_dist_count[burger], corner=True, kind='reg');
산점도와 함께 볼 수 있다!
이번엔 서울지역만 상관계수를 보자!
corr_seoul = df_dist_count.loc['서울특별시', burger].corr()
corr_seoul
서울은 맥도날드와 KFC의 상관계수가 큰 것을 확인할 수 있다!
서울 상관계수의 히트맵을 그려보자!
np.triu으로 상삼각행렬을 만들어 마스킹을 해줬고...
색상도 눈에 잘 띄는 색으로 지정해주고...
눈에 보이는 색의 최대 최소를 1, -1로 해줬다!
mask = np.triu(np.ones_like(corr_seoul))
sns.heatmap(corr_seoul, annot=True, cmap="seismic", vmin=-1, vmax=1, mask=mask);
한번에 알아보기 쉽다!
이번에는 folium을 통해 지도에 동그라미를 그려보자!
서울에서만 그려보자!
우선 folium 불러오고...
import folium
다음으로 서울데이터만 구하고 지도의 중심을 정하기 위해 서울데이터의 위도, 경도 평균을 구해준다!
# 서울 데이터만 구하기
df_seoul = df_b[df_b['시도명']=='서울특별시'].copy()
latlong = df_seoul[['위도', '경도']].mean().values
이제 본격적으로 지도에 표시를해보면...
f_map = folium.Map(latlong, zoom_start=12, tiles="Stamen Toner")
for i in df_seoul.index:
sub_lat = df_seoul.loc[i, "위도"]
sub_long = df_seoul.loc[i, "경도"]
brand = df_seoul.loc[i, '브랜드']
title = f"{df_seoul.loc[i, '상호명']} - {df_seoul.loc[i, '도로명주소']}"
color = {"롯데리아" : "yellow", "버거킹": "blue", "맥도날드": "orange", "KFC":"red"}
folium.CircleMarker([sub_lat, sub_long],
radius=3,
color=color[brand],
tooltip=title).add_to(f_map)
f_map
롯데리아는 노란색, 버거킹은 파란색, 맥도날드는 주황색, KFC는 빨간색으로 표시했다!
또 마우스를 가져다가 놓으면 상호명-도로명주소 이렇게 나오게 처리해줬다!

이번엔 코로플리스 지도를 그려보자!
필요라이브러리 불러오고...
from urllib.request import urlopen
import json
전국이랑 서울의 위도경도 url을 담아주자!
south_korea_url = "https://raw.githubusercontent.com/southkorea/southkorea-maps/master/kostat/2018/json/skorea-provinces-2018-geo.json"
seoul_geo_url = "https://raw.githubusercontent.com/southkorea/seoul-maps/master/kostat/2013/json/seoul_municipalities_geo_simple.json"
전국이랑 서울의 GeoJSON을 로드해오자!
# 전국 시도 GeoJSON
with urlopen(south_korea_url) as response:
ko_geojson = json.load(response)
# 서울 시도 GeoJSON
with urlopen(seoul_geo_url) as response:
seoul_geojson = json.load(response)
시군구별 매장의 위도, 경도 평균값을 그 시군구의 위도, 경도로 해주자!
city_latlong = df_b.groupby(['시도명','시군구명']).agg({'위도':'mean', '경도':'mean'})
city_latlong
이 데이터를 시군구별 매장개수, 버거지수가 나와있는 df_dist_count와 조인한 후 서울의 데이터만 가져와보자!
df_seoul_index = df_dist_count.join(city_latlong).loc['서울특별시'].reset_index()
df_seoul_index
이 데이터를 가지고 plotly로 서울의 코로플리스 지도를 그려보자!
import plotly.express as px
fig = px.choropleth(df_seoul_index, geojson=seoul_geojson, color="버거지수",
locations="시군구명", featureidkey="properties.name", labels="시군구명",
projection="mercator", color_continuous_scale=px.colors.colorbrewer.Blues)
fig.update_geos(fitbounds="locations", visible=False)
fig.update_layout(margin={"r":0,"t":0,"l":0,"b":0})
이렇게 그려진다!
이번엔 전국 코로플리스 지도를 그려볼건데...
아까 만들어본 df_skorea데이터를 reset_index()해서 사용하자!
df_skorea_index = df_skorea.reset_index()
df_skorea_index
이렇게 설정해주면...
# 시도별 버거지수
import plotly.express as px
fig = px.choropleth(df_skorea_index, geojson=ko_geojson, color="버거지수",
locations="시도명", featureidkey="properties.name", labels="시도명",
projection="mercator", color_continuous_scale=px.colors.colorbrewer.Blues)
fig.update_geos(fitbounds="locations", visible=False)
fig.update_layout(margin={"r":0,"t":0,"l":0,"b":0})
이렇게 나온다!
서울이 버거지수가 가장 높다!
이번엔 서울의 코로플리스 지도를 folium으로 그려보자!
f_map = folium.Map(latlong, zoom_start=11)
folium.Choropleth(
geo_data=seoul_geojson,
name='choropleth',
data=df_seoul_index,
columns=['시군구명', '버거지수'],
key_on='feature.properties.name',
fill_color='Blues',
fill_opacity=0.7,
line_opacity=0.2,
legend_name='버거지수'
).add_to(f_map)
f_map
이렇게 지도 위에 그릴 수 있다!
전국 지도를 그려보면...
먼저 전국 지도를 잘 볼 수 있게 지도의 중심을 전라북도의 매장 위도, 경도 평균으로 하자!
latlong = df.loc[df["시도명"] == "전라북도", ["위도", "경도"]].median().values# 전국 Choropleth
f_map = folium.Map(latlong, zoom_start=6.5)
folium.Choropleth(
geo_data=ko_geojson,
name='choropleth',
data=df_skorea_index,
columns=['시도명', '버거지수'],
key_on='feature.properties.name',
fill_color='Blues',
fill_opacity=0.7,
line_opacity=0.2,
legend_name='버거지수'
).add_to(f_map)
f_map
이렇게 그려진다!
이번주는 시각화 심화버전을 배운 느낌이다...
folium사용법과 코로플리스 지도 그리는게 아직 안와닿는다..
다른 데이터로 연습을 해봐야겠다!
스타벅스 매장 데이터로 한 연습...
2023.02.12 - [재미로 하는 코딩] - folium, plotly로 스타벅스 매장 표시해보기
folium, plotly로 스타벅스 매장 표시해보기
저번에 미니프로젝트로 스타벅스 매장 데이터를 수집했다! 2023.01.31 - [멋쟁이사자처럼 AI스쿨] - 멋쟁이사자처럼 miniproject1(스타벅스 매장 정보 수집하기) 멋쟁이사자처럼 miniproject1(스타벅스 매
helpming.tistory.com
좀 더 심화적으로 해보고 싶은데...
수업시간에 한 정도로만 그친듯...
'멋쟁이사자처럼 AI스쿨' 카테고리의 다른 글
| 통계 특강2 (2) | 2023.03.01 |
|---|---|
| 통계 특강1 (0) | 2023.02.16 |
| 멋쟁이사자처럼miniproject2(행복지수와 코로나확진률) (0) | 2023.02.08 |
| 멋쟁이사자처럼 AI스쿨 7주차 회고 (0) | 2023.02.02 |
| 멋쟁이사자처럼 miniproject1(네이버 증권 웹사이트 정보 수집하기) (0) | 2023.02.02 |




댓글