이번주에는 데이터 전처리와 시각화 관련 수업이었다...
새로운 데이터가 주어졌을 때 잘 할 수 있을지는 모르겠지만...
한번 배운 것을 확인해 보자!

처음으로 다뤄본 데이터는 서울시 코로나19 발생동향 데이터이다!
일단 필요한 라이브러리를 업로드하고...
# pandas, numpy, matplotlib.pyplot 불러오기
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
한글폰트 사용을 위해 코리안와이즈 매트플롯립을 설치했다!
# 한글폰트 사용을 위해 설치
!pip install koreanize-matplotlib
설치가 잘 끝났고...
여러 부수적인 것들을 설정!
import koreanize_matplotlib
# 그래프에 retina display 적용
%config InlineBackend.figure_format = 'retina'
# 노트북 안에서 그래프를 디스플레이 하겠다는 설정
%matplotlib inline
이제 다운 받아온 데이터 2개를 불러온다!
# seoul-covid19-2021-12-18.csv 불러오기
from glob import glob
files = glob('data/seoul-covid*.csv')
file_paths = sorted(files)
file_paths
데이터가 불러와졌고!
첫 데이터를 확인해보면...
df_01 = pd.read_csv(file_paths[0])
print(df_01.shape)
df_01.head()이십만개의 행을 가진 데이터가 아래처럼 되어있다!

두번째 데이터는...
18646개의 행을 가진 데이터이다!
df_02 = pd.read_csv(file_paths[1])
print(df_02.shape)
df_02.head()

두 데이터가 같은 컬럼을 가졌기 때문에 concat으로 합쳐보면...
# pd.concat 으로 [df_01, df_02] 합치고 df 변수에 할당하기
df = pd.concat([df_01, df_02])
df아래와 같이 하나의 데이터프레임을 만들 수 있다!

중복을 제거해주고...(중복된 데이터가 없긴 하다!)
df = df.drop_duplicates()
nunique()를 통해 각 컬럼의 유일값 수를 확인해보면...
df.nunique()
연번의 개수가 행의 개수임을 알 수 있다!
그래서 연번을 인덱스로 해주고 정렬도 하자!
df = df.set_index('연번')
df = df.sort_index()
df
연번이 인덱스가 된 것을 볼 수 있다!
데이터에 결측치가 보이니 결측치를 개수와 비율을 보고
# 결측치의 합계를 구합니다.
# isnull()
df.isnull().sum()
# 평균(mean)을 통해 결측치의 비율을 구합니다.
df.isnull().mean()
퇴원현황에 55149개, 25%정도의 결측치와 결측비율을 확인했다!
이제 수치형, 범주형 컬럼의 기술통계값을 확인해보자!
# describe()로 기술통계 값을 구합니다.
df.describe()
# describe(include="object") 로 문자 데이터에 대한 기술통계 값을 구합니다.
df.describe(include="object")
대략적으로 데이터를 확인했다!
이번엔 날짜 데이터 타입을 변경해보기로 하자!
# 확진일 Series 형태로 가져오기
df['확진일']
확진일 데이터를 보면 데이터타입이 오브젝트 이다.
pd.to_datetime()을 통해 datetime형식으로 바꿔보면...
df['확진일'] = pd.to_datetime(df['확진일'])
df['확진일']
잘 바뀌었다.
확진일 변수로 연도, 월, 일, 요일 파생변수를 만들어보자!
df['연도'] = df['확진일'].dt.year
df["월"] = df['확진일'].dt.month
df["일"] = df['확진일'].dt.day
df["요일"] = df['확진일'].dt.dayofweek
df
파생변수가 생성됐다!
연도-월 별 데이터 시각화를 위해 연도-월 파생변수도 만들어보자!
df['연도월'] = df['확진일'].astype(str).str[:7]
연도-월 컬럼이 생성됐다!
연도월 컬럼을 value_counts()를 통해 확인해보면
df['연도월'].value_counts().sort_index()
대체로 21년이 20년 보다 많고, 1월에서 12월로 갈 수록 증가하는 추세임을 볼 수 있다!
이제 요일을 한글로 만들어주자!
#find_dayofweek 함수로 요일 숫자를 넘겨주면 요일명을 반환하는 함수
def find_dayofweek(day_no):
dayofweek = "월화수목금토일"
return dayofweek[day_no]위 코드 처럼 요일숫자를 넘겨주면 요일명을 반환해주는 함수를 만들고...
map함수를 통해 컬럼에 적용시키면...
# map을 사용해서 요일 컬럼을 요일명으로 변환하고 "요일명"이라는 새로운 컬럼에 저장하기
df["요일명"] = df['요일'].map(find_dayofweek)
한글로 된 요일이 요일명 컬럼으로 생성됐다!
이제 한번 전체 수치 변수의 히스토그램을 그려보자!
# 이론적으로 히스토그램은 범주형, 수치형 데이터에 모두 사용가능하지만,
# pandas, matplotlib에서는 주로 수치형데이터에만 사용합니다.
# df.hist로 히스토그램 그리기
df.hist(bins=50, figsize=(12, 6));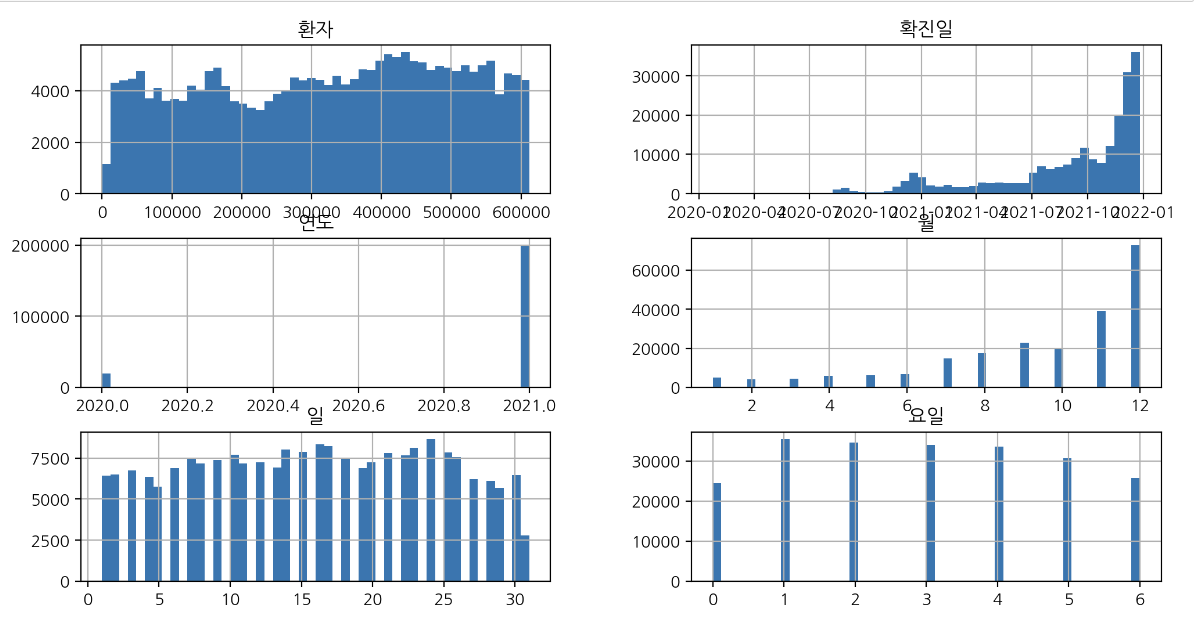
연속변수에 가까울수록 막대그래프가 연속적이고....
이산변수는 그래프가 뚝뚝 끊기는 것을 볼 수 있다!
이제 value_counts()로 연도의 빈도수를 구해보자!
# "연도" 컬럼을 통해 빈도수 구하기
df['연도'].value_counts()
2021년이 2020년보다 많다!
이번엔 연도월의 빈도수를 구하고 막대 그래프로 시각화해보자!
# 연도월에 대한 빈도수 구하기
# 빈도수를 구하고 sort_index 로 정렬합니다.
year_month = df['연도월'].value_counts().sort_index()
year_month
시각화해보면
# 연도월을 막대 그래프로 시각화 합니다.
year_month.plot.bar(figsize=(12, 3), title='월별 확진 수', rot=30);
월별 확진자수를 한눈에 파악할 수 있다!
이번엔 요일별 확진수를 구하고 시각화해보자!
# 빈도수 구하고 인덱스 번호로 정렬합니다.
# weekday_count 변수에 담아 재사용합니다.
# weekday_count
weekday_count = df['요일'].value_counts().sort_index()
weekday_count
이렇게 나온다!
이제 인덱스값을 요일명으로 변경하고 시각화를 해보자!
# 리스트컴프리헨션 사용해서 리스트 만들기
# "월화수목금토일" 리스트로 만들어 weekday_list 변수로 재사용하기
weekday_list = [i for i in '월화수목금토일']# 인덱스 값을 요일명으로 변경하고 시각화 합니다.
weekday_count.index = weekday_list
weekday_count.plot.bar(rot=0, title='요일별 확진수')
화요일이 제일 많고 월요일 일요일이 적은 것을 볼 수 있다!
확진일 빈도수를 구하고 시각화해보자!
# df["확진일"] 빈도수 구하고 인덱스 값인 날짜로 정렬하기
day_count = df['확진일'].value_counts()
day_count
# 선 그래프로 시각화 하기
# 형식이 datetime이기 때문에 정렬 안해도 자동으로 시간순으로 그래프가 그려진다
day_count_graph = day_count.plot(figsize=(12, 6), rot=80, title='확진일별 빈도수');
시간순으로 늘어나고... 겨울부근에 확진자가 폭등?하는 것을 확인할 수 있다!
이번엔 전체 확진일 데이터를 만들어보자!
head()로 확진일 앞부분의 데이터를 보면...

이렇게 빈 날짜가 있는 것을 확인할 수 있다!
그리하여 이렇게 첫 날짜랑 마지막 날짜를 구해준다!
# 기존 확진일 수로 연산을 한다면 확진자가 있는 날만 연산을 하게된다.
# 확진자가 없는 날은 0으로 표기하기 위해 전체 날짜를 구하고
# 전체 날짜에서 확진자가 없는 날은 0으로 결측치를 대체할 예정
last_day = day_count.index[-1]
first_day =day_count.index[0]
last_day, first_day
그 다음 pd.date_range로 전체 기간을 만들어 주고 데이터프레임으로 만들어주자!
# pd.date_range 로 전체 기간을 생성합니다.
all_day = pd.date_range(first_day, last_day)
# all_day 를 데이터프레임으로 변환합니다.
df_all_day = all_day.to_frame()
df_all_day
이렇게 모든 날짜에 대한 데이터프레임이 만들어졌다!
그 다음...
앞에서 구한 확진자수를 데이터프레임에 추가해주고!
필요없는 컬럼 삭제 하고...
결측치를 채워주면!
# "확진수" 라는 컬럼을 생성해서 위에서 구한 day_count 를 추가합니다.
# 확진자가 없는 날도 인덱스에 생성이 됩니다.
df_all_day['확진수'] = day_count
# 필요 없는 0 컬럼을 삭제합니다.
del df_all_day[0]
# 비어있는 값은 확진자가 없었던 날이기 때문에 fillna로 0으로 채웁니다.
df_all_day = df_all_day.fillna(0)
df_all_day['확진수'] = df_all_day['확진수'].astype(int)
df_all_day
이렇게 모든 날짜에 대해 확진수를 구했다!
이제 cumsum으로 누적확진수 컬럼을 추가해보자!
# cumsum 으로 "누적확진수" 구해서 새로운 변수에 담기
df_all_day["누적확진수"] = df_all_day['확진수'].cumsum()
df_all_day
이 데이터프레임을 시각화해보면...
# subplots
df_all_day.plot(figsize=(12,6), title='일별 확진수와 누적확진수', subplots=True);
이렇게 subplots를 써서 시각화 해줬다!
이번엔 거주지 빈도수를 구해보자!
# 거주지 빈도수 구하기
df['거주지'].value_counts()
원본데이터를 지키기 위해 거주구라는 컬럼을 새로 생성해주자
# "거주지" => "거주구"로 사본 생성
df["거주구"] = df['거주지']
df
텍스트 앞뒤 공백처리를 해줘서 같은 이름인데 다르게 나뉘는 것들을 처리해주자!
# 텍스트 앞뒤 공백 제거하기
df['거주구'] = df['거주구'].str.strip()
df['거주구'].value_counts()
잘 처리가 되었다!
이번엔 타시도를 기타로 바꿔주자
# 타시도 => 기타로 변경하기
df['거주구'] = df['거주구'].str.replace('타시도', '기타')
거주구 빈도수를 다시 구하고 시각화해보자!
# "거주구" 빈도수 구하기
gu_count = df['거주구'].value_counts()
gu_count
여러가지 기능들을 넣어줘서 시각화 해줬다!
# gu_count 변수에 담긴 값 시각화 하기
# 선그래프 => 연속된 데이터 시각화
# 막대그래프 => 범주형 데이터 시각화
# r => red, b => blue, k => black
gu_count.plot.bar(rot=60);
plt.axhline(5000, c='r', ls=':')
plt.axvline(4, c='b', ls='dashed')
이번에는 crosstab으로 두 개의 변수에 대한 빈도수를 구해보자!
먼저 연도, 퇴원현황 변수에 대한 빈도수를 구해보자!
# pd.crosstab 으로 연도, 퇴원현황 두 개의 변수에 대한 빈도수 구하기
# 연도, 퇴원현황 빈도수 구하기
pd.crosstab(index=df['연도'], columns=df['퇴원현황'])
2021년도가 코로나 확진자가 더 많기 때문에 이런 결과가 나온것같다!
다음으로 연도, 월 두개의 변수에 대한 빈도수를 구하고 시각화해보자!
# pd.crosstab 으로 연도, 월 두 개의 변수에 대한 빈도수 구하기
cross_year_month = pd.crosstab(index=df['연도'], columns=df['월'])
cross_year_month
# 시각화 하기
cross_year_month.T.plot.bar(figsize=(12, 3), rot=0, title='연도월 교차표')
확실히 2021년이 2020년 보다 많고, 1월에서 12월로 갈수로 많아진다!
연도, 요일 변수에 대한 빈도수를 구하고 시각화해보면...
# pd.crosstab 으로 연도, 요일 두 개의 변수에 대한 빈도수 구하기
cross_year_day = pd.crosstab(index=df['연도'], columns=df['요일'])
weekday_list = [day for day in '월화수목금토일']
# 컬럼명 변경하기
cross_year_day.columns = weekday_list
cross_year_day
cross_year_day.T.plot.bar(rot=0, title='연도, 요일별 확진자수');
월요일, 일요일이 확실히 적은 것을 볼 수 있다!
이번에는 거주구, 연도월에 대한 빈도수를 구해보자!
# pd.crosstab 으로 두 개 변수에 대한 빈도수 구하기
# 거주구, 연도월에 대한 빈도수 구하기
cross_gu_month = pd.crosstab(df['거주구'], df['연도월'])
cross_gu_month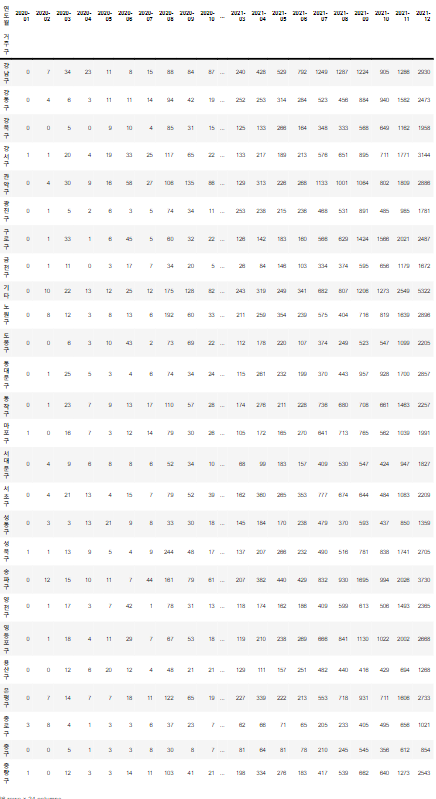
background_gradient로 빈도수를 시각화해줬다!
# background_gradient() 로 빈도수 표현하기
cross_gu_month.style.background_gradient()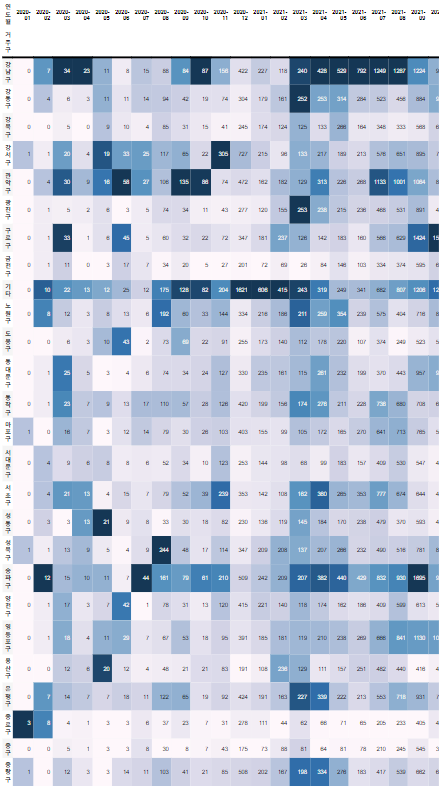
색이 진할 수록 빈도수가 많다!
pivot_table도 사용해 봤다!
거주구별 해외유입에 따른 빈도수를 구해봤다!
# 거주구별 해외유입 여부에 따른 빈도수 구하기
# gu_over_count
pd.pivot_table(data=df, index='거주구', columns='국내해외',
values='환자', aggfunc='count')
이번에는 거주구에 따른 요일별 확진자 빈도수 시각화를 진행했다!
# 거주구에 따른 요일별 확진자 빈도수
# df_gu_weekday[weekday_list].style.bar()
df_gu_weekday = pd.pivot_table(data=df, index='거주구', columns='요일',
values='환자', aggfunc='count')
df_gu_weekday.columns= weekday_list
df_gu_weekday.style.bar()
groupby도 사용했다!
거주구, 국내해외로 그룹화 해서 환자컬럼으로 빈도수를 구했다!
df.groupby(['거주구', '국내해외']).count()['환자'].unstack()
# 같은 방법 df.groupby(['거주구', '국내해외']).['환자']count()
# by에 지정한 값이 멀티인덱스 값으로 나온다.
이번에는 연도월 컬럼으로 데이터프레임 전체를 groupby해봤다!
# 연도, 월을 멀티인덱스로 사용하는 빈도수 구하기
df_year_month = df.groupby(['연도', '월'])
df_year_month.count()
여기서 해외유입만 꺼내서 untstack()으로 멀티인덱스를 풀어봤다!
# unstack()으로 월을 컬럼으로 만들기
df_year_month['해외유입'].count().unstack()
마지막으로 기술통계값을 확인해봤다!

여기까지가 코로나 데이터로 해본 것들이다!

두번째로 다뤄본 데이터는 네이버와 FinanceDataReader를 통해 만든 여러종목 수익률 데이터이다.
https://github.com/financedata-org/FinanceDataReader
GitHub - financedata-org/FinanceDataReader: Financial data reader
Financial data reader. Contribute to financedata-org/FinanceDataReader development by creating an account on GitHub.
github.com
일단 필요 라이브러리를 불러오자!
import pandas as pd
import numpy as np
import FinanceDataReader as fdr
그 다음
https://finance.naver.com/sise/entryJongmok.naver?&page=1
네이버 증권
NAVER 223,500 12,000 +5.67% 3,058,639 676,263 366,650
finance.naver.com
에서 상장 종목 상위 10개를 가져오자!
url = "https://finance.naver.com/sise/entryJongmok.naver?&page=1"
df_top10 = pd.read_html(url)[0].dropna()
df_top10
그 다음 FinanceDataReader를 통해 전체 상장종목에서 종목코드와 종목명만 가져와보자!
df_krx = fdr.StockListing('KRX')[['Name', 'Code']]
df_krx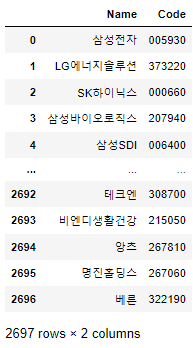
그 다음 앞에서 가져온 상위 10개 종목의 데이터프레임과 위의 데이터프레임을 merge를 통해 합쳐주고!
종목명과 종목코드 컬럼만 불러왔다!
df_10 = df_top10.merge(df_krx, left_on="종목별", right_on='Name')[['Name', 'Code']]
df_10
반복문을 사용해서 10개 종목의 종가를 2022년 부터 수집해보자!
# 반복문을 사용하여 여러 종목의 종가를 수집합니다.
item_list = [fdr.DataReader(code, start='2022')['Close'] for code in df_10['Code']]
item_list
이렇게 리스트 안에 10개 종목의 날짜별 종가 데이터가 들어가 있다!
이것을 하나의 데이터프레임으로 합치면...
# 수집한 리스트를 axis=1(컬럼)을 기준으로 병합(concat) 합니다.
df = pd.concat(item_list, axis=1)
df.columns = df_10['Name']
df
이렇게 잘 수집된다!
시각화 하기 전에 한글폰트 적용을 하고 스타일을 지정해준다!
import koreanize_matplotlib
# 그래프에 retina display 적용
%config InlineBackend.figure_format = 'retina'
import matplotlib.pyplot as plt
plt.style.use('ggplot')
여러 종목의 종가를 한번에 선그래프로 시각화해보자!
# 판다스의 plot을 통한 전체 데이터 프레임 시각화
df.plot(figsize=(10, 4), lw=0.5);
plt.legend(bbox_to_anchor=(1,1));
10개의 그래프가 있어 알아보기가 힘들다!
이번엔 삼성전자와 LG화학을 비교해 보자!
# 2개의 종목 비교하기 : "삼성전자", "LG화학" 을 plot으로 시각화 합니다.
df[['삼성전자', 'LG화학']].plot();
삼성전자의 1주 주식 가격이 싸서 잘 표현이 안된다!
그리하여 2축그래프를 사용해서 시각화해보자!
# secondary_y를 사용해 2축 그래프 그리기
df[['삼성전자', 'LG화학']].plot(figsize=(9,3),lw=0.5 , secondary_y='삼성전자');
아까 보다는 삼성전자의 변화를 잘 볼 수 있다!
이제 수익률을 시각화하기 위해 수익률을 구해보자!
# 첫번째 날 가격으로 나머지 가격을 나눠주고 -1을 해주면 수익률을 구할 수 있습니다.
df_norm = (df / df.iloc[0])-1
df_norm이렇게 수익률을 구하면...

수익률 데이터프레임이 나온다!
LG에너지솔루션이 첫날이 상장 전이기 때문에 LG에너지솔루션의 수익률만 따로 구해준다!
df_norm['LG에너지솔루션'] = df['LG에너지솔루션']/df.dropna()['LG에너지솔루션'].iloc[0]-1
df_norm
그다음 전체 수익률을 시각화해봤다!
수익률 0지점에는 빨간 점선도 그었다!
# matplotlib API
df_norm.plot(figsize=(10,3), rot=0, lw=0.5);
plt.legend(bbox_to_anchor=(1,1));
plt.axhline(0, c='r', ls=':');
마지막으로는 수익률에 대한 전체 종목의 히스토그램을 그려봤다!
# 수익률에 대한 히스토그램 그리기
df_norm.hist(bins=50, figsize=(10, 10));
이 그래프를 보고 왜도와 첨도를 시각적으로 볼 수 있는데...
실제 값으로 구해보자!
왜도 구해보기!
# skew 로 수익률의 왜도를 구합니다.
df.skew()
첨도 구해보기!
df.kurt()

세번째 데이터는 plotly라이브러리에 내장된 데이터였다!
일단 plotly import하자!
import plotly.express as px
plotly에 내장된 iris(붓꽃?)데이터를...
x축에 sepal_with
y축에 sepal_length
color에 petal_length로 설정한 뒤 산점도를 그려보자!
df = px.data.iris()
fig = px.scatter(df, x="sepal_width", y="sepal_length", color='petal_length')
fig.show()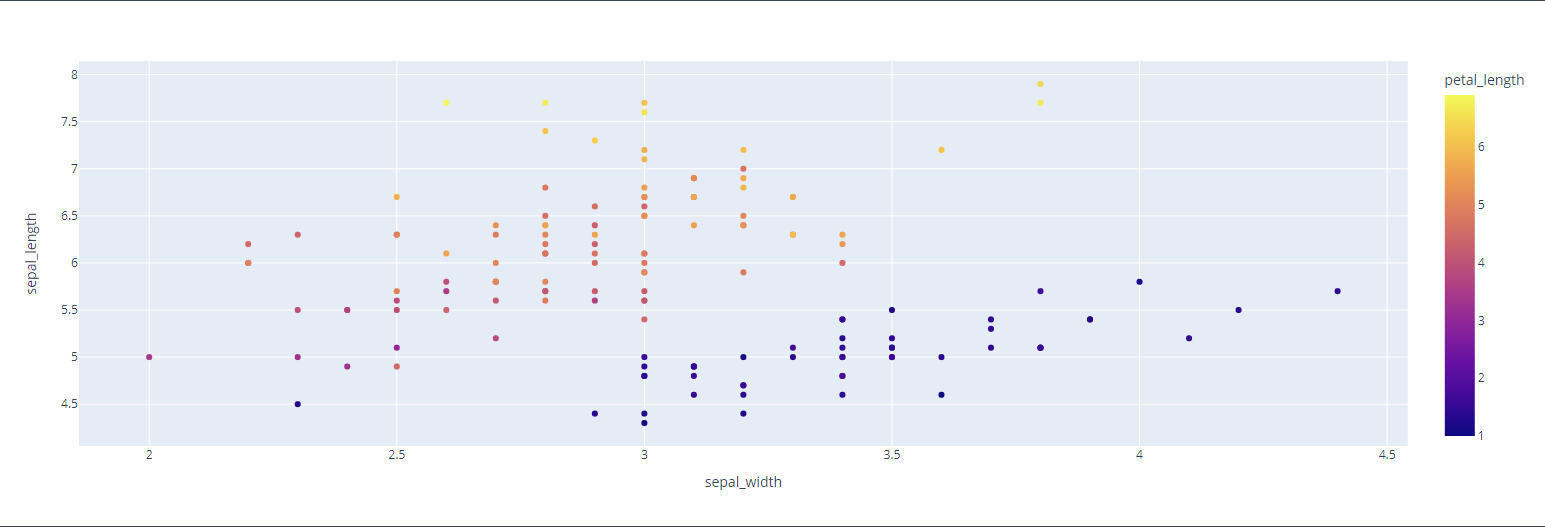
이쁜 형형색색의 산점도 완성!
이번엔 plotly 내장 데이터인 stocks로 시각화를 해보자!
# px 에서 내장하고 있는 data.stocks 데이터를 불러옵니다.
df = px.data.stocks()
df
6개 기업의 일별 수익률 데이터가 있다!
먼저 plotly의 선그래프로 구글의 그래프를 그려보면...
# px.line 으로 특정 종목("GOOG")에 대해 선그래프를 그립니다.
px.line(df, x='date', y='GOOG', height=300)
이렇다!
똑같은 그래프를 pandas API로 그려보면...
# pandas API
df['GOOG'].plot()
이렇고...
plotly express의 API로 그려보면
# plotly express API
px.line(df['GOOG'], height=300)
이렇다!
다음으로 일별 수익률값 기준을 0으로 해서 막대그래프로 그려보자!
# 일별 수익률에서 -1을 빼줍니다.
df_1 = df.set_index('date') - 1
df_1
이렇게 0을 기준으로 수익률값 데이터프레임을 만들었다!
pandas api로 막대그래프를 만들어보면...
# Pandas API
df_1.plot.bar(figsize=(12,3));
이렇다!
plotly express API로 만들어 보면...
plotly express API
# 수익률을 막대그래프로 그립니다.
px.bar(df_1, height=300)
이렇다!
plotly로 그린것이 보기가 편한 듯? 하다!
다음으로는 facet_col기능을 사용해 서브플롯을 그려보자!
facet_col에 넣을 company를 생성!
# df_1.columns 의 name을 "company"로 지정하기
df_1.columns.name = 'company'
df_1.columns
px.area로 서브플롯을 그려보면...
# px.area 로 수익률 분포를 그립니다.
# facet_col 을 통해 서브플롯을 그릴 수 있습니다.
px.area(df_1, facet_col='company', facet_col_wrap=2)
company 별로 서브플롯을 그릴 수 있다!
이번에는 rangeslider를 이용해 시계열 그래프를 그려보자!
fig = px.line(df_1['GOOG'], title='구글 주가')
fig.update_xaxes(rangeslider_visible=True)이렇게 그래프를 그려보면...
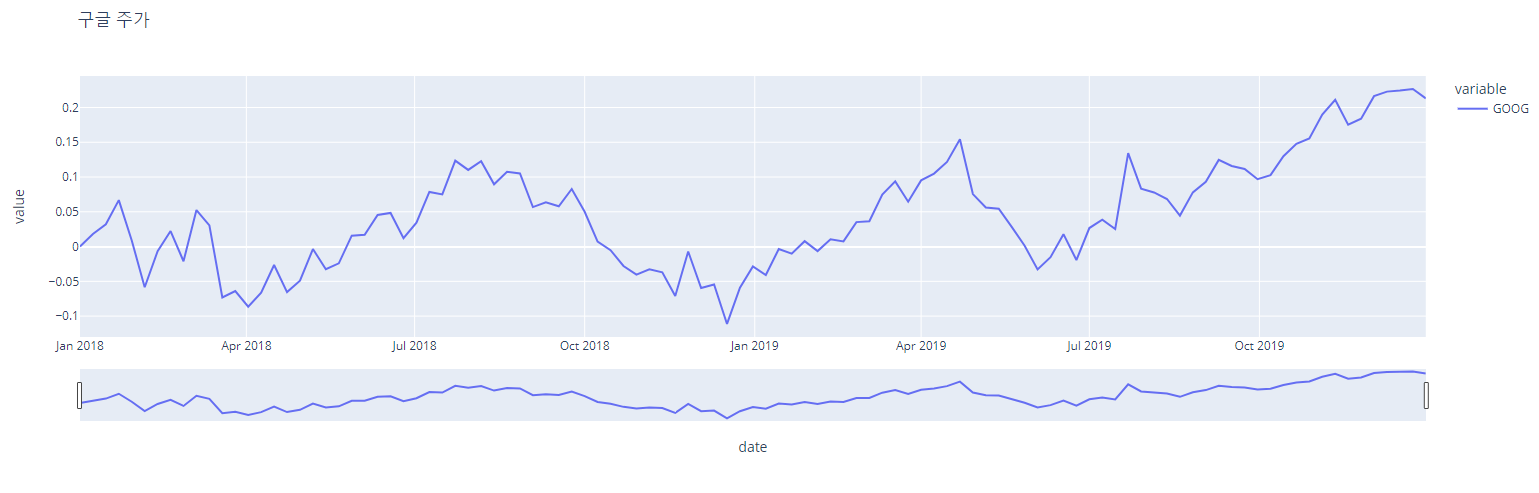
x축 밑부분에 시간 간격을 조절해 가면서 그래프를 확인 수 있는 rangeslider가 생성된다!
이번에는 캔들스틱 차트를 그려보자!

아미지 출처 : https://en.wikipedia.org/wiki/Candlestick_chart
캔들 스틱 차트는 위 그림과 같이 차트가 표현된다!
캔들스틱 차트를 그리기 위한 라이브러리를 import해주고...
데이터셋을 불러오자!
# plotly.graph_objects 를 go라는 별칭으로 불러옵니다.
# go.Candlestick 을 그립니다.
import pandas as pd
import plotly.graph_objects as go
from datetime import datetime
df = pd.read_csv('https://raw.githubusercontent.com/plotly/datasets/master/finance-charts-apple.csv')
df
주식의 시가, 고가, 저가, 종가 등을 담은 데이터이다!
이 데이터로 캔들스틱 차트를 그려보면...
fig = go.Figure(data=[go.Candlestick(x=df['Date'],
open=df['AAPL.Open'],
high=df['AAPL.High'],
low=df['AAPL.Low'],
close=df['AAPL.Close'])])
fig.show()
이렇게 그려지고...
날짜 간격을 좁혀보면...

캔들스틱 차트임을 확인할 수 있다!
다음으로 OLHC 차트를 그려보자!

이미지 출처 : https://datavizcatalogue.com/methods/OHLC_chart.html
ohlc차트는 위 그림곽 같이 그려진다!
아까의 데이터로 ohlc차트를 그려보면...
# go.Ohlc를 그립니다.
fig = go.Figure(data=[go.Ohlc(x=df['Date'],
open=df['AAPL.Open'],
high=df['AAPL.High'],
low=df['AAPL.Low'],
close=df['AAPL.Close'])])
fig.show()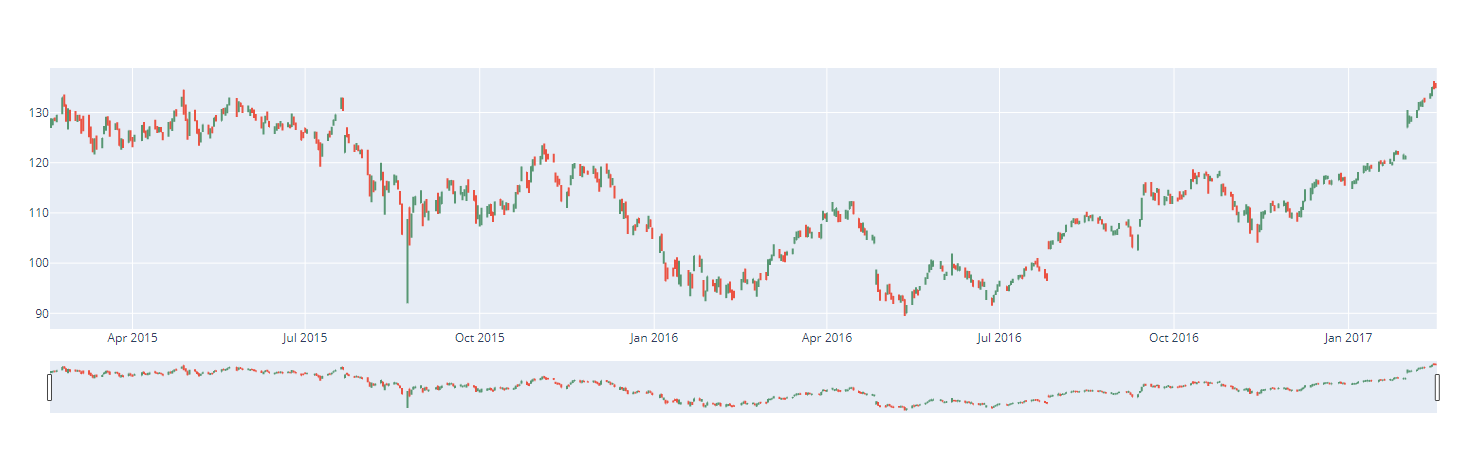
이렇고...
역시 시간간격을 좁혀보면...

영락없는 ohlc차트이다!
마지막으로 여러 종목의 수익률을 시각화 해보자!
여러 종목을 가져오기위해 FinanceDataReader를 import하고...
# FinanceDataReader 로드하기
import FinanceDataReader as fdr
유명 기업의 리스트를 만들어주자!
FAANG = ["META", "AMZN", "AAPL", "NFLX", "GOOGL"]
이제 FinanceDataReader을 통해 2022년부터의 종가만 가져와 list에 담아주자!
# faang_list 의 종가 가져오기
faang_list = [fdr.DataReader(faang, start='2022')['Close'] for faang in FAANG]
faang_list
이렇게 list에 5개 종목의 종가들이 담겨있다.
리스트를 병합하고 컬럼 이름을 지정해 주면...
# concat 으로 데이터 병합하기
df_faang = pd.concat(faang_list, axis=1)
df_faang.columns = FAANG
df_fanng
이 데이터 프레임에서 한 번 더 일 별 수익률을 계산하면...
# 일별 수익률 구하기
# df_ratio
df_ratio = (df_faang / df_faang.iloc[0])-1
df_ratio
시각화를 할 데이터프레임이 만들어졌다!
서브플롯을 만들기 위한 컬럼 이름도 지정해주고!
# 서브플롯을 그리기 위해 columns.name 을 설정하기
df_ratio.columns.name = "company"
df_ratio.columns.name
선그래프 그리기!
# px.line 으로 선 그래프 그리기
px.line(df_ratio, height=300)
areaplot 그리기!
# px.area 로 수익률 그래프 그리기
px.area(df_ratio, height=300)
areaplot을 서브플롯으로 그리기!
px.area(df_ratio, facet_col='company', facet_col_wrap=2)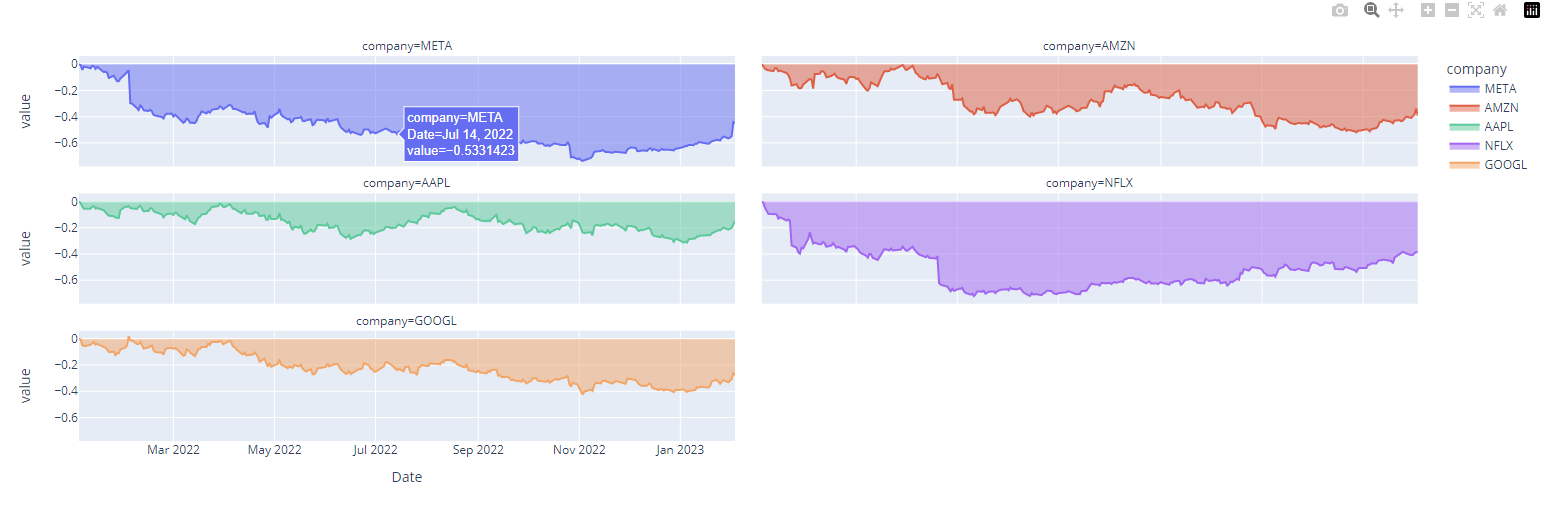
넷플릭스 수익률의 막대그리프 그리기!
px.bar(df_ratio['NFLX'])
메타와 아마존 수익률을 산점도로 그리기!
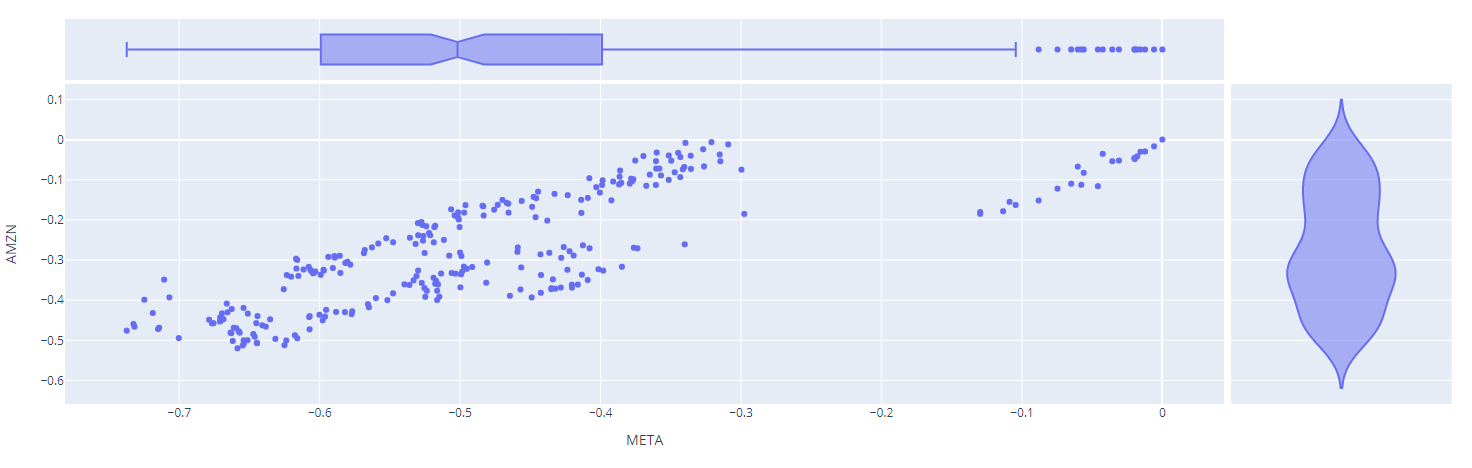
메타의 수익률 분포는 박스플롯, 아마존의 수익률분포는 바이올린플롯으로 추가해줬다!
px.scatter(df_ratio, x=df_ratio["META"], y=df_ratio["AMZN"], marginal_x='box', marginal_y='violin')
전체 기업의 산점도 행렬 그리기!
px.scatter_matrix(df_ratio)
전체 기업의 수익률 분포를 박스플롯으로 확인해보기!
# px.box
px.box(df_ratio)
px.strip으로도 그려보기!

수익률 분포를 히스토그램으로 그리기!
# px.histogram
px.histogram(df_ratio, marginal='box', nbins=50)
여기까지 그래프를 잔뜩 그려봤다...
이번주는 matplotlib과 plotly로만 시각화를 해봤는데...
다음주에 배울 시각화가 더 기대가 된다!

'멋쟁이사자처럼 AI스쿨' 카테고리의 다른 글
| 멋쟁이사자처럼 AI스쿨 8주차 회고 (0) | 2023.02.09 |
|---|---|
| 멋쟁이사자처럼miniproject2(행복지수와 코로나확진률) (0) | 2023.02.08 |
| 멋쟁이사자처럼 miniproject1(네이버 증권 웹사이트 정보 수집하기) (0) | 2023.02.02 |
| 멋쟁이사자처럼 miniproject1(스타벅스 매장 정보 수집하기) (0) | 2023.01.31 |
| 멋쟁이사자처럼 AI스쿨 5주차 회고 (0) | 2023.01.19 |




댓글