
미니프로젝트 2의 주제는 세계 행복 지수와 코로나 감염비율의 상관관계 파악!
(제대로 파악하지는 못했지만...)
일단 사용한 데이터는 이렇다...
세계 행복지수 2019, 2020, 2021데이터셋
World Happiness Report up to 2022
Bliss scored agreeing to financial, social, etc.
www.kaggle.com
코로나 나라별 일별 누적확진자 데이터
Novel COVID19 Dataset
Novel Corona Virus daily information.
www.kaggle.com
나라별 세계 인구수 데이터
https://www.kaggle.com/datasets/rsrishav/world-population?select=2021_population.csv%5D
2021 World Population (updated daily)
2021 World Population dataset which gets updated daily.
www.kaggle.com
흠... 일단 데이터를 파악해보자구!
일단 2019행복지수 데이터

흠...
2020데이터

흐으음...?

흐으으응...?
데이터 이해하기 위해 구글링 조지기!


출처 : https://apatronl.github.io/WorldHappiness/
일단 이것을 읽고 변수에 대해서는 적당히? 이해했다!
Residual는 이해가 안가서 또 구글링!

출처 : https://worldhappiness.report/faq/
아항 6개 주요 변수 조정해주는 것이구나!
또 데이터 이해를 위해서 본 참고 링크
https://worldhappiness.report/ed/2019/changing-world-happiness/
Changing World Happiness
The World Happiness Report is a publication of the Sustainable Development Solutions Network, powered by the Gallup World Poll data.
worldhappiness.report
https://worldhappiness.report/ed/2020/social-environments-for-world-happiness/
Social Environments for World Happiness
The World Happiness Report is a publication of the Sustainable Development Solutions Network, powered by the Gallup World Poll data.
worldhappiness.report
이 두개의 사이트에서 중요한 사실을 깨달아버린...
중요한 점!!!
을 살펴보면...
1. 해당 년도의 행복지수는 년도 초에 발표되기 때문에 사실 전년도의 행복지수
2. 2021년의 행복지수는 사실 2020년 데이터를 가지고 산출한 것
3. 2021년의 변수 값들도 2020년의 데이터
4. 2019, 2020년은 사실상 전년도의 데이터이기 때문에 코로나 영향이 없음
요정도! 알아버렸다!
이번엔 국가별 코로나 확진자셋

아하? 국가별로 날짜별로 누적 코로나 확진자가 나왔구나...
근데 몇몇 나라는 지역별로 나눠서 표기 했구나! 요정도?
국가별 2021년 데이터셋

오케이~ 국가별로 인구수가 나왔는데 2020년 인구를 사용해야겠구나? 요정도?
전처리 할 때 참고할 점
을 살펴보면...
1. 코로나 확진수/인구수를 통해 확진 비율을 구하기
2. 2021년의 행복지수 데이터에 2020년의 코로나 확진비율 추가하는 것이 좋은 방법
3. 따라서 2020년 12월 31일 까지 누적 코로나 확진수를 2020년 인구 데이터로 나눠주자
요정도!
전처리
그럼 오지게 육지게 전처리 레리꼬!
일단 필요라이브러리 호출!
import pandas as pd
import numpy as np
import koreanize_matplotlib
import matplotlib.pyplot as plt
import plotly.express as px
import seaborn as sns
from glob import glob
%config InlineBackend.figure_format = 'retina'
%matplotlib inline
저장된 파일 불러오고...
files = glob('data/20*.csv')
file_paths = sorted(files)
file_paths
총 5개 데이터셋을 어쩌구저쩌구해서 하나로 만들어볼거다!
df2019 = pd.read_csv(file_paths[4])
df2020 = pd.read_csv(file_paths[5])
df2021 = pd.read_csv(file_paths[6])
corona_confirmed = pd.read_csv('data/time_series_covid19_confirmed_global.csv')
population2021 = pd.read_csv('data/2021_population.csv')
행복지수 데이터 셋의 19년 20년 21년도 나라이름 표기도 다르고 나라 수도 다르다...
차집합으로 확인해보면...

너 좀 엉망이구나...
일단 나라이름 헷갈리는거는 구글을 통해 한가지로 정하자!

출처 : https://ko.wikipedia.org/wiki/%EB%B6%81%EB%A7%88%EC%BC%80%EB%8F%84%EB%8B%88%EC%95%84

출처 : https://ko.wikipedia.org/wiki/트리니다드_토바고
그럼 나라이름 표기 통합!
# Hong Kong, Hong Kong S.A.R. of China => Hong Kong
# North Macedonia, Macedonia => North Macedonia
# Northern Cyprus, North Cyprus => North Cyprus
# Taiwan, Taiwan Province of China => Taiwan
# Trinidad & Tobago, Trinidad and Tobago => Trinidad and Tobago
df2020.loc[df2020['Country name'] == 'Hong Kong S.A.R. of China', 'Country name'] = 'Hong Kong'
df2021.loc[df2021['Country name'] == 'Hong Kong S.A.R. of China', 'Country name'] = 'Hong Kong'
df2020.loc[df2020['Country name'] == 'Macedonia', 'Country name'] = 'North Macedonia'
df2020.loc[df2020['Country name'] == 'Macedonia', 'Country name'] = 'North Macedonia'
df2019.loc[df2019['Country or region'] == 'Northern Cyprus', 'Country or region'] = 'North Cyprus'
df2020.loc[df2020['Country name'] == 'Taiwan Province of China', 'Country name'] = 'Taiwan'
df2021.loc[df2021['Country name'] == 'Taiwan Province of China', 'Country name'] = 'Taiwan'
df2019.loc[df2019['Country or region'] == 'Trinidad & Tobago', 'Country or region'] = 'Trinidad and Tobago'
다시 차집합 확인하면...

너 아까보단 덜 엉망이구나!
2019년도 데이터에는 디스토피아 값이 없어서... 인터넷에서 찾아서 넣어줬다!
2019년 디스토피아 값은 1.88

출처 : https://worldhappiness.report/ed/2019/changing-world-happiness/
그럼 2019년 데이터 전처리...
디스토피아값 넣어주고... 잔차값도 구해주고... 등등
df2019 = df2019.drop('Overall rank', axis=1)
# Dystopia 컬럼 & residual 컬럼 생성!
df2019['Dystopia'] = 1.88
df2019['Residuals'] = (
df2019['Score']
-df2019['GDP per capita']
-df2019['Social support']
-df2019['Healthy life expectancy']
-df2019['Freedom to make life choices']
-df2019['Generosity']
-df2019['Perceptions of corruption']
-df2019['Dystopia']
)
# Country or region 컬럼이름 Country로 변경
df2019 = df2019.rename(columns = {'Country or region':'Country'})
비어있는 지역값 2020년도와 머지를 통해 채워주기!
# 머지를 통해 지역 찾기
df2019 = df2019.merge(df2020_country_region,
how='left',
left_on="Country",
right_on='Country name')
# 필요 컬럼만 추출
df2019 = df2019[[
'Country',
'Regional indicator',
'Score',
'GDP per capita',
'Social support',
'Healthy life expectancy',
'Freedom to make life choices',
'Generosity',
'Perceptions of corruption',
'Dystopia',
'Residuals'
]]
# Regional indicator 컬럼 Region으로 컬럼명 변경
df2019 = df2019.rename(columns={'Regional indicator':'Region'})
머지하고 생성된 결측값 확인해보면...

4개 밖에 없으니 직접 찾아서 채워주자!
# 카타르는 중동이니 Middle East and North Africa에 넣어주자
df2019.loc[df2019['Country'] == 'Qatar', 'Region'] = 'Middle East and North Africa'
# 부탄은 남아시아에 속한다!
df2019.loc[df2019['Country'] == 'Bhutan', 'Region'] = 'South Asia'
# 소말리아 사하라이남 아프리카에 속한다!
df2019.loc[df2019['Country'] == 'Somalia', 'Region'] = 'Sub-Saharan Africa'
# 시리아는 중동
df2019.loc[df2019['Country'] == 'Syria', 'Region'] = 'Middle East and North Africa'
마지막으로 Year컬럼 생성하고 컬럼 순서 정리!
# 마지막으로 year컬럼을 생성해주자!
# 구체적인 날짜가 아니라 그냥 데이터타입은 오브젝트로 함!
df2019['Year'] = '2019'
# 컬럼 순서 정리
df2019 = df2019[['Year',
'Country',
'Region',
'Score',
'GDP per capita',
'Social support',
'Healthy life expectancy',
'Freedom to make life choices',
'Generosity',
'Perceptions of corruption',
'Dystopia',
'Residuals'
]]info()도 확인해보고 데이터도 확인해보면...


깔끔..?
20년 데이터 전처리!
# Residuals컬럼 생성
df2020['Residuals'] = df2020['Dystopia + residual'] - df2020['Ladder score in Dystopia']
df2020 = df2020.iloc[:, [0, 1, 2, 12, 13, 14, 15, 16, 17, 18, 20]]
cols = ['Country',
'Region',
'Score',
'Dystopia',
'GDP per capita',
'Social support',
'Healthy life expectancy',
'Freedom to make life choices',
'Generosity',
'Perceptions of corruption',
'Residuals'
]
# 컬럼명 변경
df2020.columns = cols
# 수치 데이터 소수점 3자리까지 반올림(디스토피아는 이미 2자리)
df2020 = df2020.round(3)
# 디스토피아는 소수점 2자리까지 반올림
df2020['Dystopia'] = df2020['Dystopia'].round(2)
# 중복값 제거
df2020 = df2020.drop_duplicates()# 마지막으로 year컬럼을 생성해주자!
df2020['Year'] = '2020'
# 컬럼 순서 정리
df2020 = df2020[['Year',
'Country',
'Region',
'Score',
'GDP per capita',
'Social support',
'Healthy life expectancy',
'Freedom to make life choices',
'Generosity',
'Perceptions of corruption',
'Dystopia',
'Residuals'
]]
df2020
2019년과 똑같은 컬럼명을 가지고 있고 결측치도 없스무니다!
2021년도 마찬가지로 전처리!
# Residuals컬럼 생성
df2021['Residuals'] = df2021['Dystopia + residual'] - df2021['Ladder score in Dystopia']
df2021 = df2021.iloc[:, [0, 1, 2, 12, 13, 14, 15, 16, 17, 18, 20]]
cols = ['Country',
'Region',
'Score',
'Dystopia',
'GDP per capita',
'Social support',
'Healthy life expectancy',
'Freedom to make life choices',
'Generosity',
'Perceptions of corruption',
'Residuals'
]
# 컬럼명 변경
df2021.columns = cols
# 수치 데이터 소수점 3자리까지 반올림(디스토피아는 이미 2자리)
df2021 = df2021.round(3)
# 중복값 제거
df2021 = df2021.drop_duplicates()
# 마지막으로 year컬럼을 생성해주자!
df2021['Year'] = '2021'
# 컬럼 순서 정리
df2021 = df2021[['Year',
'Country',
'Region',
'Score',
'GDP per capita',
'Social support',
'Healthy life expectancy',
'Freedom to make life choices',
'Generosity',
'Perceptions of corruption',
'Dystopia',
'Residuals'
]]
예스!
이번엔 인구데이터와 코로나 확진자 수 데이터에서 확진비율을 구해보자!
코로나 확진 데이터에서 Country/Region과 12/31/20 컬럼만 뽑고 합치면...
corona_confirmed_country = corona_confirmed['Country/Region']
# 2020년 코로나 확진자수
corona_confirmed_count = corona_confirmed.loc[:, '12/31/20']
# 2020년 코로나 Country/Region별 누적 확진자수
corona_confirmed_2020 = pd.concat([corona_confirmed_country,
corona_confirmed_count
], axis=1)
corona_confirmed_2020 = corona_confirmed_2020.rename(columns={'12/31/20':'confirmed_num'})
corona_confirmed_2020
이렇게 나라와 2020년 12월 31일까지의 확진자가 나오는데...
corona_confirmed_2020['Country/Region'].value_counts()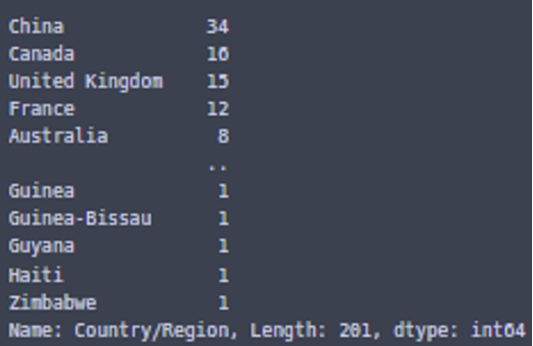
총 8개의 나라가 지역별로 확진자를 체크했다!!!
그래서 합쳐줘야한다...
# 여러개로 분리 된 나라 확진자수를 더해서 변수에 저장
# China확진자수
china_confirmed = corona_confirmed_2020[corona_confirmed_2020['Country/Region'] == 'China']['confirmed_num'].sum()
china_confirmed
# Canada확진자수
canada_confirmed = corona_confirmed_2020[corona_confirmed_2020['Country/Region'] == 'Canada']['confirmed_num'].sum()
canada_confirmed
# United Kingdom확진자수
united_kingdom_confirmed = corona_confirmed_2020[corona_confirmed_2020['Country/Region'] == 'United Kingdom']['confirmed_num'].sum()
united_kingdom_confirmed
# France확진자수
france_confirmed = corona_confirmed_2020[corona_confirmed_2020['Country/Region'] == 'France']['confirmed_num'].sum()
france_confirmed
# Australia확진자수
australia_confirmed = corona_confirmed_2020[corona_confirmed_2020['Country/Region'] == 'Australia']['confirmed_num'].sum()
australia_confirmed
# Netherlands확진자수
netherlands_confirmed = corona_confirmed_2020[corona_confirmed_2020['Country/Region'] == 'Netherlands']['confirmed_num'].sum()
netherlands_confirmed
# Denmark확진자수
denmark_confirmed = corona_confirmed_2020[corona_confirmed_2020['Country/Region'] == 'Denmark']['confirmed_num'].sum()
denmark_confirmed
# New Zealand확진자수
new_zealand_confirmed = corona_confirmed_2020[corona_confirmed_2020['Country/Region'] == 'New Zealand']['confirmed_num'].sum()
new_zealand_confirmed이렇게 확진자수를 따로 저장해주고...
나라 이름으로 중복제거를 하고!
corona_confirmed_2020 = corona_confirmed_2020.drop_duplicates('Country/Region').reset_index(drop=True)
앞에서 구한 확진자수를 다시 넣어준다!
# China확진자수 변경
corona_confirmed_2020.loc[corona_confirmed_2020['Country/Region'] == 'China', 'confirmed_num'] = china_confirmed
# Canada확진자수 변경
corona_confirmed_2020.loc[corona_confirmed_2020['Country/Region'] == 'Canada', 'confirmed_num'] = canada_confirmed
# United Kingdom확진자수 변경
corona_confirmed_2020.loc[corona_confirmed_2020['Country/Region'] == 'United Kingdom', 'confirmed_num'] = united_kingdom_confirmed
# France확진자수 변경
corona_confirmed_2020.loc[corona_confirmed_2020['Country/Region'] == 'France', 'confirmed_num'] = france_confirmed
# Australia확진자수 변경
corona_confirmed_2020.loc[corona_confirmed_2020['Country/Region'] == 'Australia', 'confirmed_num'] = australia_confirmed
# Netherlands확진자수 변경
corona_confirmed_2020.loc[corona_confirmed_2020['Country/Region'] == 'Netherlands', 'confirmed_num'] = netherlands_confirmed
# Denmark확진자수 변경
corona_confirmed_2020.loc[corona_confirmed_2020['Country/Region'] == 'Denmark', 'confirmed_num'] = denmark_confirmed
# New Zealand확진자수 변경
corona_confirmed_2020.loc[corona_confirmed_2020['Country/Region'] == 'New Zealand', 'confirmed_num'] = new_zealand_confirmed
그리하여 일단 만든 데이터다...

이제 인구수 데이터를 보자!
인구수 데이터에서 나라와 2020년의 인구를 가져오자!
# 2020년도 마지막 인구수 가져오기
population2020 = population2021.loc[:, ['country', '2020_population']]
# 인구수 정수형으로 바꾸기
population2020['2020_population'] = population2020['2020_population'].replace(',', '', regex=True).astype(int)
# 중복되는 나라가 없음
population2020
이제 두데이터를 나라 이름 기준으로 이너조인할껀디...
그 전에 나라이름 통합하자!
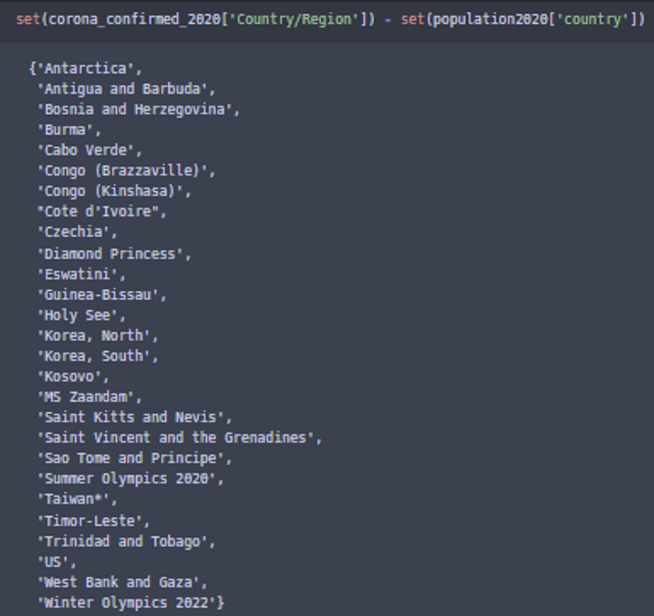

차집합 확인해서 나라이름 표기가 다른것을 통합!
# 나라이름 통합 하기
# 나라 이름 공통으로 통일!
# Antigua and Barbuda, Antigua And Barbuda => Antigua and Barbuda
population2020.loc[population2020['country'] == 'Antigua And Barbuda', 'country'] = 'Antigua and Barbuda'
# Bosnia and Herzegovina, Bosnia And Herzegovina => Bosnia and Herzegovina
population2020.loc[population2020['country'] == 'Bosnia And Herzegovina', 'country'] = 'Bosnia and Herzegovina'
# Cabo Verde, Cape Verde => Cape Verde
corona_confirmed_2020.loc[corona_confirmed_2020['Country/Region'] == 'Cabo Verde', 'Country/Region'] = 'Cape Verde'
# Czechia, Czech Republic => Czech Republic
corona_confirmed_2020.loc[corona_confirmed_2020['Country/Region'] == 'Czechia', 'Country/Region'] = 'Czech Republic'
# Guinea-Bissau, Guinea Bissau => Guinea Bissau
corona_confirmed_2020.loc[corona_confirmed_2020['Country/Region'] == 'Guinea-Bissau', 'Country/Region'] = 'Guinea Bissau'
# Korea, South, South Korea => South Korea
corona_confirmed_2020.loc[corona_confirmed_2020['Country/Region'] == 'Korea, South', 'Country/Region'] = 'South Korea'
# Korea, North, North Korea => North Korea
corona_confirmed_2020.loc[corona_confirmed_2020['Country/Region'] == 'Korea, North', 'Country/Region'] = 'North Korea'
# Saint Kitts and Nevis, Saint Kitts And Nevis => Saint Kitts and Nevis
population2020.loc[population2020['country'] == 'Saint Kitts And Nevis', 'country'] = 'Saint Kitts and Nevis'
# Sao Tome and Principe, Sao Tome And Principe => Sao Tome and Principe
population2020.loc[population2020['country'] == 'Sao Tome And Principe', 'country'] = 'Sao Tome and Principe'
# Taiwan*, Taiwan = > Taiwan
corona_confirmed_2020.loc[corona_confirmed_2020['Country/Region'] == 'Taiwan*', 'Country/Region'] = 'Taiwan'
# Trinidad and Tobago, Trinidad And Tobago => Trinidad and Tobago
population2020.loc[population2020['country'] == 'Trinidad And Tobago', 'country'] = 'Trinidad and Tobago'
# US, United States => United States
corona_confirmed_2020.loc[corona_confirmed_2020['Country/Region'] == 'US', 'Country/Region'] = 'United States'
이제 겹치는 거 없는지 확인!

겹치는 거 없는 듯?
그럼 inner join(어차피 값이 하나라도 없으면 계산 못함)으로 데이터 합치고 확진비율 구하기 해보자!
# 확진비율 구하기
df_for_corona = corona_confirmed_2020.merge(population2020,
left_on='Country/Region',
right_on='country')
df_for_corona = df_for_corona[['country', 'confirmed_num', '2020_population']]
df_for_corona['confirmed ratio'] = df_for_corona['confirmed_num']/df_for_corona['2020_population']
이제 확진비율만 남기자...
# 확진비율 구하기
df_for_corona = corona_confirmed_2020.merge(population2020,
left_on='Country/Region',
right_on='country')
df_for_corona = df_for_corona[['country', 'confirmed_num', '2020_population']]
df_for_corona['confirmed ratio'] = df_for_corona['confirmed_num']/df_for_corona['2020_population']
이제 21년도 데이터와 left조인 갈겨버리자!
Q. 왜?? 20년도를 21년도 데이터와 합치는가???
A. 21년도 세계 행복 지수는 20년도와 그 이전 몇 개 연도 데이터를 가지고 산출하기 때문에
# 21년도 데이터와 합쳐주기
df2021 = df2021.merge(df_for_corona,
how='left',
left_on="Country",
right_on='country')
# Country컬럼 하나만 남기기...
df2021= df2021.drop('country', axis=1)조인후 info를 보면...
df2021.info()
확진률 결측치 9개이다!
이것을 평균으로 대체하자!
# 결측치를 confirmed_ratio평균으로 대체
df2021.loc[df2021['confirmed ratio'].isna(), 'confirmed ratio'] = df2021['confirmed ratio'].mean()
df2021.info()
결측치 없당!
이제 2019, 2020, 2021 3개년 concat으로 합쳐 최종 데이터 구해보자!
# 최종 데이터 만들기
df = pd.concat([df2019, df2020, df2021]).reset_index(drop=True)
# 2019, 2020 확진률 0
df = df.fillna(0)Q. 왜?? 19년과 20년은 확진비율 0으로 처리했는가
A. 위에 21년도와 마찬가지로 19년 행복지수는 이전~18년도까지의 데이터를 종합한 점수이고,
20년도는 이전 ~ 19년 까지의 행복지수 데이터를 종합한 것이기 때문에 19와 20년도는 확진비율을 0으로 설정
최종 데이터 완성!

info확인!
df.info()
수치형 데이터 기술통계!

범주형 데이터 기술통계!

확인 요정도~!
다른 조원분들도 재미있고 다양한 시각화를 많이 해주셨지만...
나는 간단한? 주제 5가지 정도 시각화 해봤다!
시각화 주제1
수치형 변수들에 대한 연도별 평균값을 matplotlib, plotly, seaborn으로 각각 그려보기
일단 연도별 각 변수 평균을 보자!
# 연도별로 각 변수들의 평균보기
df_mean = df.groupby('Year').mean()
df_mean
그럼 matplotlib으로 그려보자!
# matplotlib으로 그려보기
plt.style.use('ggplot')
graph_mean1 = df_mean.plot.bar(figsize=(10, 5), rot=0);
graph_mean1;
plt.legend(bbox_to_anchor=(1,1));
보기 나름? 괜찮다?
plotly로 그려보자!
# plotly로 그려보기
graph_mean2 = px.bar(df_mean)
graph_mean2
보기 좀 어려운듯?
seaborn로 그려보자!
# seaborn으로 그려보기
graph_mean3 = sns.barplot(data=df_mean, ci=None)
plt.rcParams['figure.figsize'] = [10, 5]
plt.xticks(rotation=30);
3개년 평균값이 나오는듯...
요정도?
시각화 주제2
행복점수와 가장 큰 상관관계에 있는 변수를 찾고 행복점수와 그 변수간 관계를 시각화
일단 상관관계 구해보자!
# 각 변수와 행복점수의 상관계수 구해보기
cc_gdp_per_capita = np.corrcoef(df['Score'], df['GDP per capita'])[0,1]
cc_social_support = np.corrcoef(df['Score'], df['Social support'])[0,1]
cc_healthy_life_expectancy = np.corrcoef(df['Score'], df['Healthy life expectancy'])[0,1]
cc_freedom_to_make_life_choices = np.corrcoef(df['Score'], df['Freedom to make life choices'])[0,1]
cc_generosity = np.corrcoef(df['Score'], df['Generosity'])[0,1]
cc_perceptions_of_corruption = np.corrcoef(df['Score'], df['Perceptions of corruption'])[0,1]
cc_dystopia = np.corrcoef(df['Score'], df['Dystopia'])[0,1]
cc_residuals = np.corrcoef(df['Score'], df['Residuals'])[0,1]
# 확진비율은 2021년에만 있어서 이렇게 했다
cc_confirmed_ratio = np.corrcoef(df2021['Score'], df2021['confirmed ratio'])[0,1]
# 상관계수 확인
print(cc_gdp_per_capita)
print(cc_social_support)
print(cc_healthy_life_expectancy)
print(cc_freedom_to_make_life_choices)
print(cc_generosity)
print(cc_perceptions_of_corruption)
print(cc_dystopia)
print(cc_residuals)
print(cc_confirmed_ratio)
# 1인당 gdp가 가장 행복점수랑 가장 큰 상관관계가 있다!
1인당 gdp가 가장 높네?..
역시 돈으로 행복을 사는건가...?
그럼 seaborn의 lmplot(그림수준 함수)으로 1인당 gdp와 행복지수의 산점도를 hue를 연도로 그려보자!
# seaborn의 lmplot으로 시각화
# hue를 연도별로 지정해서 연도별 상관관계도 볼 수 있게 했다
sns.lmplot(data=df, x="GDP per capita", y="Score", hue="Year");
이번엔 col을 연도로해서 그려봤다!
# 연도별로 나눠서 seaborn의 lmplot으로 시각화
# 연도별 데이터가 거의 비슷한 것을 볼 수 있다
sns.lmplot(data=df, x="GDP per capita", y="Score", col='Year', hue="Year");
분포가 거의 비슷한듯?
이번에는 역시 그림수준 함수인 relplot으로도 그려봄!
# seaborn의 relplot으로 시각화
sns.relplot(
data=df,
x="GDP per capita", y="Score",
hue="Year", style="Year"
);
# 연도별로 나눠서 seaborn의 relplot으로 시각화
sns.relplot(
data=df,
x="GDP per capita", y="Score", col='Year',
hue='Year'
);
요정~ ~도!
시각화 주제3
2021년 social support, heathy life expectancy의 평균값이 다른 년도 보다 많이 낮아진 것을 확인! 코로나와 확진과 관련이 있는지 확인해보기 위해 social support, heathy life expectancy와 확진비율의 회기 모형 그려보기?
일단 연도별 평균값을 확인해보면...
# Social Support, Healthy life expectancy값이 차이가 크다!
df_mean = df.groupby('Year').mean()
df_mean
2021년도의 Social support, Healthy life expectancy값이 다른년도보다 좀 많이 낮다!
일단 확진비율과 Social support간의 관계를 lmplot으로 시각화해보자!
# Confirmed ratio와 Social support
sns.lmplot(data=df, x='confirmed ratio', y='Social support',
line_kws={'color':'red','linestyle':'--' }); # 직선 스타일 변경
음... 약한 음의 상관관계?
확진비율과 healty life expectancy
# Confirmed ratio와 Healthy life expectancy
sns.lmplot(data=df, x='confirmed ratio', y='Healthy life expectancy',
line_kws={'color':'red','linestyle':'--' },## 직선 스타일 변경
scatter_kws={'color':'green'}); # 점 색상 변경
관계가 없는 수준...?
분석은 요정도!
시각화 주제4
catplot으로 대륙별, 연도별(3개년이라 카테고리 형) GDP per capita, Social support, Healthy life expectancy, Freedom to make life choices, Generosity, Perceptions of corruption 6개 변수 분포 알아보기
먼저 GDP per capita
# GDP per capita
score_by_region = sns.catplot(data=df, x="Region", y="GDP per capita",
hue="Year");
score_by_region.fig.set_size_inches(12, 5);
plt.xticks(rotation=30);
유럽쪽이 gdp가 높네 ㅎㄷㄷ
사회적 서포트!
# 사회적 서포트
score_by_region = sns.catplot(data=df, x="Region", y="Social support",
hue="Year", palette='Set1');
score_by_region.fig.set_size_inches(12, 5);
plt.xticks(rotation=30);
유럽 너가짱해라!
Healthy life expectancy!
# Healthy life expectancy
score_by_region = sns.catplot(data=df, x="Region", y="Healthy life expectancy",
hue="Year", palette='Set2');
score_by_region.fig.set_size_inches(12, 5);
plt.xticks(rotation=30);
유럽이 전체적으로 건강하구먼...
근디 아시아에 장수나라가 있나 몇 나라가 건강하구먼!
Freedom to make life choices!
# Freedom to make life choices
score_by_region = sns.catplot(data=df, x="Region", y="Freedom to make life choices",
hue="Year", palette='Set3');
score_by_region.fig.set_size_inches(12, 5);
plt.xticks(rotation=30);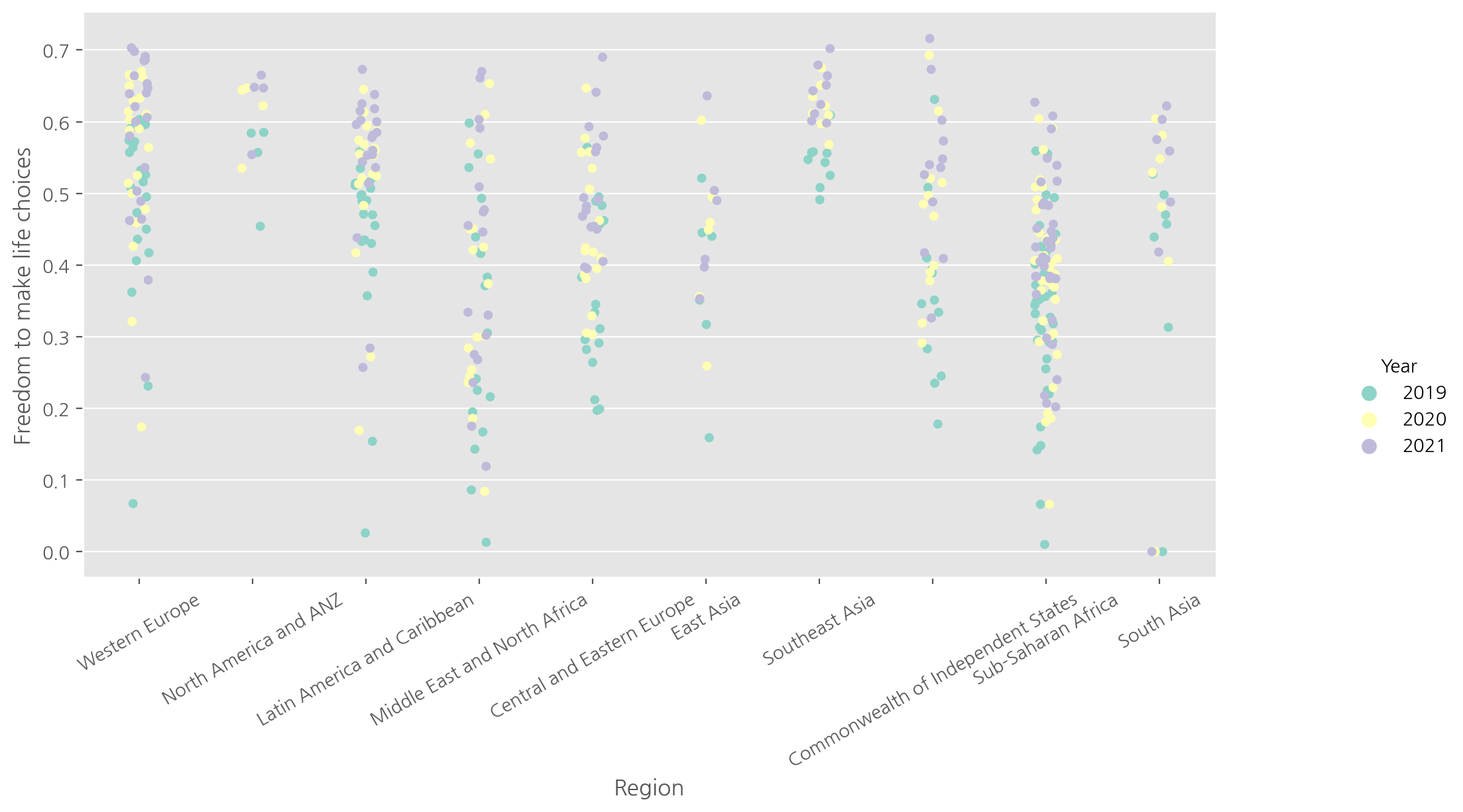
동남 아시아가 자유가 높네? ㅎㄷㄷ 프리덤!!!!
Generosity!
# Generosity
score_by_region = sns.catplot(data=df, x="Region", y="Generosity",
hue="Year");
score_by_region.fig.set_size_inches(12, 5);
plt.xticks(rotation=30);
지리게 관대한 나라가 동남아시아에 몇개 있네 ㅎㄷㄷ
마지막으로 Perceptions of corruption!
# Perceptions of corruption
score_by_region = sns.catplot(data=df, x="Region", y="Perceptions of corruption",
hue="Year", palette='Set1');
score_by_region.fig.set_size_inches(12, 5);
plt.xticks(rotation=30);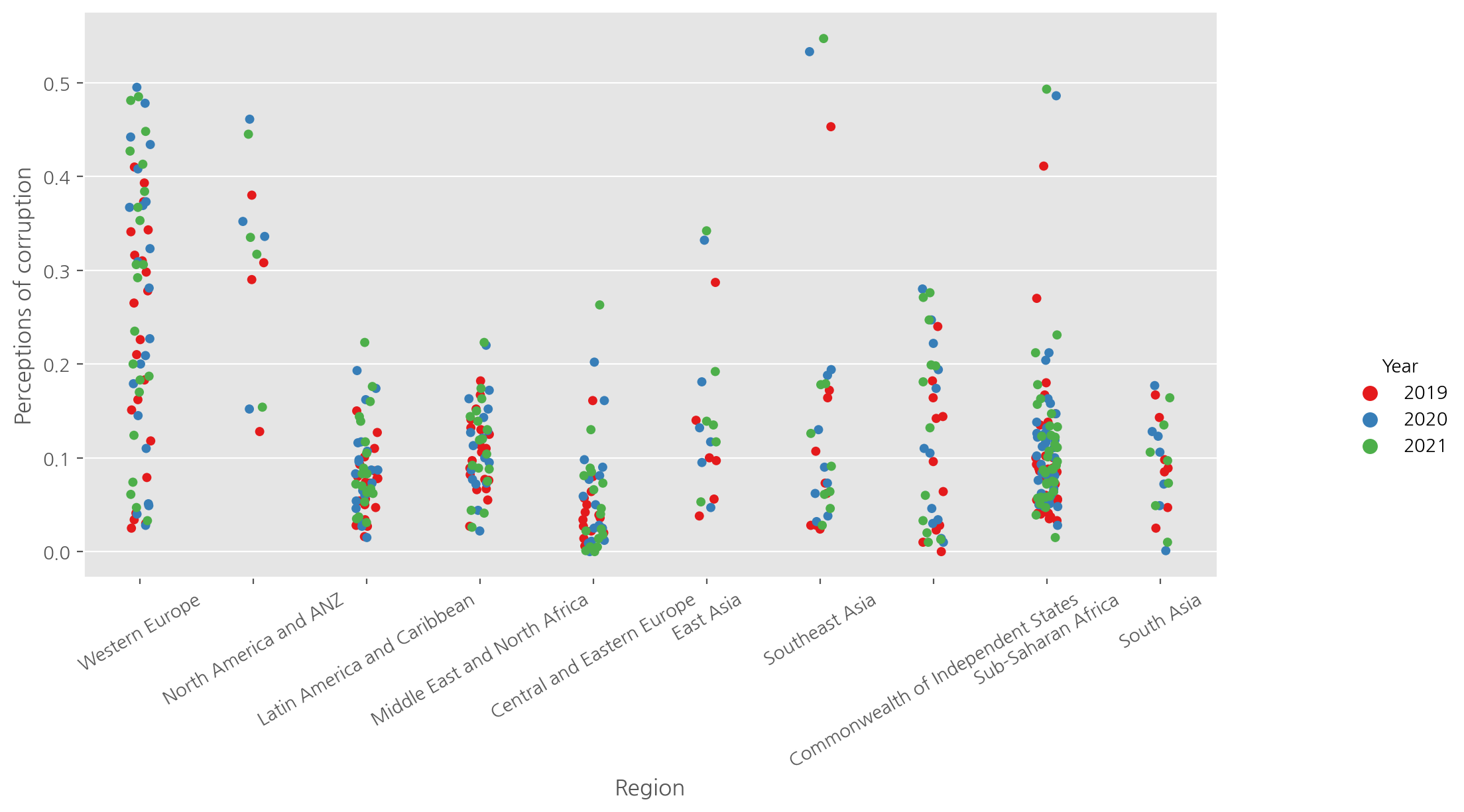
남아메리카랑 사하라사막이남 아푸리카가 부패가 심한듯?
요정도!
시각화 주제5
수치형 변수 히스토그램 subplot으로 그리기
matplotlib으로 그려보자!
# matplotlib으로 그려보기
fig, axs = plt.subplots(ncols=2, nrows=5, figsize=(10, 15),
gridspec_kw={'wspace':0.1},
constrained_layout=True)
for ax, col in zip(axs.flat, df.columns[3:13]):
ax.hist(x=df[col], bins=30)
ax.axvline(df[col].mean(), c='b', ls=':'); # 평균을 파란 점선으로 표현
ax.set_xlabel(col)
ax.set_ylabel('빈도수')
ax.set_title(col + ' histogram')
fig.suptitle('수치형 변수 히스토그램');
분포가 이렇군...
plotly로도 그려보면...
df_num = df.iloc[:, 3:13]
df_num.columns.name = '변수'
px.histogram(df_num, facet_col='변수', facet_col_wrap=5)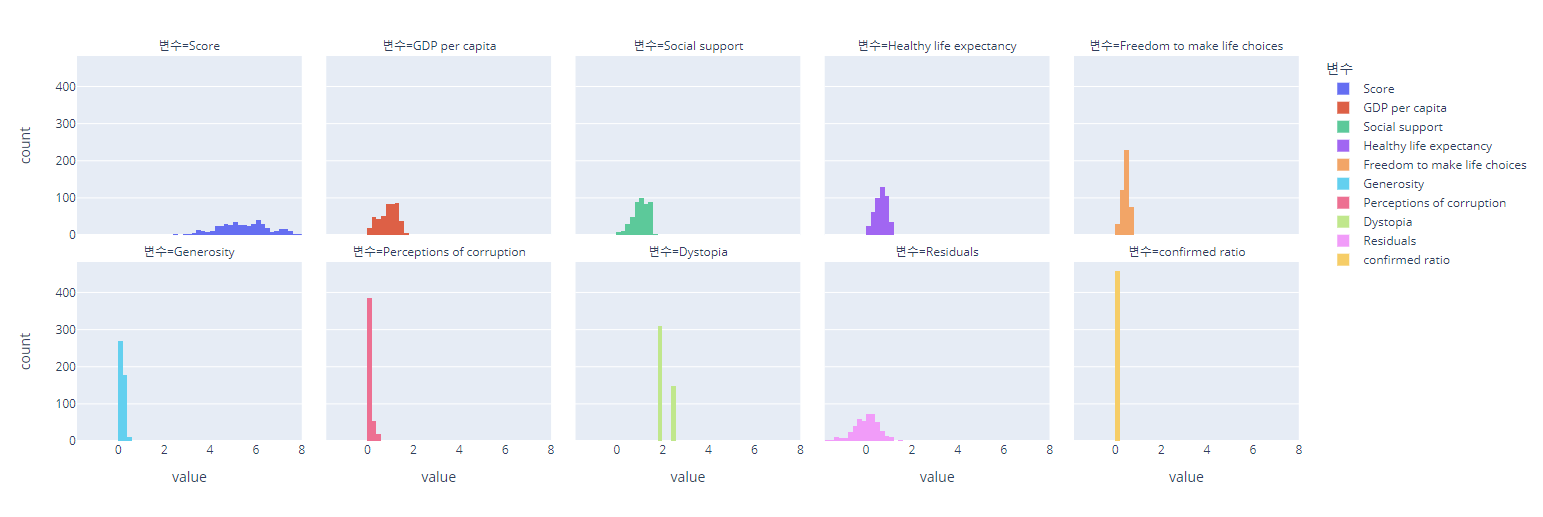
이렇게 그려봤다!
이번 프로젝트에서 내가 한건... 요정~도!
뭔가 코로나 데이터가 1개년 밖에 없어서... 코로나와 관련된 인사이트를 도출 못한듯싶다...
걍 5개년 정도로 해보자고 강력하게 주장할 걸...? 그랬나? ㅋㅋㅋㅋ
암튼 요정~!도 해봤다...
'멋쟁이사자처럼 AI스쿨' 카테고리의 다른 글
| 통계 특강1 (0) | 2023.02.16 |
|---|---|
| 멋쟁이사자처럼 AI스쿨 8주차 회고 (0) | 2023.02.09 |
| 멋쟁이사자처럼 AI스쿨 7주차 회고 (0) | 2023.02.02 |
| 멋쟁이사자처럼 miniproject1(네이버 증권 웹사이트 정보 수집하기) (0) | 2023.02.02 |
| 멋쟁이사자처럼 miniproject1(스타벅스 매장 정보 수집하기) (0) | 2023.01.31 |




댓글