두번째 주제는 네이버 증권 웹사이트 정보 수집하기로 정했다..
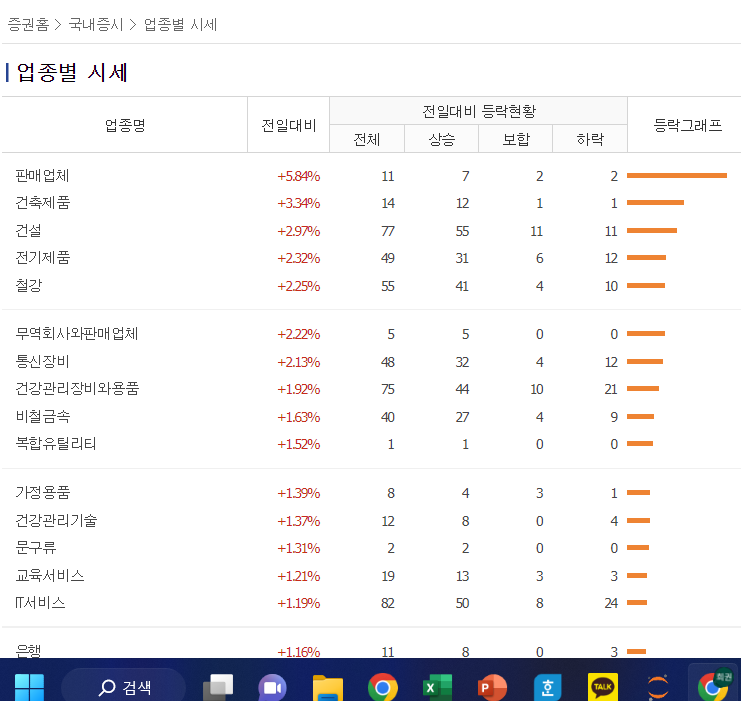
해당 페이지 : https://finance.naver.com/sise/sise_group.naver?type=upjong
테마별 시세 : 네이버 증권
관심종목의 실시간 주가를 가장 빠르게 확인하는 곳
finance.naver.com
일단 업종별 시세 페이지를 수집한 다음.. 링크를 타고 세부적인 내용을 긁어오기로 했다!
업종별 시세 페이지 수집 함수 코드이다!
링크를 타고 들어가야해서 업종번호도 파생변수로 넣어줬다!
# 업종별 시세 페이지 수집 함수
import pandas as pd
import requests
from bs4 import BeautifulSoup as bs
from datetime import datetime
def get_page_sise_by_upjong():
'''
업종별 시세 페이지를 스크래핑하는 함수
'''
url = 'https://finance.naver.com/sise/sise_group.naver?type=upjong'
response = requests.get(url)
df = pd.read_html(response.text)[0]
df = df.dropna()
df = df.reset_index(drop=True)
cols = ['업종명', '전일대비', '전체', '상승', '보합', '하락', '등락그래프']
df.columns = cols
df = df.drop('등락그래프', axis=1)
df[['전체', '상승', '보합', '하락']] = df[['전체', '상승', '보합', '하락']].astype(int)
html = bs(response.text)
upjong_no = [link['href'].split('&')[-1].replace('no=','') for link in html.select('td > a')[:-5]]
df['업종번호'] = upjong_no
today_date = datetime.today().strftime('%Y-%m-%d')
file_name = f'업종별시세-{today_date}.csv'
df.to_csv(f'data/{file_name}', encoding='utf-8-sig', index=False)
df = pd.read_csv(f'data/{file_name}', dtype={'업종번호':object})
return df# 함수 확인
df = get_page_sise_by_upjong()
df함수를 호출해 보면...
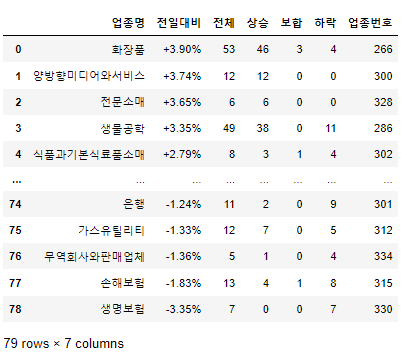
총 79개의 업종이 있다!
이번엔 업종별로 세부 기업들의 정보를 수집하기로 했다!
업종 번호를 통한 업종별 기업 정보 수집 함수이다!
업종명이 컬럼에 있어야 보기 편하기 때문에 파생변수로 넣어줬다!
def get_detail(upjong_num):
'''
업종별 시세 페이지의 업종별 기업 주식 정보 얻기
1) 업종번호를 통한 sub_url 만들기
2) requests 로 요청 보내기
3) 태이블 태그로 데이터를 수집해 뒤에서 첫번째 데이터 프레임 찾기
4) 결측치 제거
5) 업종명을 표시하기 위해 업종명 컬럼 추가
6) 인덱스 리셋
7) 컬럼 순서 정리
8) 컬럼 타입 정리
9) 업종번호가 없을시 오류처리
'''
try:
url_for_detail = 'https://finance.naver.com/sise/sise_group_detail.naver?type=upjong'
sub_url = f'{url_for_detail}&no={upjong_num}'
response_detail = requests.get(sub_url)
df_detail = pd.read_html(response_detail.text)[-1]
df_detail = df_detail.dropna(how='all', axis=1)
df_detail = df_detail.dropna(how='all')
df_detail['업종명'] = df[df['업종번호'] == upjong_num]['업종명'].iloc[0]
df_detail = df_detail.reset_index(drop=True)
cols = [
'업종명', '종목명', '현재가', '전일비',
'등락률', '거래량', '거래대금' ,'전일거래량',
'매수호가', '매도호가'
]
df_detail = df_detail[cols]
cols_int = ['현재가', '전일비', '거래량', '거래대금', '전일거래량', '매수호가', '매도호가']
df_detail[cols_int] = df_detail[cols_int].astype(int)
return df_detail
except Exception as e:
print(f'없는 업종번호입니다! {e}')# 함수 확인
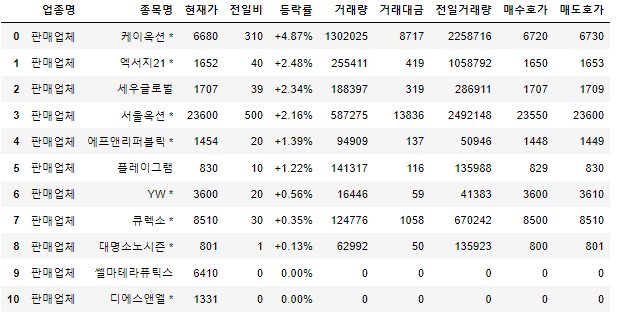
df_265 = get_detail('265')
df_265아래와 같이 판매업체 업종 내에는 11개의 기업이 있다!
한 번 모든 업종의 세부기업을 확인해봤다!
# 업종별 페이지 모든 디테일 데이터 얻기
from tqdm.notebook import tqdm
tqdm.pandas()
df_details = df['업종번호'].progress_map(get_detail)
df_details = pd.concat(df_details.tolist(), ignore_index=True)
df_details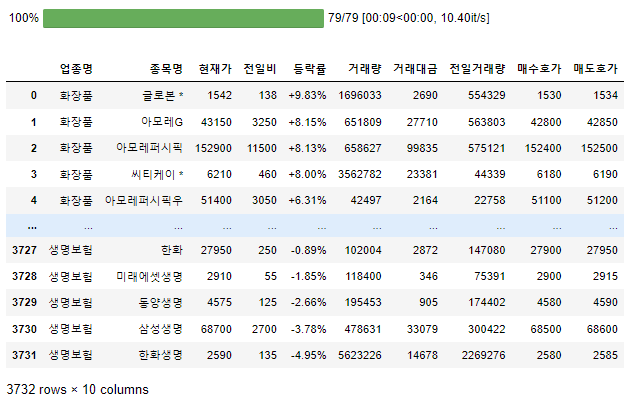
총 3732개의 기업이 있고 info를 확인해보면...
df_details.info()
display(df_details.describe(include='O'))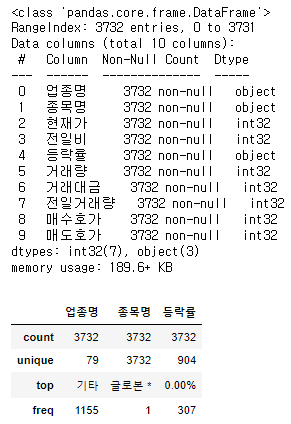
겹치는 기업 없이 업종별로 잘 분류되어 있다!
이번에는 업종별 기업 데이터를 원하는 대로 뽑을 수 있게 클래스로 만들어봤다!
import pandas as pd
import requests
import numpy as np
from bs4 import BeautifulSoup as bs
from datetime import datetime
import matplotlib.pyplot as plt
plt.rcParams['font.family'] ='Malgun Gothic'
class Upjong:
def __init__(self, upjong_nm, upjong_num):
self.upjong_nm = upjong_nm
self.upjong_num = upjong_num
def get_page_sise_by_upjong(self):
'''
업종별 시세 페이지를 스크래핑하는 함수
'''
url = 'https://finance.naver.com/sise/sise_group.naver?type=upjong'
response = requests.get(url)
df = pd.read_html(response.text)[0]
df = df.dropna()
df = df.reset_index(drop=True)
cols = ['업종명', '전일대비', '전체', '상승', '보합', '하락', '등락그래프']
df.columns = cols
df = df.drop('등락그래프', axis=1)
df[['전체', '상승', '보합', '하락']] = df[['전체', '상승', '보합', '하락']].astype(int)
html = bs(response.text)
upjong_no = [link['href'].split('&')[-1].replace('no=','') for link in html.select('td > a')[:-5]]
df['업종번호'] = upjong_no
today_date = datetime.today().strftime('%Y-%m-%d')
file_name = f'업종별시세-{today_date}.csv'
df.to_csv(f'data/{file_name}', index=False)
df = pd.read_csv(f'data/{file_name}', dtype={'업종번호':object})
return df
def rank_upjong(self):
right_now = datetime.today().strftime('%Y-%m-%d %X')
sise_by_upjong = Upjong.get_page_sise_by_upjong(self)
total_upjong = sise_by_upjong.shape[0]
today_rank = sise_by_upjong[sise_by_upjong['업종명'] == self.upjong_nm].index[0] + 1
print(f'{self.upjong_nm}의 {right_now} 현재 전일대비 등락률 순위는 {total_upjong}종목중 {today_rank}위 입니다!')
def get_summary(self):
right_now = datetime.today().strftime('%Y-%m-%d %X')
before_summary = Upjong.get_page_sise_by_upjong(self)
summary = before_summary[before_summary['업종명'] == self.upjong_nm]
print(f'{right_now} 현재 {self.upjong_nm} 업종의 요약정보입니다!')
plt.figure(figsize=(6, 6))
ratio = [summary.iloc[0, 3], summary.iloc[0, 4], summary.iloc[0, 5]]
labels = ['상승', '보합', '하락']
explode = [0.40, 0.20, 0.00]
colors = ['red', 'grey', 'blue']
patches, texts, autotexts = plt.pie(ratio, explode=explode, colors=colors, autopct='%.1f%%', textprops={'size': 9})
plt.legend(labels)
for t in autotexts:
t.set_color("white")
t.set_fontsize(12)
plt.show()
plt.show()
return summary
def get_detail(self):
right_now = datetime.today().strftime('%Y-%m-%d %X')
url_for_detail = 'https://finance.naver.com/sise/sise_group_detail.naver?type=upjong'
sub_url = f'{url_for_detail}&no={self.upjong_num}'
response_detail = requests.get(sub_url)
df_for_detail = Upjong.get_page_sise_by_upjong(self)
df_detail = pd.read_html(response_detail.text)[-1]
df_detail = df_detail.dropna(how='all', axis=1)
df_detail = df_detail.dropna(how='all')
df_detail['업종명'] = df_for_detail[df_for_detail['업종번호'] == self.upjong_num]['업종명'].iloc[0]
df_detail = df_detail.reset_index(drop=True)
cols = [
'업종명', '종목명', '현재가', '전일비',
'등락률', '거래량', '거래대금' ,'전일거래량',
'매수호가', '매도호가'
]
df_detail = df_detail[cols]
cols_int = ['현재가', '전일비', '거래량', '거래대금', '전일거래량', '매수호가', '매도호가']
df_detail[cols_int] = df_detail[cols_int].astype(int)
return df_detail
def best5_in_detail(self):
right_now = datetime.today().strftime('%Y-%m-%d %X')
best5 = Upjong.get_detail(self).head(5)
if best5.shape[0] < 5:
print('해당 업종 내 기업이 5개 미만 입니다!')
print(f'{right_now} 현재 {self.upjong_nm} 업종의 모든 기업정보입니다!')
return best5
else:
print(f'{right_now} 현재 {self.upjong_nm} 업종의 전일대비 등락률 best5기업입니다!')
# 막대그래프
plt.figure(figsize=(9, 6))
x = best5['종목명']
y = best5['현재가']
plt.xlabel('종목명')
plt.ylabel('현재가')
plt.bar(x, y, color = 'red')
for i, v in enumerate(x):
plt.text(v, y[i], f'{i+1}위 : ' + best5['등락률'][i],
fontsize=12,
color="red",
horizontalalignment='center',
verticalalignment='bottom')
plt.show()
return best5
def worst5_in_detail(self):
right_now = datetime.today().strftime('%Y-%m-%d %X')
worst5= Upjong.get_detail(self)
r_idx = [i for i in range(worst5.shape[0]-1, -1, -1)]
worst5 = pd.DataFrame(worst5, index=r_idx).reset_index(drop=True)
worst5 = worst5.head(5)
if worst5.shape[0] < 5:
print('해당 업종 내 기업이 5개 미만 입니다!')
print(f'{right_now} 현재 {self.upjong_nm} 업종의 모든 기업정보입니다!')
return worst5
else:
print(f'{right_now} 현재 {self.upjong_nm} 업종의 전일대비 등락률 worst5기업입니다!')
# 막대그래프
plt.figure(figsize=(9, 6))
x = worst5['종목명']
y = worst5['현재가']
plt.xlabel('종목명')
plt.ylabel('현재가')
plt.bar(x, y, color = 'blue')
for i, v in enumerate(x):
plt.text(v, y[i], f'{i+1}위 : ' + worst5['등락률'][i],
fontsize=12,
color="blue",
horizontalalignment='center',
verticalalignment='bottom')
plt.show()
return worst5객체를 생성하고...
# 업종 객체 생성
판매업체 = Upjong('판매업체', '265')랭킹을 볼 수 있는 함수를 통해 순위를 볼 수 있다!
# 해당 업종의 등락률 순위 알아보기
판매업체.rank_upjong()
업종별 요약 정보를 볼수 있는 함수를 써보면...
판매업체.get_summary()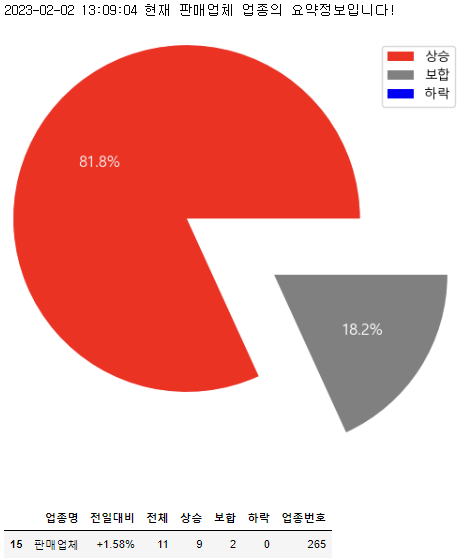
이렇게 볼 수 있다!
업종별 세부 정보를 볼 수 있는 함수를 써보면...
판매업체.get_detail()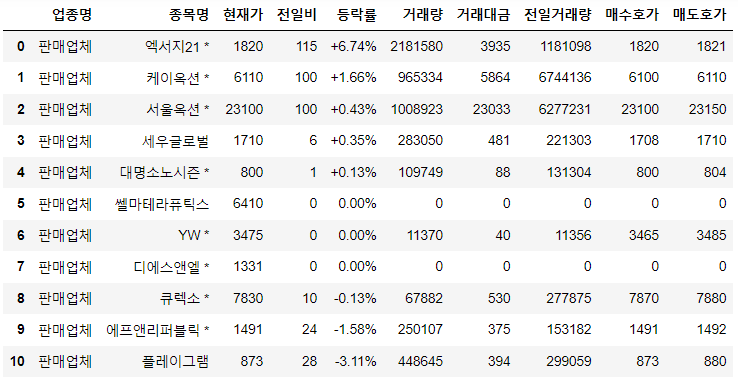
이렇고...
업종별 best5와 worst5를 보면
판매업체.best5_in_detail()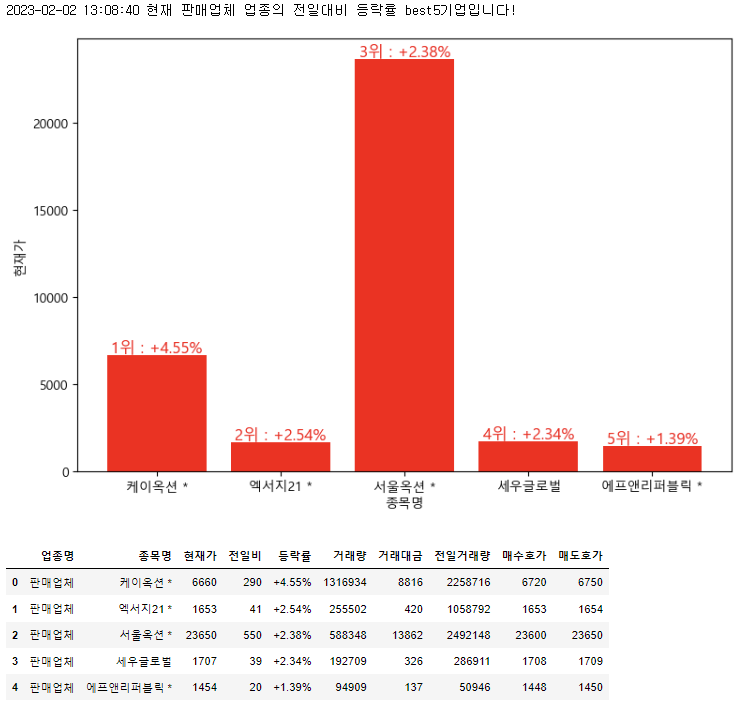
판매업체.worst5_in_detail()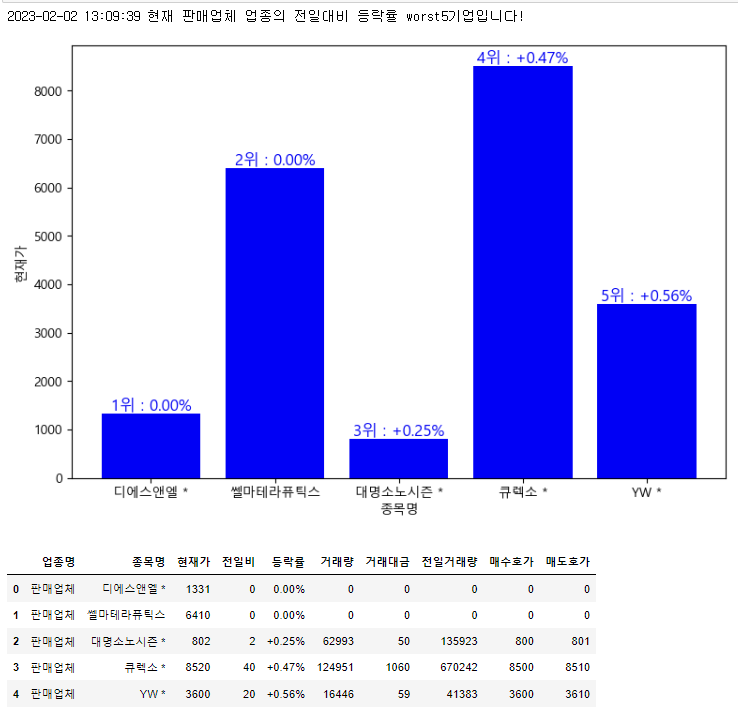
이렇게 확인할 수 있다!
이번에는 테마별 시세 수집 클래스를 만들어 봤다!
해당 페이지 : https://finance.naver.com/sise/theme.naver
테마별 시세 : 네이버 증권
관심종목의 실시간 주가를 가장 빠르게 확인하는 곳
finance.naver.com
코드는 이렇다...
import time
import pandas as pd
import requests
from bs4 import BeautifulSoup as bs
from datetime import datetime
import matplotlib.pyplot as plt
plt.rcParams['font.family'] ='Malgun Gothic'
class Theme:
def __init__(self, theme_nm, theme_num):
self.theme_nm = theme_nm
self.theme_num = theme_num
def get_pages_sise_by_theme(self):
'''
1. 끝 페이지를 번호를 얻기위한 기본 url로 끝페이지 정보 얻기
2. 반복문으로 첫페이지부터 끝페이지까지 스크래핑
3. 스크래핑 한 데이터 저장 후 불러오기
'''
url_for_end = 'https://finance.naver.com/sise/theme.naver'
response = requests.get(url_for_end)
html = bs(response.text)
end_page = int(html.select('td.pgRR > a')[0]['href'][-1])
pages_by_theme = []
for i in range(1, end_page+1):
url = f'https://finance.naver.com/sise/theme.naver?&page={i}'
# 요청
response = requests.get(url)
page = pd.read_html(response.text)[0]
# 결측치 제거
page = page.dropna()
page = page.reset_index(drop=True)
# 이중컬럼 제거
cols = ['테마명', '전일대비', '최근3일등락률(평균)', '상승', '보합', '하락', '주도주1', '주도주2']
page.columns = cols
# 테마내 전체 기업 수를 알기 위해 전체 컬럼 추가
page['전체'] = page['상승'] + page['보합'] + page['하락']
# 컬럼 순서 정리
cols = ['테마명', '전일대비', '최근3일등락률(평균)', '전체', '상승', '보합', '하락', '주도주1', '주도주2']
page = page[cols]
# 상승, 보합, 하락 컬럼 데이터타입 정수형으로 변환
page[['전체', '상승', '보합', '하락']] = page[['전체', '상승', '보합', '하락']].astype(int)
# 테마번호 컬럼 추가
html = bs(response.text)
theme_num = []
for link in html.select('tr > td > a')[:-15][::3]:
theme_num.append(link['href'].split('=')[-1])
page['테마번호'] = theme_num
pages_by_theme.append(page)
time.sleep(0.001)
pages_by_theme = pd.concat(pages_by_theme).reset_index(drop=True)
today_date = datetime.today().strftime('%Y-%m-%d')
file_name = f'테마별시세-{today_date}.csv'
pages_by_theme.to_csv(f'data/{file_name}', index=False)
pages_by_theme = pd.read_csv(f'data/{file_name}', dtype={'테마번호':object})
return pages_by_theme
def rank_theme(self):
right_now = datetime.today().strftime('%Y-%m-%d %X')
sise_by_theme = Theme.get_pages_sise_by_theme(self)
total_theme = sise_by_theme.shape[0]
today_rank = sise_by_theme[sise_by_theme['테마명'] == self.theme_nm].index[0] + 1
print(f'{self.theme_nm}의 {right_now} 현재 전일대비 등락률 순위는 {total_theme}종목중 {today_rank}위 입니다!')
def get_summary(self):
right_now = datetime.today().strftime('%Y-%m-%d %X')
before_summary = Theme.get_pages_sise_by_theme(self)
summary = before_summary[before_summary['테마명'] == self.theme_nm]
print(f'{right_now} 현재 {self.theme_nm} 테마의 요약정보입니다!')
# 파이차트
plt.figure(figsize=(6, 6))
ratio = [summary.iloc[0, 4], summary.iloc[0, 5], summary.iloc[0, 6]]
labels = ['상승', '보합', '하락']
explode = [0.40, 0.20, 0.00]
colors = ['red', 'grey', 'blue']
patches, texts, autotexts = plt.pie(ratio, explode=explode, colors=colors, autopct='%.1f%%', textprops={'size': 9})
plt.legend(labels)
for t in autotexts:
t.set_color("white")
t.set_fontsize(12)
plt.show()
return summary
def get_detail(self):
base_url = 'https://finance.naver.com/sise/sise_group_detail.naver?type=theme&no='
sub_url = f'{base_url}{self.theme_num}'
response_detail = requests.get(sub_url)
df_for_detail = Theme.get_pages_sise_by_theme(self)
df_detail = pd.read_html(response_detail.text)[-1]
df_detail = df_detail.dropna(how='all', axis=1)
df_detail = df_detail.dropna(how='all')
df_detail['테마명'] = df_for_detail[df_for_detail['테마번호'] == self.theme_num]['테마명'].iloc[0]
df_detail = df_detail.reset_index(drop=True)
cols = [
'테마명', '종목명', '현재가', '전일비',
'등락률', '거래량', '거래대금' ,'전일거래량',
'매수호가', '매도호가'
]
df_detail = df_detail[cols]
cols_int = ['현재가', '전일비', '거래량', '거래대금', '전일거래량', '매수호가', '매도호가']
df_detail[cols_int] = df_detail[cols_int].astype(int)
return df_detail
def best5_in_detail(self):
right_now = datetime.today().strftime('%Y-%m-%d %X')
best5 = Theme.get_detail(self).head(5)
if best5.shape[0] < 5:
print('해당 테마 내 기업이 5개 미만 입니다!')
print(f'{right_now} 현재 {self.theme_nm} 테마의 모든 기업정보입니다!')
return best5
else:
print(f'{right_now} 현재 {self.theme_nm} 테마의 전일대비 등락률 best5기업입니다!')
# 막대그래프
plt.figure(figsize=(9, 6))
x = best5['종목명']
y = best5['현재가']
plt.xlabel('종목명')
plt.ylabel('현재가')
plt.bar(x, y, color = 'red')
for i, v in enumerate(x):
plt.text(v, y[i], f'{i+1}위 : ' + best5['등락률'][i],
fontsize=12,
color="red",
horizontalalignment='center',
verticalalignment='bottom')
plt.show()
return best5
def worst5_in_detail(self):
right_now = datetime.today().strftime('%Y-%m-%d %X')
worst5= Theme.get_detail(self)
r_idx = [i for i in range(worst5.shape[0]-1, -1, -1)]
worst5 = pd.DataFrame(worst5, index=r_idx).reset_index(drop=True)
worst5 = worst5.head(5)
if worst5.shape[0] < 5:
print('해당 테마 내 기업이 5개 미만 입니다!')
print(f'{right_now} 현재 {self.theme_nm} 테마의 모든 기업정보입니다!')
return worst5
else:
print(f'{right_now} 현재 {self.theme_nm} 테마의 전일대비 등락률 worst5기업입니다!')
# 막대그래프
plt.figure(figsize=(9, 6))
x = worst5['종목명']
y = worst5['현재가']
plt.xlabel('종목명')
plt.ylabel('현재가')
plt.bar(x, y, color = 'blue')
for i, v in enumerate(x):
plt.text(v, y[i], f'{i+1}위 : ' + worst5['등락률'][i],
fontsize=12,
color="blue",
horizontalalignment='center',
verticalalignment='bottom')
plt.show()
return worst5앞에서 작성했던 것과 기능이 비슷하지만... 실행을 해보면!
이차전지 = Theme('2차전지', '64')이차전지.rank_theme()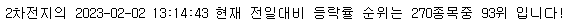
이차전지.get_summary()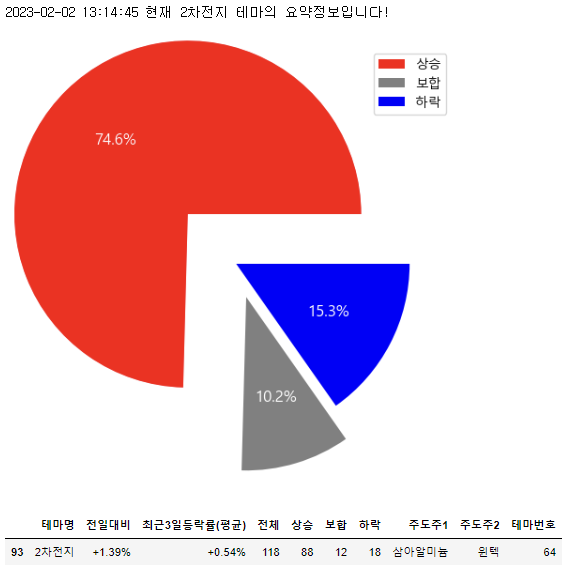
이차전지.get_detail()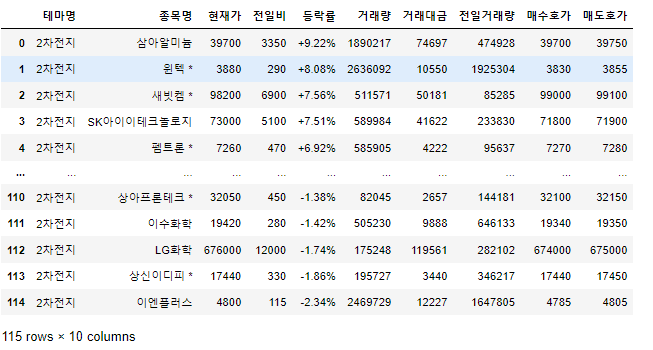
이차전지.best5_in_detail()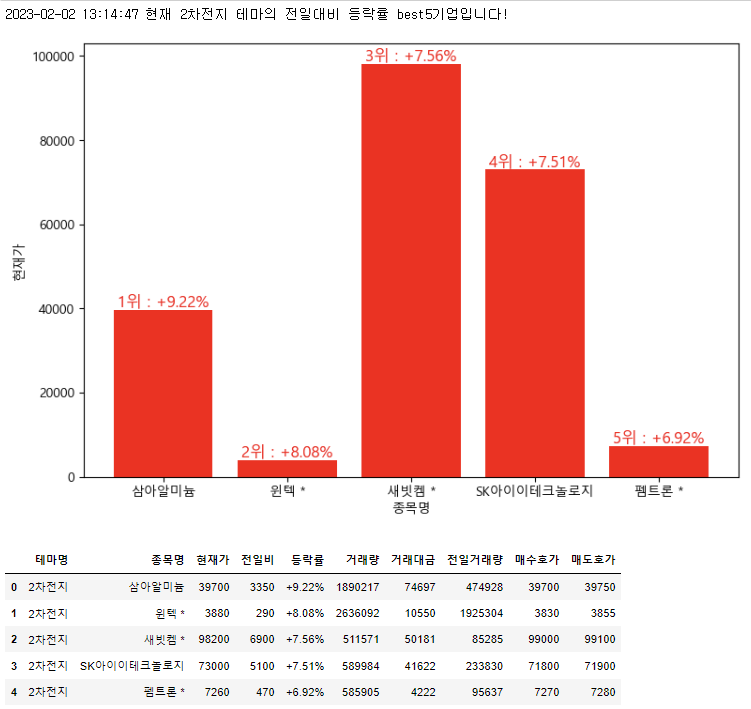
이차전지.worst5_in_detail()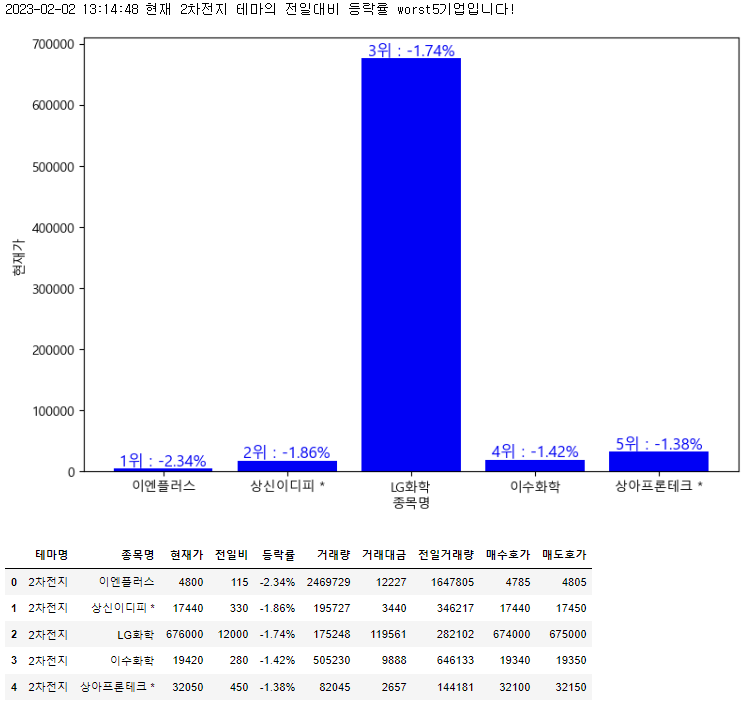
마지막으로 그룹사별 시세 스크래핑하는 코드도 짜봤다!
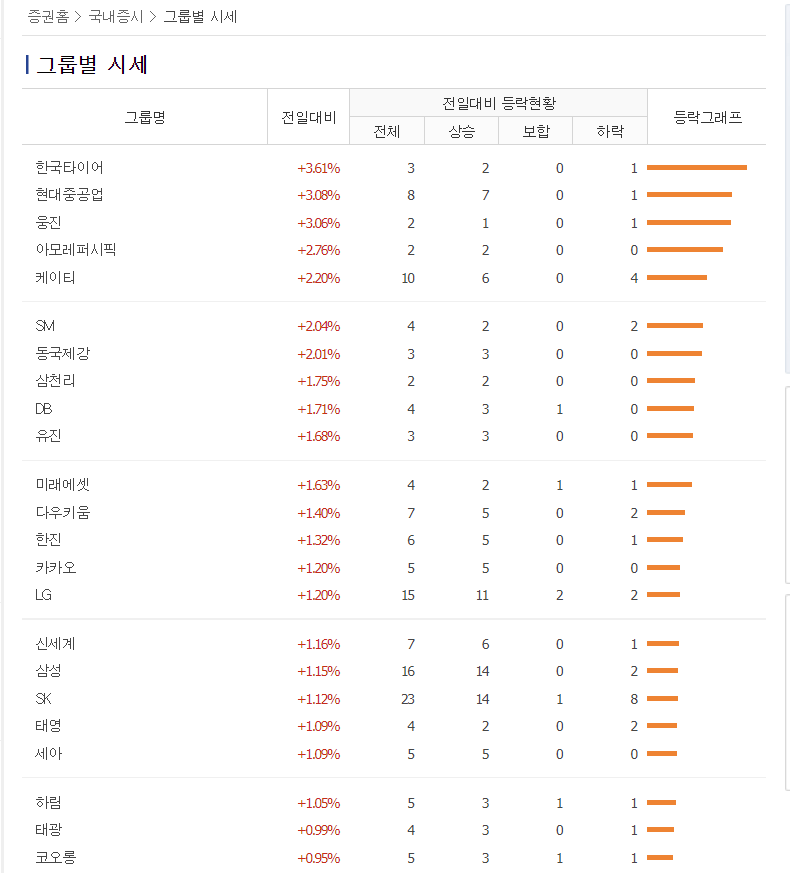
해당 페이지 : https://finance.naver.com/sise/sise_group.naver?type=group
테마별 시세 : 네이버 증권
관심종목의 실시간 주가를 가장 빠르게 확인하는 곳
finance.naver.com
코드는 이러하다...
import pandas as pd
import requests
import numpy as np
from bs4 import BeautifulSoup as bs
from datetime import datetime
import matplotlib.pyplot as plt
plt.rcParams['font.family'] ='Malgun Gothic'
class Groupsa:
def __init__(self, group_nm, group_num):
self.group_nm = group_nm
self.group_num = group_num
def get_page_sise_by_group(self):
'''
그룹사별 시세 페이지를 스크래핑하는 함수
'''
url = 'https://finance.naver.com/sise/sise_group.naver?type=group'
response = requests.get(url)
df = pd.read_html(response.text)[0]
df = df.dropna()
df = df.reset_index(drop=True)
cols = ['그룹명', '전일대비', '전체', '상승', '보합', '하락', '등락그래프']
df.columns = cols
df = df.drop('등락그래프', axis=1)
df[['전체', '상승', '보합', '하락']] = df[['전체', '상승', '보합', '하락']].astype(int)
html = bs(response.text)
group_no = [link['href'].split('&')[-1].replace('no=','') for link in html.select('td > a')[:-5]]
df['그룹번호'] = group_no
today_date = datetime.today().strftime('%Y-%m-%d')
file_name = f'그룹별시세-{today_date}.csv'
df.to_csv(f'data/{file_name}', encoding='utf-8-sig', index=False)
df = pd.read_csv(f'data/{file_name}', dtype={'그룹번호':object})
return df
def rank_groupsa(self):
right_now = datetime.today().strftime('%Y-%m-%d %X')
sise_by_group = Groupsa.get_page_sise_by_group(self)
total_group = sise_by_group.shape[0]
today_rank = sise_by_group[sise_by_group['그룹명'] == self.group_nm].index[0] + 1
print(f'{self.group_nm}의 {right_now} 현재 전일대비 등락률 순위는 {total_group}그룹중 {today_rank}위 입니다!')
def get_summary(self):
right_now = datetime.today().strftime('%Y-%m-%d %X')
before_summary = Groupsa.get_page_sise_by_group(self)
summary = before_summary[before_summary['그룹명'] == self.group_nm]
print(f'{right_now} 현재 {self.group_nm} 그룹의 요약정보입니다!')
plt.figure(figsize=(6, 6))
ratio = [summary.iloc[0, 3], summary.iloc[0, 4], summary.iloc[0, 5]]
labels = ['상승', '보합', '하락']
explode = [0.40, 0.20, 0.00]
colors = ['red', 'grey', 'blue']
patches, texts, autotexts = plt.pie(ratio, explode=explode, colors=colors, autopct='%.1f%%', textprops={'size': 9})
plt.legend(labels)
for t in autotexts:
t.set_color("white")
t.set_fontsize(12)
plt.show()
plt.show()
return summary
def get_detail(self):
right_now = datetime.today().strftime('%Y-%m-%d %X')
url_for_detail = 'https://finance.naver.com/sise/sise_group_detail.naver?type=group'
sub_url = f'{url_for_detail}&no={self.group_num}'
response_detail = requests.get(sub_url)
df_for_detail = Groupsa.get_page_sise_by_group(self)
df_detail = pd.read_html(response_detail.text)[-1]
df_detail = df_detail.dropna(how='all', axis=1)
df_detail = df_detail.dropna(how='all')
df_detail['그룹명'] = df_for_detail[df_for_detail['그룹번호'] == self.group_num]['그룹명'].iloc[0]
df_detail = df_detail.reset_index(drop=True)
cols = [
'그룹명', '종목명', '현재가', '전일비',
'등락률', '거래량', '거래대금' ,'전일거래량',
'매수호가', '매도호가'
]
df_detail = df_detail[cols]
cols_int = ['현재가', '전일비', '거래량', '거래대금', '전일거래량', '매수호가', '매도호가']
df_detail[cols_int] = df_detail[cols_int].astype(int)
return df_detail
def best3_in_detail(self):
right_now = datetime.today().strftime('%Y-%m-%d %X')
best3 = Groupsa.get_detail(self).head(3)
if best3.shape[0] < 3:
print('해당 그룹 내 기업이 3개 미만 입니다!')
print(f'{right_now} 현재 {self.group_nm} 그룹의 모든 기업정보입니다!')
return best3
else:
print(f'{right_now} 현재 {self.group_nm} 그룹의 전일대비 등락률 best3기업입니다!')
# 막대그래프
plt.figure(figsize=(9, 6))
x = best3['종목명']
y = best3['현재가']
plt.xlabel('종목명')
plt.ylabel('현재가')
plt.bar(x, y, color = 'red')
for i, v in enumerate(x):
plt.text(v, y[i], f'{i+1}위 : ' + best3['등락률'][i],
fontsize=12,
color="red",
horizontalalignment='center',
verticalalignment='bottom')
plt.show()
return best3
def worst3_in_detail(self):
right_now = datetime.today().strftime('%Y-%m-%d %X')
worst3= Groupsa.get_detail(self)
r_idx = [i for i in range(worst3.shape[0]-1, -1, -1)]
worst3 = pd.DataFrame(worst3, index=r_idx).reset_index(drop=True)
worst3 = worst3.head(3)
if worst3.shape[0] < 3:
print('해당 그룹 내 기업이 3개 미만 입니다!')
print(f'{right_now} 현재 {self.group_nm} 그룹의 모든 기업정보입니다!')
return worst3
else:
print(f'{right_now} 현재 {self.group_nm} 그룹의 전일대비 등락률 worst3기업입니다!')
# 막대그래프
plt.figure(figsize=(9, 6))
x = worst3['종목명']
y = worst3['현재가']
plt.xlabel('종목명')
plt.ylabel('현재가')
plt.bar(x, y, color = 'blue')
for i, v in enumerate(x):
plt.text(v, y[i], f'{i+1}위 : ' + worst3['등락률'][i],
fontsize=12,
color="blue",
horizontalalignment='center',
verticalalignment='bottom')
plt.show()
return worst3마찬가지로 기능들을 실행해보면...
한국타이어 = Groupsa('한국타이어', '113')한국타이어.rank_groupsa()
한국타이어.get_summary()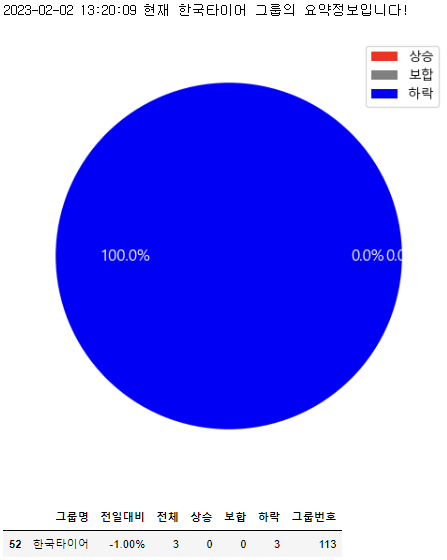
한국타이어.get_detail()
한국타이어.best3_in_detail()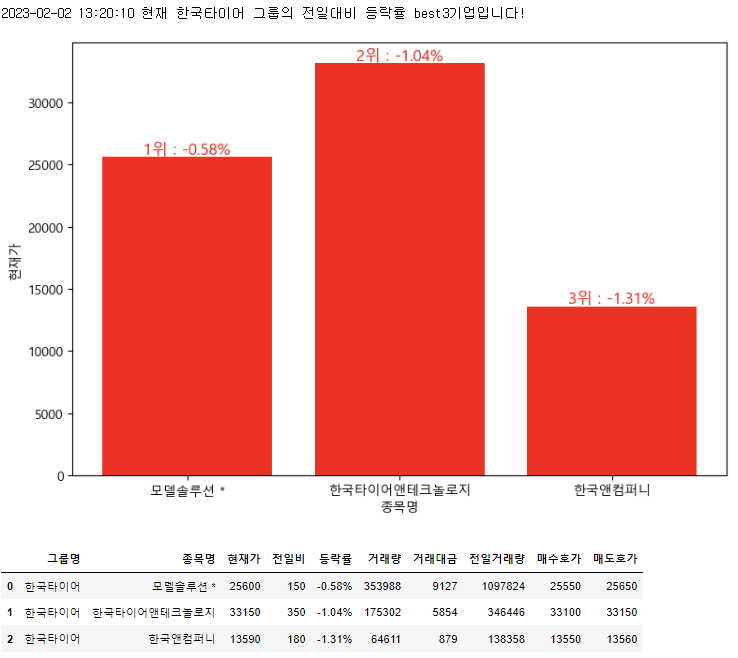
한국타이어.worst3_in_detail()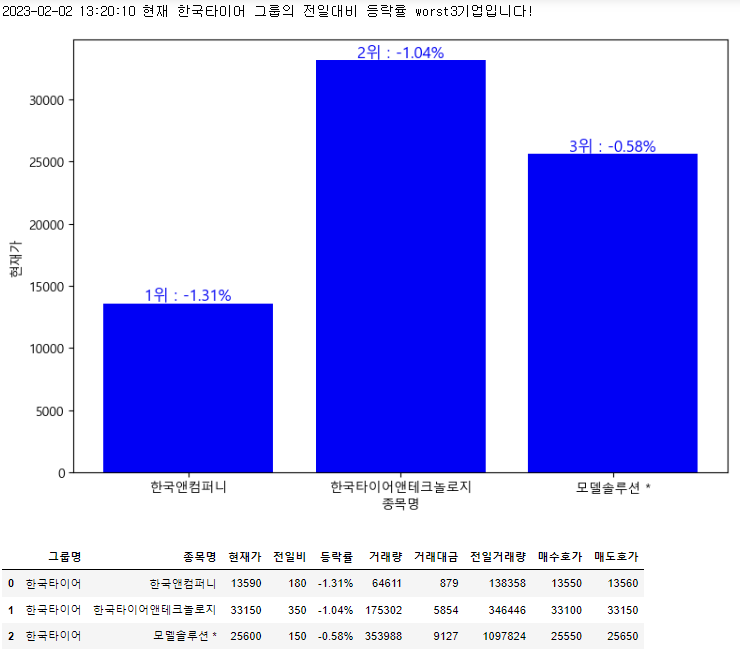
내가 프로젝트에서 작성한 것은 이정도이다...
근데 조원들과 함께 코드를 모아서 모듈로 만들어보고 싶어서 제안을 했더니...
흔쾌히 받아주셔서 모듈을 만들어봤다!!!(물론 나는 숟가락만 얹은 듯?)
그럼 모듈에서 내가 만든 기능을 한 번 써보자!
!pip install shasha4
이렇게 코드를 설치 합니다!
다른 분은 개별 종목에 관한 클래스를 만들어주셔서...
종목 리스트를 확인하는 함수도 들어있다!
from shasha4 import jongmok_list
jongmok_list()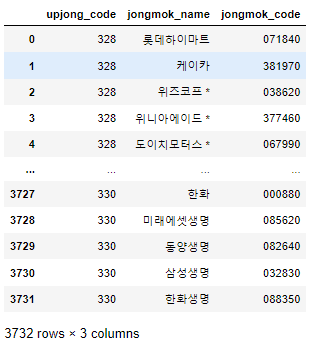
3732개 종목에 해당하는 업종코드와 종목이름 종목코드가 있다!
저는 제 기능을 쓰기 위해 일단 업종명과 업종코드리스트를 불러오는 함수를 실행!
from shasha4 import get_upjong_list_K
get_upjong_list_K()이렇게 하면

업종명과 업종코드를 볼 수 있고...
음... 여기서 반도체와반도체장비 정보를 썼다!
from shasha4 import Upjong
반도체와반도체장비 = Upjong('반도체와반도체장비', '278')업종 클래스에 업종이름과 코드를 넣어줘서 객체를 생성했습니다.
그리고 get_summary()함수를 써봤다!
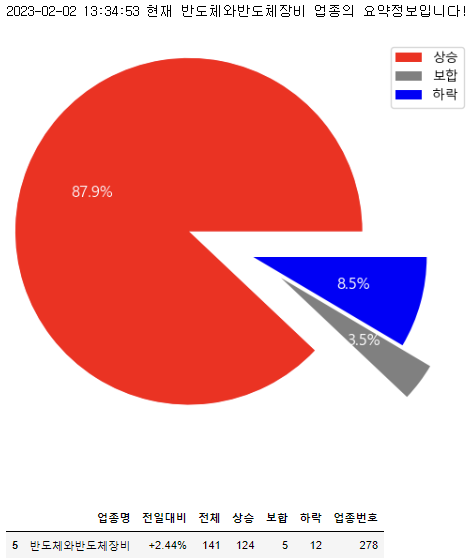
이렇게 모듈 시험을 해봤다!
이번 프로젝트는 열심히 하긴 했지만 뭔가 스스로 만족스러운 코드를 짜지는 못한 것 같다..
하지만 처음으로 모듈을 만들고 배포까지(내가 하진 않았지만)해봐서...
뭔가 이뤄냈다는 느낌을 받아서 매우 뿌듯했다!
'멋쟁이사자처럼 AI스쿨' 카테고리의 다른 글
| 멋쟁이사자처럼miniproject2(행복지수와 코로나확진률) (0) | 2023.02.08 |
|---|---|
| 멋쟁이사자처럼 AI스쿨 7주차 회고 (0) | 2023.02.02 |
| 멋쟁이사자처럼 miniproject1(스타벅스 매장 정보 수집하기) (0) | 2023.01.31 |
| 멋쟁이사자처럼 AI스쿨 5주차 회고 (0) | 2023.01.19 |
| 네이버 증권 종목토론실수집(과제보충) (0) | 2023.01.18 |




댓글