이번 미니프로젝트는 14기가에 육박하는 2달치... 데이터를 불러오고 분석해보는? 것이었다...
파케를 통해 데이터를 불러와도... 컴퓨터가 아주 힘들어했다...
그렇게 고민하던 중... 조원 한분이 dask를 통해 데이터를 불러와주셔서 모든 데이터를 불러올 수 있었다!
모든 데이터를 불러오고 downcast후 파케로 저장했지만...
너무 분석하는데 오래걸려서...
결국 애플팀, 삼성팀으로 나눠서 brand가 apple, samsung인 것만 진행해보기로 했다!(나는 애플팀!)
일단... 필요라이브러리로드!
import pandas as pd
import numpy as np
import seaborn as sns
import datetime as dt
import matplotlib.pyplot as pltimport koreanize_matplotlib
%config InlineBackend.figure_format = 'retina'
조원분이 주신 apple데이터...도 살포시 올리려했으나 용량때문에 안올라갑니다...?
내가 받은 apple데이터 불러오기!
apple = pd.read_parquet('data/apple.parquet.gzip')
apple
event_time : 각 이벤트가 벌어진 시간이다!
event_time : 이벤트의 종류이며 view(조회), cart(장바구니), purchase(구매) 3가지가 있다!
product_id : 제품 id
category_id : 카테고리id
category_code : 카테고리를 직접 알아볼 수 있는 설명? 정도로 볼 수 있을 것 같다!
brand : 브랜드 애플만 존재!
price : 구매 가격
user_id : 유저의 id
user_session : 유저의 고유 세션(유저의 세션으로 일정 시간 마다 업데이트 될 것 같다?)
의 컬럼을 가진 데이터이다!
info()확인!
apple.info()
브랜드가 apple인 것만 뽑아왔는데도... 좀 크다!
일단 알아볼 수 없는 카테고리 id를 삭제하자!
apple = apple.drop('category_id', axis=1)
apple
결측치 확인 및 시각화 해보자!
apple.isnull().sum()
plt.figure(figsize=(10,6))
sns.displot(
data=apple.isna().melt(value_name="missing"),
y="variable",
hue="missing",
multiple="fill",
aspect=1.25
);
시각화로 확인 결과 결측치의 비율?은 작은 것을 확인했다!
그럼 카테고리별로 살펴보자!
알단 카테고리별 view의 빈도수를 살펴보자!
category_by_view = apple[apple['event_type'] == 'view'].groupby("category_code")["product_id"].agg(['count']).sort_values(by='count', ascending=False)
category_by_view
스마트폰이 가장 많네?
시각화도...
category_by_view.plot(kind='bar', figsize=(20,4), rot=20);
스마트폰이 압도적이고 그 다음 순서로 헤드폰이 따르는 모습... 에어팟일까...?
이번엔 카테고리별 장바구니 빈도수를 살펴보자!
category_by_cart = apple[apple['event_type'] == 'cart'].groupby("category_code")["product_id"].agg(['count']).sort_values(by='count', ascending=False)
category_by_cart
view랑 비슷하다...
시각화도 살포시...
category_by_cart.plot(kind='bar', figsize=(20,4), rot=20);
카테고리별 구매횟수빈도도 알아보자!
category_by_purchase = apple[apple['event_type'] == 'purchase'].groupby("category_code")["product_id"].agg(['count']).sort_values(by='count', ascending=False)
category_by_purchase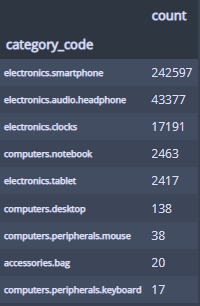
시각화도!
category_by_purchase.plot(kind='bar', figsize=(20,4), rot=20);
카테고리별 총 매출을 한번 보자!
category_by_sales = apple[apple['event_type'] == 'purchase'].groupby("category_code")["price"].agg(['sum']).sort_values(by='sum', ascending=False).round(0)
category_by_sales
스마트폰과 헤드폰(에어팟?)은 1, 2 위가 아닌 경우가 없네...
마지막으로 카테고리별 제품 평균값을 보자!
category_by_price = apple.groupby("category_code")["price"].agg(['mean']).sort_values(by='mean', ascending=False).round(2)
category_by_price
확실히 데스크탑 노트북 스마트폰 태블릿 순으로 비싼 것을 볼 수 있다!
시각화도!
category_by_price.plot(kind='bar', figsize=(20,4), rot=20);
카테고리별로 종합해서 한번 보자!
category = pd.concat([
category_by_view,
category_by_cart,
category_by_purchase,
category_by_sales,
category_by_price
], axis=1)
category.columns = ['view', 'cart', 'purchase', 'sales', 'mean_price']
category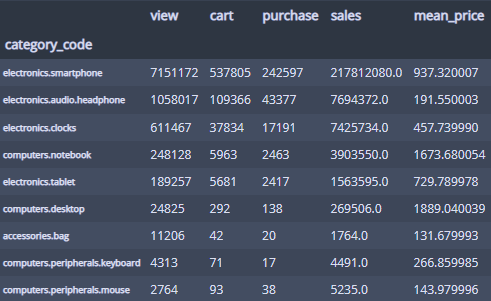
이런 데이터프레임이 만들어졌고...
background_gradient로 시각화 해보면...

종합적으로 볼 수 있다!
스마트폰이 인기 상품이란 것을 단번에 파악할 수 있다!
이번에는 카테고리별 조회 => 장바구니, 조회 => 구매, 장바구니 => 구매 전환율을 구해보자!
category['view_to_cart_ratio'] = category['cart']/category['view']
category['view_to_purchase_ratio'] = category['purchase']/category['view']
category['cart_to_purchase_ratio'] = category['purchase']/category['cart']
category_conversion = category[['view_to_cart_ratio', 'view_to_purchase_ratio', 'cart_to_purchase_ratio']]
category_conversion
구매 전환율 구해봤고...
시각화하면..
category_conversion.style.background_gradient()
구매 전환율의 높고 낮음을 한눈에 볼 수 있다!
이번엔 시간에 따른 분석을 해보자!
일단 event_time의 형식을 바꿔준뒤...
달, 일, 날짜, 요일(숫자), 시간, 시 정도의 파생변수를 만들어보자!
apple["event_time"] = pd.to_datetime(apple["event_time"].str[:-4])
# 날짜 파생변수 만들어주기
apple["event_month"] = apple["event_time"].dt.month
apple["event_day"] = apple["event_time"].dt.day
# 이건 월이랑 일 변수
apple['event_dm'] = apple['event_time'].astype('str').str[5:10]
apple["event_dow"] = apple["event_time"].dt.dayofweek
apple["event_only_time"] = apple["event_time"].dt.time
apple["event_hour"] = apple["event_time"].dt.hour
apple.head()
굿!!!
먼저... 달별로 조회+장바구니+판매 빈도수를 보자!
sns.countplot(data=apple, x='event_month');
11월이 이커머스 핫한 달아라 확실히 많다!
월별 구매 빈도수도 보자!
sns.countplot(data=apple[apple['event_type'] == 'purchase'], x='event_month');
구매도 11월이 많다!
그럼 요일별 회+장바구니+판매 빈도수를 확인해보자!
day_name = [w for w in "월화수목금토일"]
sns.countplot(data=apple, x='event_dow')
plt.xticks(range(len(day_name)), day_name);
금요일이 핫하다!
구매를 요일별로 보면...
sns.countplot(data=apple[apple['event_type'] == 'purchase'], x='event_dow')
plt.xticks(range(len(day_name)), day_name);
주말에 구매가 많이 일어난다!
이제 날짜별로 모든 이벤트 빈도수를 보면...
apple['event_dm'].value_counts().sort_index().plot(kind='bar', figsize=(20, 10), rot=30);
11월 15, 16, 17이 무슨 할인행사가 있나... 돋보인다!
일별 구매수를 보면...
apple[apple['event_type'] == 'purchase'].groupby('event_dm').agg({'price':'count'}).plot(kind='bar', figsize=(20, 5), rot=30);
11월 16, 17이 확연하게 높은 것을 볼 수 있는데... 11월 15일은 없는 걸로 봐선... 누락된 것으로 보인다!
17일일에 어떤 카테고리가 매출액이 가장 높은시 살포시 보면...
apple[(apple['event_type'] == 'purchase') & (apple['event_dm'] == '11-17')].groupby('category_code').agg({'price':'sum'}).style.format("{:,.0f}")
스마트폰의 매출액이 엄청난 것을 볼 수 있다....
하루의 시간대 별로도 조회+장바구니+구매 빈도수를 보면...
plt.figure(figsize=(12, 4))
sns.pointplot(data=apple, x="event_hour", y='user_id',
errorbar=None, estimator=len);
오후 시간대가 가장 많은 반면...
매출액은...
plt.figure(figsize=(12, 4))
sns.pointplot(data=apple[apple['event_type'] == 'purchase'], x="event_hour", y='user_id',
errorbar=None, estimator=sum);
오후 오전?이 가장 높다?(아무래도 주말 오전에 많이 구입한 영향인듯하다!)
잔존율을 보려고 코호트 분석도 해보자!
기간이 2달밖에 없는만큼...
주 단위로 코호트 분석을 하기로 하고!
구매고객만 뽑아서 해보기로 하자!
일단 애플 데이터에 주 번호를 넣어준다!
마지막 주는 일수가 적어서 일관성을 주려고 그냥 빼기로 했다!
apple.loc[(apple['event_time'] >= '2019-10-01') & (apple['event_time'] < '2019-10-08'), 'week_num'] = 1
apple.loc[(apple['event_time'] >= '2019-10-08') & (apple['event_time'] < '2019-10-15'), 'week_num'] = 2
apple.loc[(apple['event_time'] >= '2019-10-15') & (apple['event_time'] < '2019-10-22'), 'week_num'] = 3
apple.loc[(apple['event_time'] >= '2019-10-22') & (apple['event_time'] < '2019-10-29'), 'week_num'] = 4
apple.loc[(apple['event_time'] >= '2019-10-29') & (apple['event_time'] < '2019-11-05'), 'week_num'] = 5
apple.loc[(apple['event_time'] >= '2019-11-05') & (apple['event_time'] < '2019-11-12'), 'week_num'] = 6
apple.loc[(apple['event_time'] >= '2019-11-12') & (apple['event_time'] < '2019-11-19'), 'week_num'] = 7
apple.loc[(apple['event_time'] >= '2019-11-19') & (apple['event_time'] < '2019-11-26'), 'week_num'] = 8
df_for_cohort = apple[~apple['week_num'].isnull()]
이렇게 날짜별로 주 번호가 잘 들어갔다!
모든 데이터에 첫 구매 주를 구해주자!
df_for_cohort['week_num_min'] = df_for_cohort.groupby('user_id')['week_num'].transform('min')
df_for_cohort['week_num_min']
첫 구매주가 잘 들어갔다!
코호트 인덱스(그 구매 데이터가 처음 구매 데이터로부터 얼마나 지났는지...(최솟값1))를 구해주자!
df_for_cohort['CohortIndex'] = df_for_cohort['week_num'] - df_for_cohort['week_num_min'] + 1
df_for_cohort['CohortIndex']
잘 들어갔고...
구매데이터만 보기로 했으니까...
구매데이터만 뽑아주자!
df_for_cohort_purchase = df_for_cohort[df_for_cohort['event_type'] == 'purchase']
구매고객의 잔존 수를 보면...
cohort_count_purchase= df_for_cohort_purchase.groupby(['week_num_min', 'CohortIndex'])['user_id'].nunique().unstack()
cohort_count_purchase
이렇고...
쉽게 보기 위해 시각화를 해주면...
cohort_count_purchase.index = cohort_count_purchase.index.astype(str).str[0] + '주'
plt.figure(figsize=(12, 8))
sns.heatmap(cohort_count_purchase, cmap='Blues', annot=True, fmt=".0f");
역시 코호트 인덱스 1이 제일 많고...
7주차(11월 16, 17일이 껴있는 주)의 잔존수가 확 뛴 것을 볼 수 있다!
주차별로 신규 유입 고객수도 한번 보면...
plt.figure(figsize=(12, 5))
cohort_count_purchase[1].plot(kind='bar', rot=0);
1주가 가장 많고... 7주차에 확 늘어났다!(11월 16, 17데이터의 영향인 듯 하다!)
잔존률로도 한번 보면...
cohort_norm_purchase = cohort_count_purchase.div(cohort_count_purchase[1], axis=0).round(2)
plt.figure(figsize=(12, 8))
sns.heatmap(cohort_norm_purchase, cmap='Blues', annot=True, fmt=".2f");
비율로 살펴볼 수 있다! 확실히 7주 대각선 방향이 눈에 띈다!
조원 한분이 구매횟수와 유저세션수(유저의 접속 빈도)의 상관관계를 구해보면 좋을 것 같다고 아이디어를 내주셔서...
같이 해봤다!
먼저, 유저별 세션수를 한번 구해보자!
session_num = apple.groupby(["user_id"]).agg({"user_session":"nunique"})
session_num
1번 접속한 고객이 가장 많긴 하군...
유저별 구매수 도 구해보자!
purchase_num = apple[apple['event_type'] == 'purchase'].groupby(["user_id"]).agg({"user_id":"count"})
purchase_num
구매도 1번 한사람이 많은 것으로 보인다!
조인으로... 세션수와 구매수가 같이있는 데이터프레임을 만들어보자!
session_and_purchase = session_num.join(purchase_num, how='left')
session_and_purchase
결측치는 구매횟수 0을 의미하기 때문에 0으로 채워주자!
session_and_purchase = session_and_purchase.fillna(0)
session_and_purchase
짠!
이제 상관관계를 한번 보면...
session_and_purchase.corr()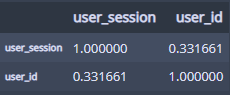
그리 높은 상관관계는 아니다...?
regplot으로 시각화를 해보면...
plt.figure(figsize=(20, 20))
sns.regplot(session_and_purchase, x='user_session', y='user_id');
plt.xlabel('세션수')
plt.ylabel('구매수')
세션수만 500번(접속만 500번 한것)이면서 구매는 거의 안한 데이터들이 존재한다!
이것을 이상치로 보고 이상치를 제거하고 상관관계를 보면...
session_and_purchase = session_and_purchase[session_and_purchase['user_session'] < 500]
session_and_purchase.corr()
그나마 중간? 정도의 상관관계가 있다고는 나온다!
시각화도 해보면...
plt.figure(figsize=(10, 20))
sns.regplot(session_and_purchase, x='user_session', y='user_id');
plt.xlabel('세션수')
plt.ylabel('구매수')
이렇다!
세션 타임도 해봤지만... 애플 구매데이터만 딱 뽑아온 것이라서...
의미가 없는 것 같아서... 뻈다!
이번에는 고객별 RFM을 구해서 kmeans알고리즘을 통한 군집화를 해보기로하자!
일단 애플데이터를 다시 불러와서!
필요없는 컬럼 제거 후...
이벤트타임 datetime형식으로 바꿔주고...
구매 데이터만 뽑아와서...
중복제거까지!
apple = pd.read_parquet('data/apple.parquet.gzip')
apple = apple.drop('category_id', axis=1)
apple['event_time'] = pd.to_datetime(apple['event_time'].str[:-4])
df_for_rfm = apple[apple['event_type'] == 'purchase']
df_for_rfm = df_for_rfm.drop_duplicates()
df_for_rfm
이렇게 된다....
구매 횟수는 보통 세션당 1번이라고 생각되기 떄문에...(여러개를 계속사는게 아니라 한번에 여러개를 삼)
그걸 적용해주면...
df_for_rfm = df_for_rfm.groupby('user_session').agg({'user_id':'unique',
'event_time':lambda x : x.max(),
'user_session':'count',
'price':'sum'})
df_for_rfm
이렇게 되고...
아이디 대괄호 제거 해주자!
df_for_rfm['user_id'] = df_for_rfm['user_id'].astype('str').str[1:10]
df_for_rfm
Recency를 위한 기준 날짜를 정해주고!
last_timestamp = df_for_rfm['event_time'].max() + dt.timedelta(days=1)
last_timestamp
이제 rfm생성! 해주고 컬럼명도 변경해주면...
rfm = df_for_rfm.groupby(by='user_id').agg({"event_time":lambda x: (last_timestamp - x.max()).days,
"user_id":"count",
"price":"sum"})
rfm.columns = ['Recency', 'Frequency', 'MonetaryValue']
rfm
이렇게 RFM데이터 완성!
분포를 보면...
rfm.hist(bins=50);
F, M만 좀 쏠려있어서...
이것만 로그 변환을 해주자!
rfm_log = np.log(rfm + 1)
rfm_final = pd.concat([rfm['Recency'], rfm_log[['Frequency', 'MonetaryValue']]], axis=1)
rfm_final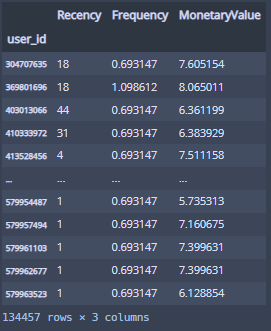
분포를 확인해보면...
rfm_final.hist(bins=50);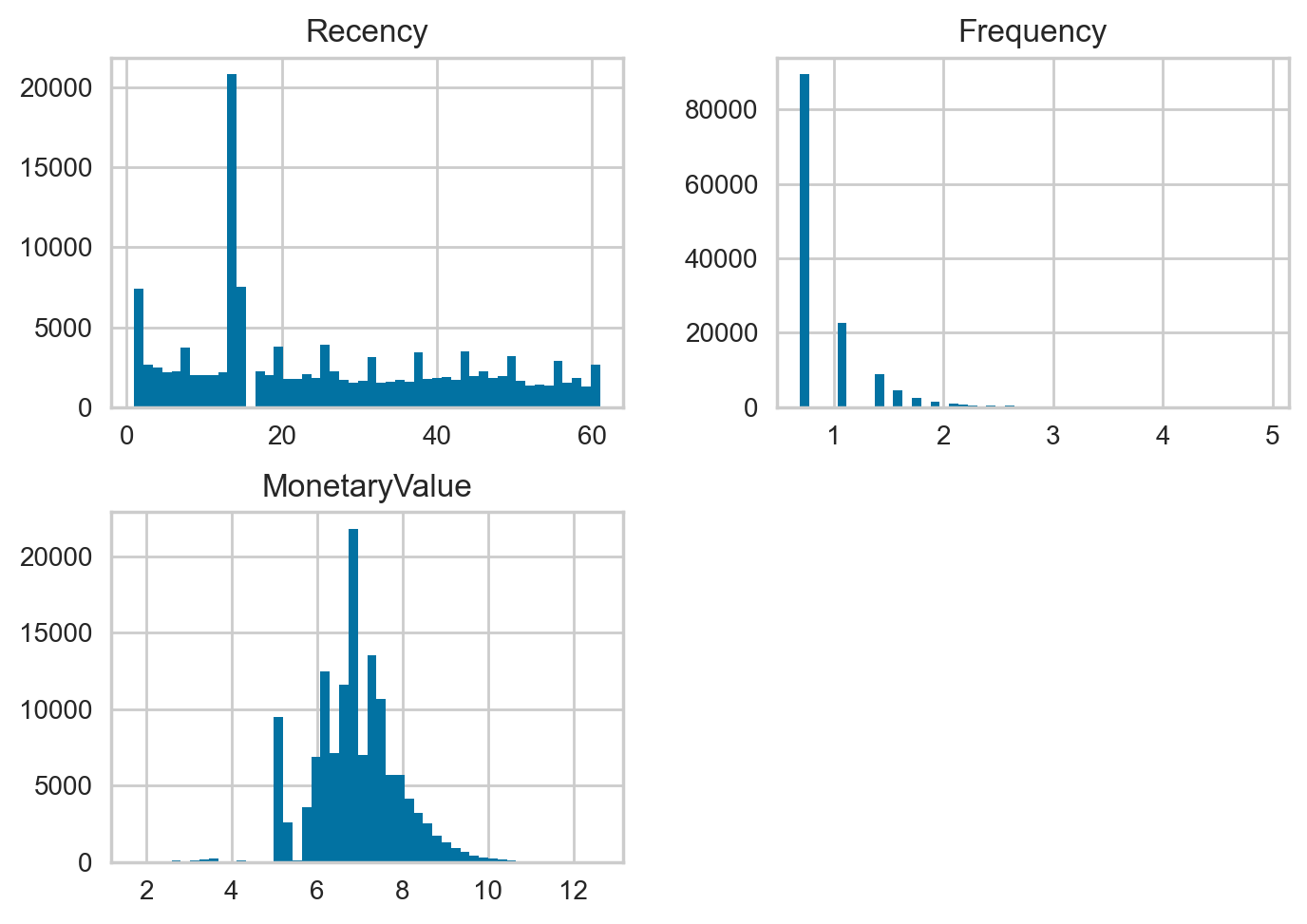
쏠림 현상이 좀 완화!
StandardScaler를 사용해 rfm_final을 표준화 해준다!
from sklearn.preprocessing import StandardScaler
ss = StandardScaler()
ss.fit(rfm_final)
X = ss.transform(rfm_final)
X
이렇게 X가 만들어졌고...
표준화가 잘 되었는지도 확인!
pd.DataFrame(X).describe().round(2)
평균이 0, 표준편차1로 굿!!!
이제 kmeans알고리즘을 만드는데...
군집 2개부터 10개까지 만들고 fit해주자!
from sklearn.cluster import KMeans
range_n_clusters = range(2, 11)
for n_cluster in range_n_clusters:
kmeans = KMeans(n_clusters=n_cluster, random_state=42)
kmeans.fit(X)
적당한 군집수를 빠르게 찾기위해서...
KElbowVisualizer를 활용!
# KElbowVisualizer로 적절한 군집수 찾기
from yellowbrick.cluster import KElbowVisualizer
KEV = KElbowVisualizer(kmeans, k=10, n_init='auto')
KEV.fit(X)
KEV.show()
적당한 군집수가 4개라고 나온다!
4개로 fit해주자!
n_clusters = 4
kmeans = KMeans(n_clusters=n_clusters, random_state=42)
kmeans.fit(X)
나눠준 군집의 빈도를 살펴보면...
pd.Series(kmeans.labels_).value_counts()
1 > 2 > 0 > 3 순으로 빈도가 많다!
그럼 군집으로 나눠준 것을...
rfm데이터에다 넣어주자!
rfm['Cluster'] = kmeans.labels_
rfm
R,F,M 세 가지를 모두 보면서 군집을 파악하고 싶어서...
3차원 스캐터플롯으로 시각화해보면...
from mpl_toolkits.mplot3d import Axes3D
fig = plt.figure(figsize=(20, 20))
ax1 = plt.subplot(111, projection='3d')
x0 = rfm[rfm['Cluster'] == 0]['Recency']
y0 = rfm[rfm['Cluster'] == 0]['Frequency']
z0 = rfm[rfm['Cluster'] == 0]['MonetaryValue']
x1 = rfm[rfm['Cluster'] == 1]['Recency']
y1 = rfm[rfm['Cluster'] == 1]['Frequency']
z1 = rfm[rfm['Cluster'] == 1]['MonetaryValue']
x2 = rfm[rfm['Cluster'] == 2]['Recency']
y2 = rfm[rfm['Cluster'] == 2]['Frequency']
z2 = rfm[rfm['Cluster'] == 2]['MonetaryValue']
x3 = rfm[rfm['Cluster'] == 3]['Recency']
y3 = rfm[rfm['Cluster'] == 3]['Frequency']
z3 = rfm[rfm['Cluster'] == 3]['MonetaryValue']
ax1.plot(x0, y0, z0, "o", label="0")
ax1.plot(x1, y1, z1, "o", label="1")
ax1.plot(x2, y2, z2, "o", label="2")
ax1.plot(x3, y3, z3, "o", label="3")
plt.legend(loc="upper left")
ax1.set_xlabel('Recency')
ax1.set_ylabel('Frequency')
ax1.set_zlabel('MonetaryValue')
plt.legend(loc='upper left', fontsize = 20)
plt.show()
너무 겹쳐서 어떤식으로 나눴는지 잘 안보이기 때문에...
분포를 좀 퍼뜨린 rfm_final데이터에 나눈 군집을 넣고 시각화 해보면...
rfm_final['Cluster'] = kmeans.labels_
rfm_finalfrom mpl_toolkits.mplot3d import Axes3D
fig = plt.figure(figsize=(20, 20))
ax1 = plt.subplot(111, projection='3d')
x0 = rfm_final[rfm_final['Cluster'] == 0]['Recency']
y0 = rfm_final[rfm_final['Cluster'] == 0]['Frequency']
z0 = rfm_final[rfm_final['Cluster'] == 0]['MonetaryValue']
x1 = rfm_final[rfm_final['Cluster'] == 1]['Recency']
y1 = rfm_final[rfm_final['Cluster'] == 1]['Frequency']
z1 = rfm_final[rfm_final['Cluster'] == 1]['MonetaryValue']
x2 = rfm_final[rfm_final['Cluster'] == 2]['Recency']
y2 = rfm_final[rfm_final['Cluster'] == 2]['Frequency']
z2 = rfm_final[rfm_final['Cluster'] == 2]['MonetaryValue']
x3 = rfm_final[rfm_final['Cluster'] == 3]['Recency']
y3 = rfm_final[rfm_final['Cluster'] == 3]['Frequency']
z3 = rfm_final[rfm_final['Cluster'] == 3]['MonetaryValue']
ax1.plot(x0, y0, z0, "o", label="0")
ax1.plot(x1, y1, z1, "o", label="1")
ax1.plot(x2, y2, z2, "o", label="2")
ax1.plot(x3, y3, z3, "o", label="3")
plt.legend(loc="upper left")
ax1.set_xlabel('Recency')
ax1.set_ylabel('Frequency')
ax1.set_zlabel('MonetaryValue')
plt.legend(loc='upper left', fontsize = 20)
plt.show()
컴퓨터가 나름 어떤 기준? 을 가지고 나눈 것을 알 수 있었다!
내가 프로젝트에서 해본 것은 요정도이다...
다른 조원분들도 열심히 참여해주셔서...
애플과 삼성 비교?를 위주로 프로젝트를 완성했고...
완성된 결과를 발표한 내용을 보자면...
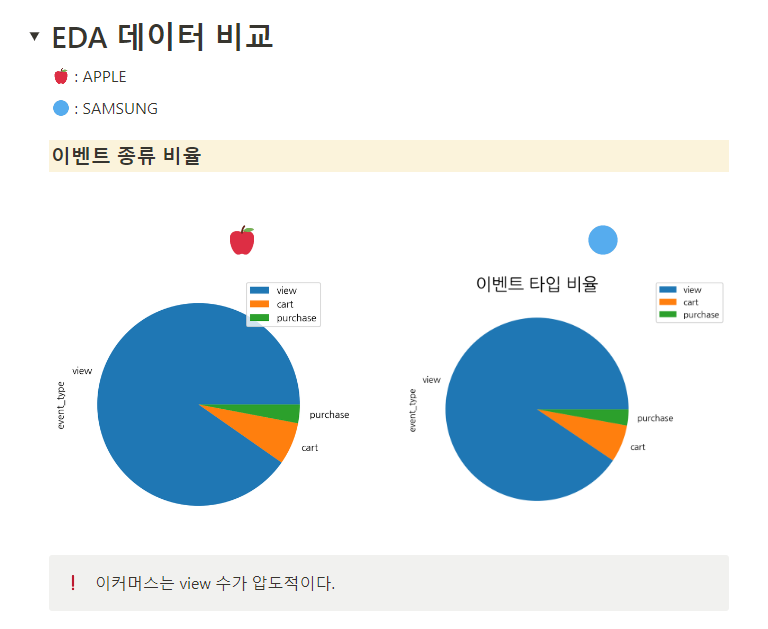
이런 너낌...

이런 너낌...

이런 너낌...
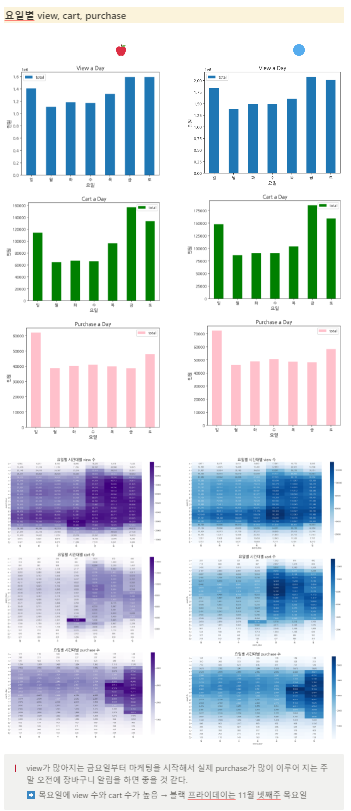
이런 너낌...

이런 너낌...

이런 너낌...

이런 너낌...

이런 너낌...

이런 너낌... 이다...
하나의 일관성있는 인사이트를 주지는 못했지만...
많은 연습을 해봤고...
조원들 모두 알차게 참여하고 성장한 너낌이라...
아주 만족스런 프로젝트였다!!!!
'멋쟁이사자처럼 AI스쿨' 카테고리의 다른 글
| 멋쟁이사자처럼 AI스쿨 13주차 회고 (0) | 2023.03.16 |
|---|---|
| 멋쟁이사자처럼 AI스쿨 12주차 회고 (0) | 2023.03.09 |
| 과제3 심화? (0) | 2023.03.05 |
| 멋쟁이사자처럼 AI스쿨 11주차 회고 (0) | 2023.03.02 |
| 통계 특강5 (0) | 2023.03.02 |




댓글