이번주는 온라인 리테일 데이터 분석 및 시각화와 군집화도 해봤고...
통신사 데이터를 이용한 의사결정나무 분류모델도 만들어봤다!
분석 및 시각화 복습은 미니프로젝트에 남겨두고...
머신러닝 위주의 복습을 해보자!
먼저 온라인 리테일 데이터를 가공한 rfm데이터의 군집화를 해보자!
rfm이란...?
RFM은 가치있는 고객을 추출해내어 이를 기준으로 고객을 분류할 수 있는 매우 간단하면서도 유용하게 사용될 수 있는 방법으로 알려져 있어 마케팅에서 가장 많이 사용되고 있는 분석방법 중 하나이다. RFM은 구매 가능성이 높은 고객을 선정하기 위한 데이터 분석방법으로서, 분석과정을 통해 데이터는 의미있는 정보로 전환된다.
RFM은 Recency, Frequency, Monetary의 약자로 고객의 가치를 다음의 세 가지 기준에 의해 계산하고 있다.
- Recency - 거래의 최근성: 고객이 얼마나 최근에 구입했는가?
- Frequency - 거래빈도: 고객이 얼마나 빈번하게 우리 상품을 구입했나?
- Monetary - 거래규모: 고객이 구입했던 총 금액은 어느 정도인가
출처 : https://ko.wikipedia.org/wiki/RFM
RFM - 위키백과, 우리 모두의 백과사전
위키백과, 우리 모두의 백과사전. RFM은 가치있는 고객을 추출해내어 이를 기준으로 고객을 분류할 수 있는 매우 간단하면서도 유용하게 사용될 수 있는 방법으로 알려져 있어 마케팅에서 가장
ko.wikipedia.org
여기 자세히 나와있습니다!
필요한 것 import하고... 그래프 스타일 설정!
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
sns.set_style("darkgrid")
rfm데이터를 불러오자!
rfm = pd.read_csv('data/rfm_eda.csv', index_col='CustomerID')
rfm
RFM과...
RFM등급,
RFM등급을 문자 그대로 합친 RFM_segment,
RFM등급을 더한 RFM_score,
그리고 RFM_score로 qcut(비슷한 개수만큼 나눔)한 RFM_class 컬럼이 있다!
그럼 rfm으로만 군집화를 해보기 위해... rfm컬럼만 뺴와보자!
rfm_cluster = rfm.iloc[:, :3]
rfm_cluster
RFM만 뽑아왔다!
모든 데이터가 수치형이고 기술통계를 확인해보면...
rfm_cluster.describe()
스케일 값에 차이가 있고...
히스토그램으로 분포를 보면...
rfm_cluster.hist(bins=50);
한쪽으로 쏠려있다...
먼저 한쪽으로 쏠려있는 것을 퍼지게 하려고 로그변환을 하는데...
로그 취하기 전에 먼저 1을 더해줘서 0에 가까운 값이 이상한 분포를 가지지 않게 해주면...
rfm_cluster_log = np.log(rfm_cluster + 1)
rfm_cluster_log
이렇게 변했고...
분포가 좀 퍼진것도 확인해보면...
rfm_cluster_log.hist(bins=50);
아까 확 쏠려 있던 것이 좀 고르게 퍼진 것을 볼 수 있다!
그러나 아까 스케일 값에 문제가 있어서...
평균을 0, 표준편차를 1에 맞춰주는... StandardScaler를 사용하자!
StandardScaler를 적용한 X를 보면...
from sklearn.preprocessing import StandardScaler
ss = StandardScaler()
ss.fit(rfm_cluster_log)
X = ss.transform(rfm_cluster_log)
X

이렇게 array형식이고...
기술 통계를 보면...
pd.DataFrame(X).describe().round(2)
세 변수 모두 평균이 0, 표준편차가 1에 가깝게 잘 스케일링 완료!
이제 KMeans알고리즘을 통한 군집화를 해보자!
KMeans알고리즘에서 몇 개로 나눌까에 대한 판단은 Elbow Method 또는 Silhouette Score으로 판단하는데...
엘보우 메서드와 실루엣 점수 둘다 보려고...
inertia, silhouettes리스트를 만들어주고...
군집의 크기를 2부터 19까지 해줬다!
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_score
inertia = []
silhouettes = []
range_n_clusters = range(2, 20)
for n_cluster in range_n_clusters:
kmeans = KMeans(n_clusters=n_cluster, random_state=42)
kmeans.fit(X)
inertia.append(kmeans.inertia_)
silhouettes.append(silhouette_score(X, labels=kmeans.labels_))
우선 엘보우 메서드부터 시각화해보면...
plt.figure(figsize=(15,4))
plt.plot(range_n_clusters, inertia)
plt.title('The Elbow Method')
plt.xlabel('Number of clusters')
plt.ylabel('Within-Cluster Sum of Square')
plt.xticks(range_n_clusters)
plt.show()
솔직히 군집 개수 몇개가 맞을지 잘 모르겠다는 생각이 든다!
실루엣 점수로 보면...
plt.figure(figsize=(15, 4))
plt.title('Silhouette Score')
plt.plot(range_n_clusters, silhouettes)
plt.xticks(range_n_clusters)
plt.show()
솔직히 잘 모르는 건 마찬가지...
그래서 KElbowVisualizer를 써서 적정 값을 찾아주자!
from yellowbrick.cluster import KElbowVisualizer
KEV = KElbowVisualizer(kmeans, k=10, n_init='auto')
KEV.fit(X)
KEV.show()
적정 값이 5라고 나왔다!
그래서 군집 개수를 5개로 정하고 머신 러닝을 해보자!
n_clusters = 5
kmeans = KMeans(n_clusters=n_clusters, random_state=42)
kmeans.fit(X)
군집의 개수 5개 random_state=42다!
각 군집의 개수를 보면...
pd.Series(kmeans.labels_).value_counts()
요정도로 나뉘었고...
군집의 중심을 보면...
kmeans.cluster_centers_
5개의 군집의 각 중심이 나온다!
이렇게 나눈 군집을 rfm데이터 프레임에 넣어주자!
rfm['Cluster'] = kmeans.labels_
rfm
잘 들어갔다!
그럼 qcut으로 3등분한 기준(platinum, gold, silver)와 5등분한 군집이 어떻게 다른지 확인해보면...
pd.crosstab(rfm['RFM_class'], rfm['Cluster'])
플래티넘이 0에 많이 가있어서 0쪽이 많이 산 고객같고...
실버가 4쪽에 많이 가있어서 4쪽이 덜 산 고객 같다!
이것을 바이올린 플롯으로 시각화해보면...
sns.violinplot(data=rfm, x="Cluster", y="RFM_score", hue="RFM_class");
좀더 직관적으로 볼 수 있는데...
0, 4는 각각 가장 좋은 고객, 가장 덜 좋은 고객은 확실해보이지만...
1,2,3은 정확한 우위를 판단 할 수는 없다는 생각이 들었다!(아마 2, 3, 1 순인 것 같긴 하다!)
pairplot으로 각 군집별 분포와...
각 군집별 변수간의 산점도를 보면...
sns.pairplot(data=rfm, hue='Cluster')
알아보기는 힘들지만 원하는 정보를 얻을 수 있다!
이렇게 rfm군집화를 해봤다!

의사결정나무를 이용한 통신사 이탈율 분류를 해보자!(지도학습)
일단 필요 라이브러리 로드!
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
데이터도 가져와주고 shape을 보면...
df = pd.read_csv("https://bit.ly/telco-csv", index_col='customerID')
print(df.shape)
df
이런 데이터인데...
일단 info()를 보면...
df.info()
결측치는 없다고 나오지만
숫자 데이터인데 object타입인 것(TotalCharges) 안에서
앞뒤에 공백이 있는 것도 있고...
널값인데 공백으로 나와 널값이 표시 안된 것도 있어서...
처리해주면...
df["TotalCharges"] = pd.to_numeric(df["TotalCharges"].str.strip())
df.info()
TotalCharges에서 결측치가 발생했다!
7043개 중 11개의 결측치는 많은 것이 아니기 때문에... 제거해주자!
df = df.dropna()
df.info()
이제 결측치가 없다!
이번에는 우리가 예측할 정답(Churn : 이탈율)의 빈도비율을 확인하면...
df['Churn'].value_counts(1)
유지 73퍼센트, 이탈 27퍼센트 정도이다!
머신러닝에 들어가기 전 수치데이터만 사용할 것이기 때문에...(간단한 모델을 위해서)
feature_names에 수치형 데이터 컬럼의 이름을 넣어주고...
label_name에 예측할 값의 이름을 담아준다!
feature_names = df.select_dtypes(include='number').columns
feature_names
이렇게 수치형인 4개 변수를 사용할 것이고...
label_name = "Churn"
label_name
예측할 변수(이탈율)이다!(범주형)
이제 예측할 데이터를 앞에서 만든 변수 이름을 통해 X(문제 데이터), y(정답 데이터)에 각각 담아주면...
X, y = df[feature_names], df[label_name]
X.shape, y.shape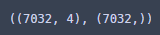
X는 4가지 변수의 데이터프레임, y는 시리즈 형태가 된다!
학습 데이터 80퍼센트, 테스트 데이터 20퍼센트로 나눠주면...
split_count = int(df.shape[0] * 0.8)
X_train = X[:split_count]
X_test = X[split_count:]
X_train.shape, X_test.shape
일단 이렇게 X(문제 데이터)가 8:2비율로 나뉘었고...
y(정답 데이터)도 같은 비율로 나눠준다!
y_train = y[:split_count]
y_test = y[split_count:]
y_train.shape, y_test.shape
본격적으로 머신러닝에 들어가보자!
sklearn의 DecisionTreeClassifier(의사결정나무(분류))를 import하고...
random_state=42로 해서 모델을 만들어줬다!
분류모델을 사용한 것은 예측할 변수가 범주형이라서 그렇다!
from sklearn.tree import DecisionTreeClassifier
model = DecisionTreeClassifier(random_state=42)
model
이제 훈련데이터로 학습시키자!
model.fit(X_train, y_train)
나무의 깊이와 또 결국 몇 가지로 나뉘었는지 보면...
model.get_depth(), model.get_n_leaves()
34의 깊이이고 1296개로 뻗어있다!
이제 테스트 데이터로 예측해보면...
y_predict = model.predict(X_test)예측 완료!
sklearn의 accuracy_score(정확도)로 예측해보면
from sklearn.metrics import accuracy_score
accuracy_score(y_test, y_predict)
72점 정도 맞았다!
의사결정나무는 여러가지 지수로 분류하는데 여기서는 기본값인 지니 불순도로 해봤다!
plot_tree로 깊이 5까지만 시각화해서 분석해보면...
from sklearn.tree import plot_tree
plt.figure(figsize=(20, 20))
plot_tree(model, filled=True, max_depth=5,
fontsize=12, feature_names=feature_names);
제일 첫 기준은 tenure <= 16.5로 총 5625개가 각각 2039개, 3586개로 나뉘었고...
gini불순도는 0.389고...
아래로 가면서 계속 분류를 해서...
아까 살펴봤듯이 34 깊이까지 간다...
이번엔 각 feature의 중요도를 보면...
model.feature_importances_
3번째가 가장 중요한 특징으로 작용했다!
시각화해보면...
sns.barplot(x=model.feature_importances_, y=model.feature_names_in_);
MonthlyCharges가 가장 주요했고 SeniorCitizen이 가장 역할이 적은 변수였다!
모델의 정확도를 높이려 여러가지 하이퍼 파라미터를 설정해줘봤는데...
model_yang = DecisionTreeClassifier(
criterion='entropy',
random_state=729,
max_depth=10,
min_samples_split=10,
min_samples_leaf=5,
min_weight_fraction_leaf=0.03
)
model_yang.fit(X_train, y_train)
y_predict_yang = model_yang.predict(X_test)
accuracy_score(y_test, y_predict_yang)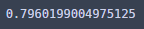
80점 가까이는 갔다!
이번 주는 러닝머신... 이 아닌...
머신러닝을 배웠는데...
예측을 해보는 것이 참 재미있었다!

'멋쟁이사자처럼 AI스쿨' 카테고리의 다른 글
| 멋쟁이사자처럼miniproject3(이커머스 데이터) (0) | 2023.03.19 |
|---|---|
| 멋쟁이사자처럼 AI스쿨 13주차 회고 (0) | 2023.03.16 |
| 과제3 심화? (0) | 2023.03.05 |
| 멋쟁이사자처럼 AI스쿨 11주차 회고 (0) | 2023.03.02 |
| 통계 특강5 (0) | 2023.03.02 |




댓글