이번 주는 미드프로젝트와 쉬는 날이 있어서 좀 수월했다!
그럼 복습해보자!
파일크기 줄이기랑 메모리 부담 줄이기를 배웠다!
먼저 파일크기 줄이기!
Aparche Parquet라는 오픈 소스로 파일 크기를 줄여보자!
아파치 파케이가 csv와 다른 점은 열단위라는 것이다!
그래서 효율적이고 저장공간을 절약할 수 있고...
또 열 값은 동일한 데이터 타입이기 때문에 압축에 유리하다는 특징이 있다!
먼저 아나콘다 프롬프트를 열고...
conda install -c conda-forge fastparquet
conda install -c conda-forge pyarrow
명령어를 통해 설치해준다!
그리고 import
import pandas as pd
import osos는 파일 크기를 확인하기 위해 해줬다!
먼저, 작은 데이터프레임을 각각 csv와 parquet로 저장해 파일크기를 비교해보자!
컬럼1에는 1,2를 넣어줬고 컬럼2에는 3,4를 넣어준 데이터프레임이다!
df = pd.DataFrame(data={'col1': [1, 2], 'col2': [3, 4]})
df.to_parquet('df.parquet.gzip', compression='gzip')
df.to_csv('df-small.csv')
이렇게 각각 저장해 파일 크기를 확인해보면...
format(os.stat('df.parquet.gzip').st_size, ","), format(os.stat('df-small.csv').st_size, ",")
parquet파일이 용량이 더 크다?
=> 작은 파일의 경우 메타정보를 포함하지 않아 파케가 더 비효율적일 수 있다!
그럼 큰 데이터로 확인해보자!
수업에서 제공해준 약품 데이터를 사용했는데...
df = pd.read_csv('data/nhis_drug_sample_2020_3.csv')
df.shape
팔만 대장경을 넘는 31만행의 압박...
csv와 parquet로 각각 저장해보고 파일크기를 확인해 보면...
file_path_parquet = 'data/df.parquet.gzip'
file_path_csv = 'data/df.csv'
df.to_parquet(file_path_parquet, compression='gzip')
df.to_csv(file_path_csv)
format(os.stat(file_path_parquet).st_size, ','), format(os.stat(file_path_csv).st_size, ',')
csv파일이 10배 정도 파일크기가 큰 것을 확인할 수 있다...
이렇게 대용량? 파일에서는 파케이가 효율적이라는 것을 확인했다!
이번에는 파일로드 후 info()을 불러오는 시간을 측정해 볼건데...
먼저 parquet파일
%time pd.read_parquet(file_path_parquet).info()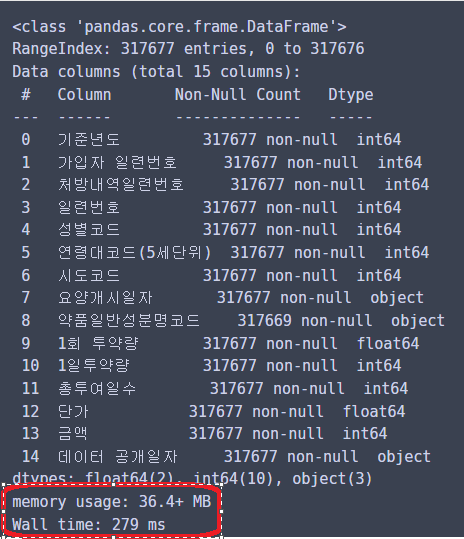
메모리 사용량은 36메가정도...
실행속도는 279밀리 초 정도 걸렸다!
그럼 csv는...?

%time pd.read_csv(file_path_csv).info()메모리 사용량은 39메가에 육박하고...
실행 시간도 536밀리 초로 파케이에 비해 2배 정도 느렸다!
결론 : 큰 데이터에서는 메모리 사용량, 실행 시간에 있어서도... 효율적이니까...
큰 데이터를 다룰 때에는 파케이를 사용해보자!

이번에는 메모리 부담 줄이기(downcast)!
앞서 파일 크기 줄이기에서 사용했던 데이터를 csv파일로 사용해보자!
df = pd.read_csv('data/nhis_drug_sample_2020_3.csv')
df.shape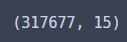
31만행의 압박이란...
info()를 통해 메모리 사용량을 보면...
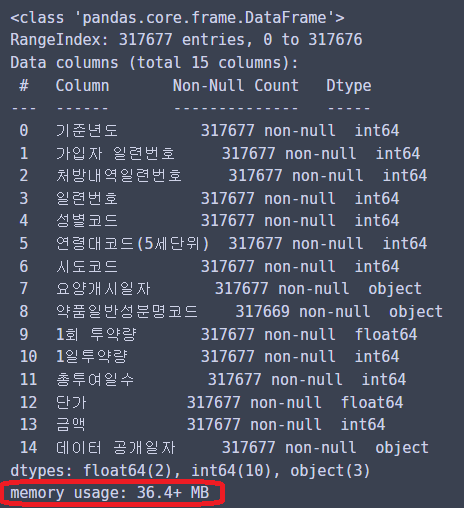
36메가이다!
한번 데이터 타입도 확인해보면...
df.dtypes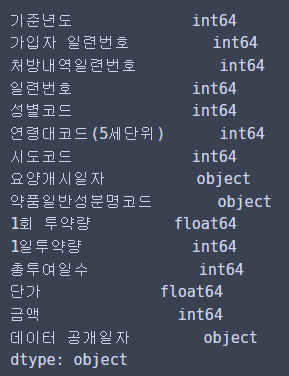
이렇다!
어디서 메모리가 낭비될까?
데이터 타입을 보면... 이렇게 있는데...
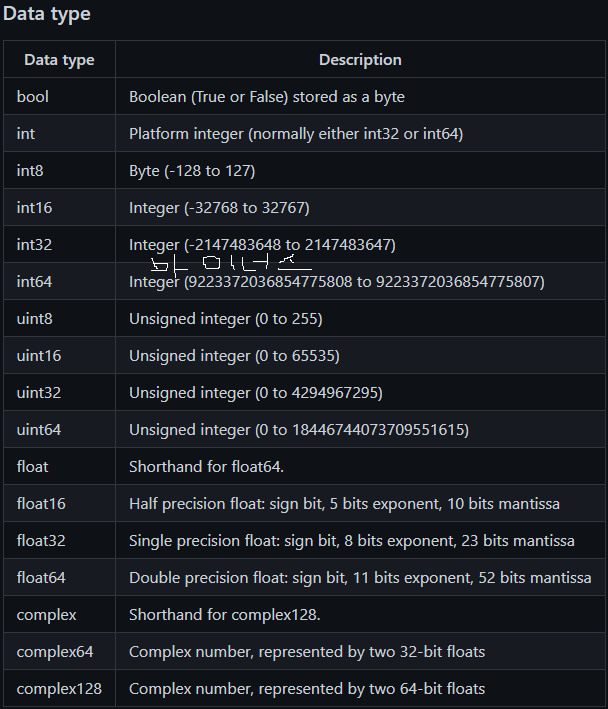
출처 : https://github.com/rougier/numpy-tutorial#quick-references
예를 들자면... 숫자가 1~30까지 밖에 없으면 굳이 int64를 쓸 필요 없이 unit8만 써도 되는 것이다!
수치형 변수 기술통계를 보면...
df.describe()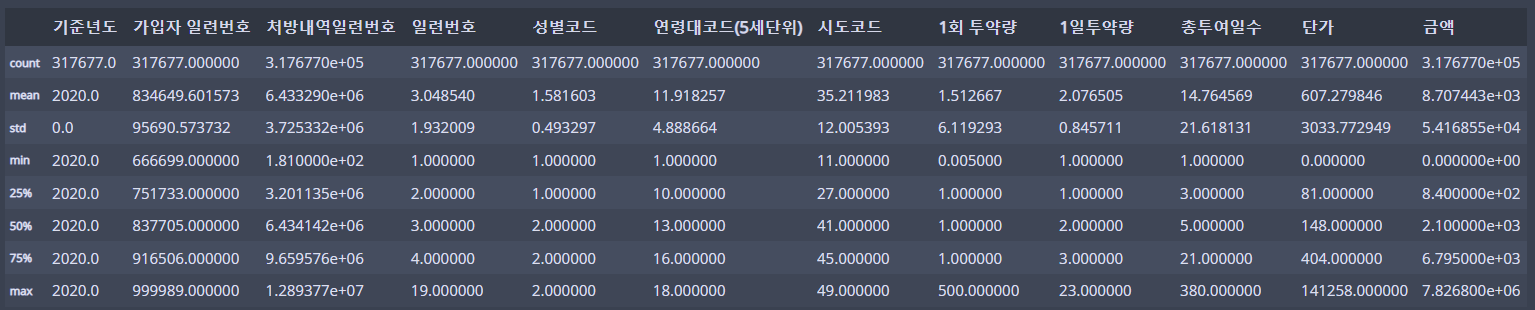
이런데...
모두 float64나 int64로 되어있으니... 메모리가 낭비되고 있던 것!
그럼 수치에 맞게 데이터 타입을 바꿔주면...
# int의 경우 음수가 있으면 int형 없으면 unit형
# float의 경우 float
# object형의 경우 category형으로 downcast!
for col in df.columns:
dtypes_name = df[col].dtypes.name
if dtypes_name.startswith('float'):
df[col] = pd.to_numeric(df[col], downcast='float')
elif dtypes_name.startswith('int'):
if df[col].min() < 0:
df[col] = pd.to_numeric(df[col], downcast='integer')
else:
df[col] = pd.to_numeric(df[col], downcast='unsigned')
elif dtypes_name == 'object':
df[col] = df[col].astype('category')
df.info()
데이터 타입이 잘 변환되어...
메모리 사용량이 10메가로 약 3배 이상 줄었다!
파일 크기를 줄이고...
메모리 부담도 줄여서...
컴퓨터가 안힘들어하게... 해줘야겠다고 생각했다!

'멋쟁이사자처럼 AI스쿨' 카테고리의 다른 글
| 멋쟁이사자처럼 AI스쿨 12주차 회고 (0) | 2023.03.09 |
|---|---|
| 과제3 심화? (0) | 2023.03.05 |
| 통계 특강5 (0) | 2023.03.02 |
| 통계 특강4 (2) | 2023.03.01 |
| 통계 특강3 (2) | 2023.03.01 |




댓글