car데이터를 보자!
import pandas as pd
df = pd.read_excel('data/car.xlsx')
df
주행거리와 가격의 상관관계를 보자!
먼저 산점도로 보면...
sns.scatterplot(x='mileage', y='price', data=df);
가격과 마일리지가 음의 상관관계가 있음을 파악할 수 있다!
수치로도 확인해보면...
pg.corr(df['mileage'], df['price'])
r = -0.67616으로 음의 상관관계를 가진다!
이곳에서도 p-value가 있는데 과연 귀무가설은 무엇일까?
귀무가설은 r=0이다(즉, 상관이 없다)
직 p < 0.05이므로 상관이 있다고 볼 수 있다!
이번엔 연도와 가격의 상관관계를 보자!
연도를 연속형이라고 치고 상관관계를 보자!
산점도로 보면...
sns.scatterplot(x='year', y='price', data=df);
양의 상관관계에 있음을 알 수 있고
수치로 직접확인해 보면...
pg.corr(df['year'], df['price'])
r = 0.828908로 상당한 양의 상관관계임을 알 수있다!
이번엔 마일리지와 다른 차에게 가한 데미지의 상관관계를 보자!
sns.scatterplot(x='mileage', y='other_car_damage', data=df);
관계를 쉽게 파악할 수 없는 그림이다!
수치를 보면...
pg.corr(df['mileage'], df['other_car_damage'])
r이 0에 가깝고 p > 0.05이므로 결론을 유보한다!(상관관계가 없다!)
이번엔 상관행렬로 모든 변수에 대해서 상관계수를 보자!
df.corr()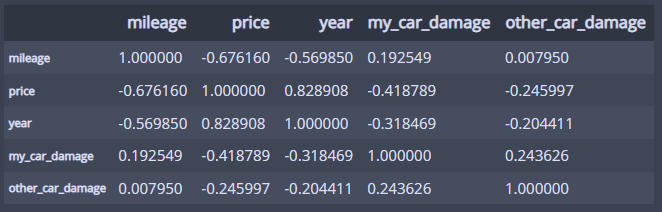
상관행렬의 특징은 대각선은 항상1이고 대각선 기준 대칭이다!
상관행렬은 계산을 상당히 많이한다!
그래서 상관행렬을 볼때는 항상 다중비교문제를 주의해야한다!
다중비교 : 가설에 근거하지 않고 무작정 많은 비교를 하다보면 실제 연관성이 없음에도 불구하고 우연에 의해 연관성이 있는 것처럼 나올 수 있는 문제점
이번에는 2003년부터 2023년까지 월별 금가격이랑 미국주식가격의 데이터로 상관분석을 해보자!
asset = pd.read_excel('data/asset.xlsx')
asset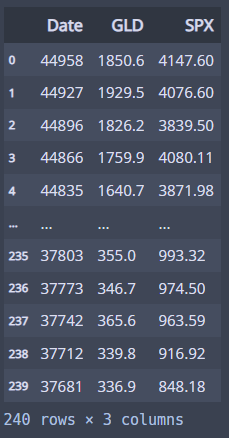
산점도로 그려보면...
sns.scatterplot(x='GLD', y='SPX', data=asset);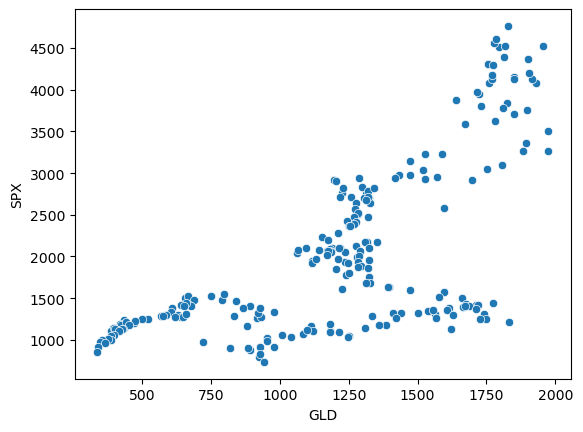
양의 상관관계로 가진 것으로 보인다!
수치로 직접 확인해보면...
pg.corr(asset['GLD'], asset['SPX'])
r=0.686535로 양의 상관관계를 가지고...
p < 0.05이므로 상관이 없다는 귀무가설을 기각하여 상관있다는 결론이 나온다!
그런데 이것은 조금 잘못된 분석인데...
시간에 대해서 산점도를 그려보자!
sns.scatterplot(x='Date', y='GLD', data=asset);
sns.scatterplot(x='Date', y='SPX', data=asset);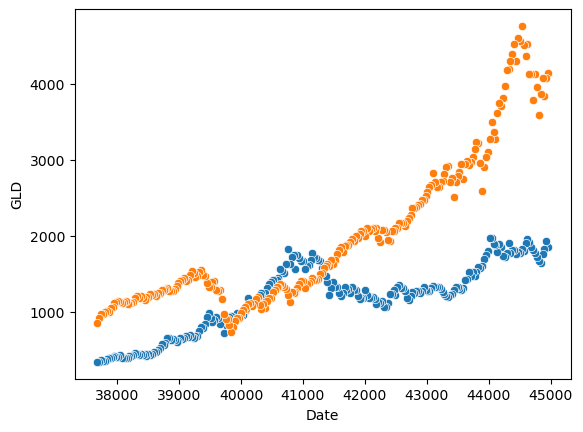
장기적으로 보면 둘 다 오르지만... 살짝 양상이 다른 것을 볼 수 있다!
그럼 pct_change()(차분/이전기간)함수를 통해 그래프를 그려보자!
sns.scatterplot(asset['GLD'].pct_change(), asset['SPX'].pct_change());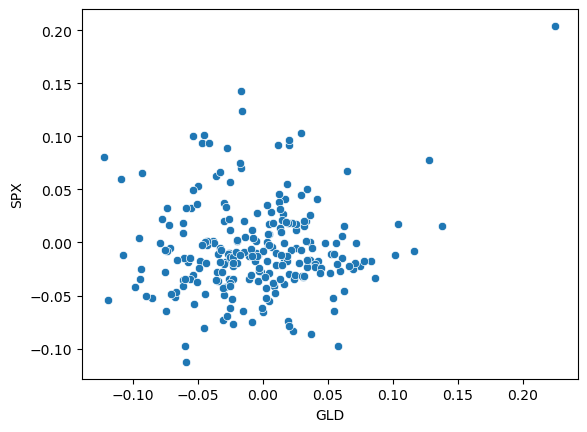
상관이 없는 것으로 보인다?
실제 수치로 사용해보면...
pg.corr(asset['GLD'].pct_change(), asset['SPX'].pct_change())
귀무가설은 주가와 금의 수익률은 상관이 없다이고
p > 0.05이므로 귀무가설 기각을 못한다!
결론을 유보한다!(상관이 없긴 없다!)
이번에는 car데이터로 다른 상관계수를 구해보자!
마일리지와 가격의 산점도는...
이런 식이었고
피어슨 상관계수는 r = -0.67616이었다!
산점도가 오른쪽으로 갈수록 누워있는 형태를 띄고있어서 스피어만 상관계수를 구하면 상관계수의 절대값이 좀 커질것이라고 예상할 수 있다!
스피어만 상관계수를 보면
pg.corr(df['mileage'], df['price'], method='spearman')
r = -0.692834로 절대값이 살짝 커졌다
켄달 상관계수를 구해보자!
pg.corr(df['mileage'], df['price'], method='kendall')
상관계수가 -0.5정도 되는데...
임의로 두 점을 뽑으면 마일리지가 증가했을 때 가격이 내려갈 확률이 75%...
마일리지가 증가했을 때 가격이 오를 확률이 25%라는 의미를 가진다!
요정도로 해보고 주의할 점을 알아보자!
1. 상관관계를 볼 때는 인과관계가 아니라는 것을 주의하자!
2. 심슨의 역설
심슨의 역설 - 위키백과, 우리 모두의 백과사전
위키백과, 우리 모두의 백과사전. 양적 데이터에 관한 심슨의 역설: 두 개의 분리된 그룹에서는 양의 추세가 나타나지만, ( , ) 두 그룹을 합친 경우에는 음의 추세가 나타난다( ) 심슨의 역설(S
ko.wikipedia.org
도 참고해서 주의하자!
3. 벅슨의 역설
Berkson's paradox - Wikipedia
From Wikipedia, the free encyclopedia Tendency to misinterpret statistical experiments involving conditional probabilities An example of Berkson's paradox: In figure 1, assume that talent and attractiveness are uncorrelated in the population. In figure 2,
en.wikipedia.org
도 참고해보자!
4. 이상치때문에 존재하지 않는 상관관계가 나타날 수도 있고 존재하는 상관관계가 희미해질 수도 있다!
'멋쟁이사자처럼 AI스쿨' 카테고리의 다른 글
| 멋쟁이사자처럼 AI스쿨 11주차 회고 (0) | 2023.03.02 |
|---|---|
| 통계 특강5 (0) | 2023.03.02 |
| 통계 특강3 (2) | 2023.03.01 |
| 통계 특강2 (2) | 2023.03.01 |
| 통계 특강1 (0) | 2023.02.16 |




댓글