A high-level API for statistical graphics(통계 그래픽을 위한 고급 API)
일단 필요라이브러리 호출!
# Import seaborn
import seaborn as sns
%matplotlib inline
데이터 셋도 불러오자!
dots = sns.load_dataset("dots")
dots
음... firing rate는 반응속도? 이런거라는데...
무슨 데이터인지는 모르겠다...
seaborn의 relplot을이용해서 dots데이터를 시각화해보자!
조건은...
kind는 line
x는 time
y는 firing_rate
col은 align
hue는 choice
size는 coherence
style은 choice
facet_kws는 dict(sharex=False)
로 설정하면...
dots = sns.load_dataset("dots")
sns.relplot(
data=dots, kind="line",
x="time", y="firing_rate", col="align",
hue="choice", size="coherence", style="choice",
facet_kws=dict(sharex=False),
)
이렇게 시각화 된다!
facet_kws가 잘 이해가 안가서 빼고 실행했더니...
dots = sns.load_dataset("dots")
sns.relplot(
data=dots, kind="line",
x="time", y="firing_rate", col="align",
hue="choice", size="coherence", style="choice"
)
이렇게 x축이 공유된 시각화가 나왔다!
그래서 facet_kws=dict(sharex=False)의 뜻이 x축을 공유하지 않고 그래프를 그린다는 의미로 생각했다!
더 자세히 알아보려고...
facet_kws=dict(sharey=False)로 지정해서 그래프를 그려보면...
dots = sns.load_dataset("dots")
sns.relplot(
data=dots, kind="line",
x="time", y="firing_rate", col="align",
hue="choice", size="coherence", style="choice",
facet_kws=dict(sharey=False)
)
역시 facet_kws=dict(sharey=False)는 y축을 공유하지 않고 그래프를 그려줬다!
facet_kws=dict(sharex=False)와
facet_kws=dict(sharey=False)의
좀 더 정확한 의미로는 x축, y축 간격을 자동으로 조절해 준다는 의미인 것 같다!
Statistical estimation(통계적 추정)
이번에는 fmri데이터 셋을 불러와보자!
fmri = sns.load_dataset("fmri")
fmri
역시나 무슨 데이터인지는 모르겠다...
아래 코드와 같이 조건을 걸어주고 relplot으로 시각화해보면...
sns.relplot(
data=fmri, kind="line",
x="timepoint", y="signal", col="region",
hue="event", style="event",
)
이렇게 신기하게도 추정의 불확실성을 나타내는 연한 부분도 같이 그려준다!
이번엔
2023.02.04 - [재미로 하는 코딩] - 시각화 뽀개기1
시각화 쪼개기1
An introduction to seaborn 일단 seaborn으로 차근차근 그래프를 그려보자! 일단 필요한 seaborn라이브러리를 호출! # Import seaborn import seaborn as sns %matplotlib inline # 그래프 출력 안됨문제 해결하기 위해 그리
helpming.tistory.com
에서 활용한 tips데이터를 활용해
x는 total_bill
y는 tip
그리고 시간( Lunch, Dinner)으로 나눠서
lmplot을 그려보면...
tips = sns.load_dataset("tips")
sns.lmplot(data=tips, x="total_bill", y="tip", col="time", hue="smoker")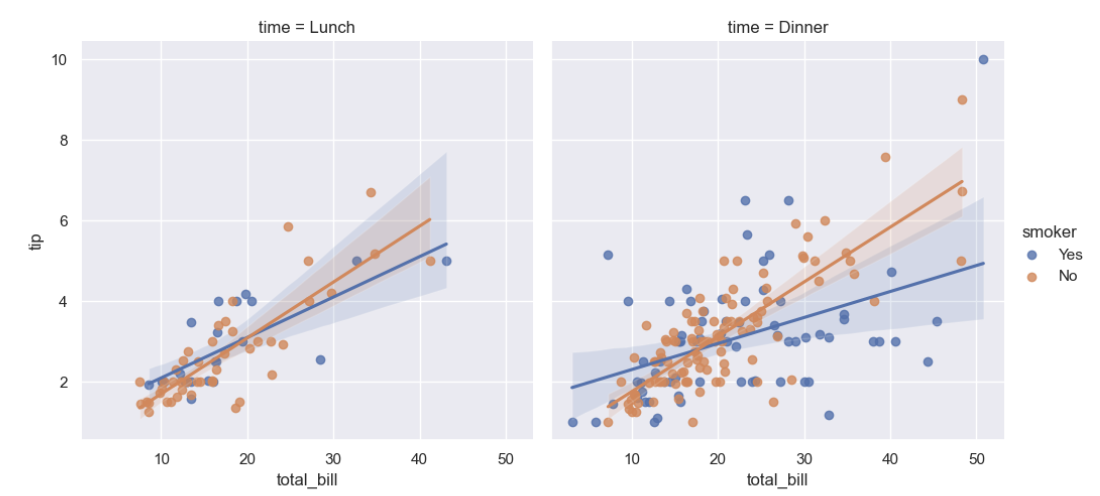
산점도에 더해 선형 회기 모델을 포함해 주는 것을 확인할 수 있다!
Distributional representations(분포 표현)
이번엔 tips데이터로 displot을 그려보자!
x축을 total_bill로 해서
time(Lunch, Dinner)으로 나눠 그려보면...
sns.displot(data=tips, x="total_bill", col="time", kde=True)

kde=True 기능이 분포도를 따라 kde곡선을 그려주는 것을 확인할 수 있다!
다음으로 누적분포함수를 그려보자!
역시 x축에 total_bill을 놓고
time에 따라 나눠그렸다!
sns.displot(data=tips, kind="ecdf", x="total_bill", col="time", hue="smoker", rug=True)
kind='ecdf'를 통해 누적분포를 그린 것을 알 수 있고...
또 rug=True는 개별 관측치를 x축 바로 위에 표시해준 것을 확인할 수 있다!
Plots for categorical data(범주형 데이터에 대한 플롯)
이번엔 tips데이터로 catplot을 그려보자!
x에 day
y에 total_billd을 넣었다!
sns.catplot(data=tips, x="day", y="total_bill", hue="smoker")
이렇게 점의 형태로 분포를 볼 수 있는데...
점이 겹치는 것이 있다!
이번엔 catplot을 kind='swarm'으로 해서 그려보자!
sns.catplot(data=tips, kind="swarm", x="day", y="total_bill", hue="smoker")
점이 하나도 안겹치게 그려진다!
그 다음 kind='violin'으로 그려보자!
sns.catplot(data=tips, kind="violin", x="day", y="total_bill", hue="smoker")
이렇게 그려진다!
split=True로 지정해주면 양념반 후라이드반 마냥 그려진다!
sns.catplot(data=tips, kind="violin", x="day", y="total_bill", hue="smoker", split=True)
마지막으로 catplot을 kind='bar'로 해서 그려보자!

이렇게 그냥 막대로 그려진다!
참조 사이트
https://seaborn.pydata.org/tutorial/introduction.html#a-high-level-api-for-statistical-graphics
An introduction to seaborn — seaborn 0.12.2 documentation
An introduction to seaborn Seaborn is a library for making statistical graphics in Python. It builds on top of matplotlib and integrates closely with pandas data structures. Seaborn helps you explore and understand your data. Its plotting functions operate
seaborn.pydata.org
'재미로 하는 코딩' 카테고리의 다른 글
| 시각화 뽀개기4 (0) | 2023.02.05 |
|---|---|
| 시각화 뽀개기3 (0) | 2023.02.05 |
| 시각화 뽀개기1 (0) | 2023.02.04 |
| 네이버 영화별 평점 수집해보기 (0) | 2023.01.15 |
| 네이버 웹 스크래핑 해보기 (0) | 2023.01.10 |




댓글