
영화보러 갈 사람...?
같이 영화볼 사람이 없네여...
하지만 수집할 데이터는 많쥬...

오늘은 이렇게 영화마다 페이지의 평점을 모두 수집해보는 컨텐츠입니다!
일단 제가 좋아하는 21그램
https://www.netflix.com/title/60031261
21그램 | 넷플릭스
서로 아는 사이는 아니지만, 비극적인 자동차 사고로 인해 얽히게 된 세 사람. 가장 어두운 두려움을 마주하고 삶에 대해 다시 생각해 구원을 찾아야만 한다.
www.netflix.com
페이지 평점을 수집해 보쥬!
일단 평점있는 곳에서 검사를 클릭하고...

네트워크, 문서 페이지에서
이름창 2번째에서 요청 URL을 확인합니다!

요청 URL을 주소창에 복붙하고 엔터!

그러면 이렇게 평점만 있는 페이지가 나오네여 ㅎㅎ
이제 그럼... 데이터 수집 시작!
일단 검사 페이지 네트워크, 문서에서

get인걸 확인

headers에 넣을 것도 확인 후!
코드를 이러쿵저러쿵...
import requests
from bs4 import BeautifulSoup as bs
import pandas as pd
url = 'https://movie.naver.com/movie/bi/mi/pointWriteFormList.naver?code=37951'
url = f'{url}&type=after&isActualPointWriteExecute=false&isMileage'
url = f'{url}SubscriptionAlready=false&isMileageSubscriptionReject=false'
headers = {'user-agent' : 'Mozilla/5.0'}
response = requests.get(url, headers=headers)
html = bs(response.text)
html일단 여기까지 하고 실행하고...
스크롤을 좀 내려보면...

이렇게 평점과 내용...(아이디는 수집하지 않겠습니다!)
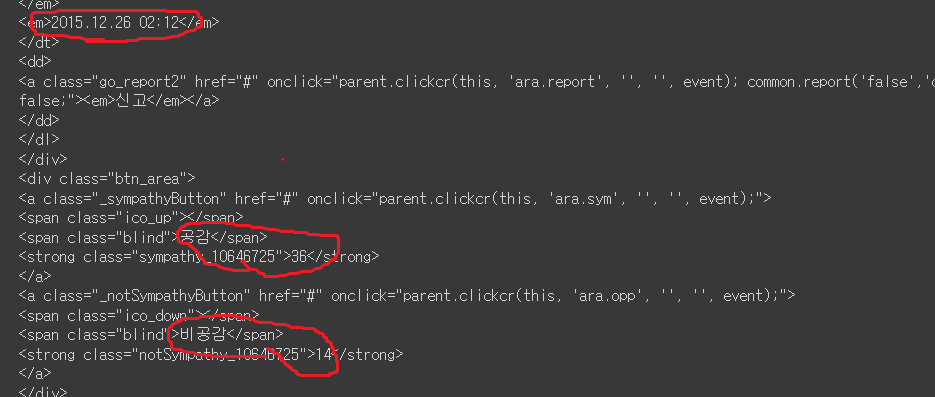
날짜, 공감수, 비공감수가 나오네여...
그럼 검사페이지에서 셀렉터복사를 통해 평점, 내용, 공감수, 비공감수를 뽑아봅시다!
먼저 평점
html.select(' div > div > div > ul > li > div > em')
그다음 내용!
html.select('#_filtered_ment_0')
날짜는...?
html.select('div > div > div > ul > li > div > dl > dt > em')
마지막으로 공감수와 비공감수
html.select('div > div > div > ul > li > div > a > strong')
이렇게 데이터를 뽑아봤습니다...
이제 코드를 합치고 정리해서 이쁘게 뽑아봐야겠쥬?
먼저 평점만 예쁘게 리스트로 뽑아봅시다!
ratings = []
for rating in html.select(' div > div > div > ul > li > div > em'):
ratings.append(int(bs.get_text(rating))) #태그제거 후 정수로 변환
ratings이렇게 하면...

평점만 잘 나오게 됩니다!
이제 내용!
contents = []
for content in html.select('div > div > div > ul > li > div > p'):
contents.append(bs.get_text(content).strip())
contents
그 다음 날짜!
dates = []
for date in html.select('div > div > div > ul > li > div > dl > dt > em'):
dates.append(bs.get_text(date))
dates[1::2]
마지막으로 공감수, 비공감수!
sympathies_and_notsympathies = []
for sympathy in html.select('div > div > div > ul > li > div > a > strong'):
sympathies_and_notsympathies.append(bs.get_text(sympathy))
sympathies = sympathies_and_notsympathies[::2]
notsympathies = sympathies_and_notsympathies[1::2]
sympathies, notsympathies
이제 모두 합쳐서 데이터프레임으로 만들면...
df_page = pd.DataFrame({'평점' : ratings,
'내용' : contents,
'날짜' : dates,
'공감' : sympathies,
'비공감' :notsympathies}
)
df_page
깔쌈합니더 ㅎㄷㄷ...
이제 코드를 모두 모아모아
영화 마다 원하는 페이지를 수집하는 것을 함수로 만들어버리면!
import requests
from bs4 import BeautifulSoup as bs
import pandas as pd
def get_one_page(movie_code, page_no):
url = 'https://movie.naver.com/movie/bi/mi/pointWriteFormList.'
url = f'{url}naver?code={movie_code}&type=after&'
url = f'{url}isActualPointWriteExecute=false&isMileage'
url = f'{url}isMileageSubscriptionReject=false&page={page_no}'
headers = {'user-agent' : 'Mozilla/5.0'}
response = requests.get(url, headers=headers)
html = bs(response.text)
ratings = []
for rating in html.select(' div > div > div > ul > li > div > em'):
ratings.append(int(bs.get_text(rating)))
contents = []
for content in html.select('div > div > div > ul > li > div > p'):
contents.append(bs.get_text(content).strip())
dates = []
for date in html.select('div > div > div > ul > li > div > dl > dt > em'):
dates.append(bs.get_text(date))
dates = dates[1::2]
sympathies_and_notsympathies = []
for sympathy in html.select('div > div > div > ul > li > div > a > strong'):
sympathies_and_notsympathies.append(bs.get_text(sympathy))
sympathies = sympathies_and_notsympathies[::2]
notsympathies = sympathies_and_notsympathies[1::2]
df_page = pd.DataFrame({'평점' : ratings,
'내용' : contents,
'날짜' : dates,
'공감' : sympathies,
'비공감' :notsympathies}
)
return df_page
get_one_page('37951', 1)이렇게 작성해서 함수에 21그램의 코드와, 페이지 수를 넣어주면!

이렇게 잘 나옵니다!
이제 모든 페이지를 수집해야하니까...
끝 페이지 번호를 알아내서 반복문으로 돌려야겠쥬?

그런데 이 페이지는 아쉽게도 끝페이지로 가는 링크가 없네여...
BUT
아래처럼 총 글의 개수가 있네여!

한 페이지에 10개니까...
총 글의 개수를 추출해서...
나누기10 한거에다 10으로 나눈 나머지가 없으면 그대로 있으면 플러스 1을 하면 깔끔하쥬?
그럼 코드를 작성해봅시다!
def get_end_page(movie_code):
url = 'https://movie.naver.com/movie/bi/mi/pointWriteFormList.'
url = f'{url}naver?code={movie_code}&type=after&'
url = f'{url}isActualPointWriteExecute=false&isMileage'
url_for_end = f'{url}isMileageSubscriptionReject=false&'
headers = {'user-agent' : 'Mozilla/5.0'}
response = requests.get(url, headers=headers)
html = bs(response.text)
total_num = bs.get_text(html.select('div > div > div > strong')[0])
total_num = total_num.lstrip('관람객 평점').rstrip('건내 평점 등록')
total_num = int(total_num)
if total_num % 10 == 0:
end_page = total_num // 10
else:
end_page = total_num // 10 + 1
return end_page
get_end_page('37951')페이지 수는?

총 823개의 평점이 등록되어 있으니 83페이지가 맞네유
끝페이지를 구했으니...
반복문을 돌리고...
함수를 합쳐서...
평점을 몽땅 긁어와 저장하고 다시 읽어와 봅시다!

중간에 이런게 있어서 내용에 포함되더라구요...

이렇게요!!
이유를 찾아본 결과 관람객 평점이 네티즌 평점에 포함되는데 그것을 표시해준 것 같습니다!

그래서 이런것들도 처리해줬습니다!
import requests
from bs4 import BeautifulSoup as bs
import pandas as pd
def get_end_page(movie_code):
url = 'https://movie.naver.com/movie/bi/mi/pointWriteFormList.'
url = f'{url}naver?code={movie_code}&type=after&'
url = f'{url}isActualPointWriteExecute=false&isMileage'
url_for_end = f'{url}isMileageSubscriptionReject=false&'
headers = {'user-agent' : 'Mozilla/5.0'}
response = requests.get(url, headers=headers)
html = bs(response.text)
total_num = bs.get_text(html.select('div > div > div > strong')[0])
total_num = total_num.lstrip('관람객 평점').rstrip('건내 평점 등록')
total_num = int(total_num)
if total_num % 10 == 0:
end_page = total_num // 10
else:
end_page = total_num // 10 + 1
return end_page
def get_all_pages(movie_code, movie_name):
df_pages = []
for page_no in range(1, get_end_page(movie_code) + 1):
url = 'https://movie.naver.com/movie/bi/mi/pointWriteFormList.'
url = f'{url}naver?code={movie_code}&type=after&'
url = f'{url}isActualPointWriteExecute=false&isMileage'
url = f'{url}isMileageSubscriptionReject=false&page={page_no}'
headers = {'user-agent' : 'Mozilla/5.0'}
response = requests.get(url, headers=headers)
html = bs(response.text)
ratings = []
for rating in html.select(' div > div > div > ul > li > div > em'):
ratings.append(int(bs.get_text(rating)))
contents = []
for content in html.select('div > div > div > ul > li > div > p'):
strip_thing = '관람객\n\n\r\n\t\t\t\t\t\t\t\t\t\t\t\t\t\t\r\n\t\t\t'
strip_thing = f'{strip_thing}\t\t\t\t\t\t\t\t\t\t\t\t\r\n\t\t\t\t\t'
strip_thing = f'{strip_thing}\t\t\t\t\t\t\t\t\t\t\r\n\t\t\t\t\t\t\t'
strip_thing = f'{strip_thing}\t\t\t\t\t\t\t\t\t'
contents.append(bs.get_text(content).strip().lstrip(strip_thing))
dates = []
raw1 = html.select('div > div > div > ul > li > div > dl > dt > em')
for date in raw1:
dates.append(bs.get_text(date))
dates = dates[1::2]
sympathies_and_notsympathies = []
raw2 = html.select('div > div > div > ul > li > div > a > strong')
for sympathy in raw2:
sympathies_and_notsympathies.append(bs.get_text(sympathy))
sympathies = sympathies_and_notsympathies[::2]
notsympathies = sympathies_and_notsympathies[1::2]
df_page = pd.DataFrame({'평점' : ratings,
'내용' : contents,
'날짜' : dates,
'공감' : sympathies,
'비공감' :notsympathies}
)
df_pages.append(df_page)
df_pages = pd.concat(df_pages)
file_name = f'{movie_name}_{movie_code}_ratings.csv'
df_pages.to_csv(file_name, index=False)
return pd.read_csv(file_name)
get_all_pages('37951', '21그램')짜잔...!

영화 21그램의 모든 평점이 불러와졌고... 아까 관램객이 내용에 나오던 모습도 해결된 모습!
이제 딴 영화도 한번 해볼까요?
제가 좋아하는 초속5센티미터의 평점을 수집해보쥬!!!

우선 영화코드는 이렇네여!

흠... 평점 총 개수 안에 세자리마다 ,가 포함이였군요...
이것을 처리해줘야겠죠...
total_num = total_num.replace(',','')이렇게 콤마를 없애주는 코드를 삽입해주고 실행하면!
import requests
from bs4 import BeautifulSoup as bs
import pandas as pd
def get_end_page(movie_code):
url = 'https://movie.naver.com/movie/bi/mi/pointWriteFormList.'
url = f'{url}naver?code={movie_code}&type=after&'
url = f'{url}isActualPointWriteExecute=false&isMileage'
url_for_end = f'{url}isMileageSubscriptionReject=false&'
headers = {'user-agent' : 'Mozilla/5.0'}
response = requests.get(url, headers=headers)
html = bs(response.text)
total_num = bs.get_text(html.select('div > div > div > strong')[0])
total_num = total_num.lstrip('관람객 평점').rstrip('건내 평점 등록')
total_num = total_num.replace(',','')
total_num = int(total_num)
if total_num % 10 == 0:
end_page = total_num // 10
else:
end_page = total_num // 10 + 1
return end_page
def get_all_pages(movie_code, movie_name):
df_pages = []
for page_no in range(1, get_end_page(movie_code) + 1):
url = 'https://movie.naver.com/movie/bi/mi/pointWriteFormList.'
url = f'{url}naver?code={movie_code}&type=after&'
url = f'{url}isActualPointWriteExecute=false&isMileage'
url = f'{url}isMileageSubscriptionReject=false&page={page_no}'
headers = {'user-agent' : 'Mozilla/5.0'}
response = requests.get(url, headers=headers)
html = bs(response.text)
ratings = []
for rating in html.select(' div > div > div > ul > li > div > em'):
ratings.append(int(bs.get_text(rating)))
contents = []
for content in html.select('div > div > div > ul > li > div > p'):
strip_thing = '관람객\n\n\r\n\t\t\t\t\t\t\t\t\t\t\t\t\t\t\r\n\t\t\t'
strip_thing = f'{strip_thing}\t\t\t\t\t\t\t\t\t\t\t\t\r\n\t\t\t\t\t'
strip_thing = f'{strip_thing}\t\t\t\t\t\t\t\t\t\t\r\n\t\t\t\t\t\t\t'
strip_thing = f'{strip_thing}\t\t\t\t\t\t\t\t\t'
contents.append(bs.get_text(content).strip().lstrip(strip_thing))
dates = []
raw1 = html.select('div > div > div > ul > li > div > dl > dt > em')
for date in raw1:
dates.append(bs.get_text(date))
dates = dates[1::2]
sympathies_and_notsympathies = []
raw2 = html.select('div > div > div > ul > li > div > a > strong')
for sympathy in raw2:
sympathies_and_notsympathies.append(bs.get_text(sympathy))
sympathies = sympathies_and_notsympathies[::2]
notsympathies = sympathies_and_notsympathies[1::2]
df_page = pd.DataFrame({'평점' : ratings,
'내용' : contents,
'날짜' : dates,
'공감' : sympathies,
'비공감' :notsympathies}
)
df_pages.append(df_page)
df_pages = pd.concat(df_pages)
file_name = f'{movie_name}_{movie_code}_ratings.csv'
df_pages.to_csv(file_name, index=False)
return pd.read_csv(file_name)
get_all_pages('66820', '초속5센티미터')
이렇게 평점들을 잘 수집했네여!
오늘은 네이버 영화별로 평점을 수집해보는 컨텐츠였습니다!
후우 이 데이터들로 재미있는 것들을 할 수 있겠지만...
더 배우고 해봐야겠습니다!
그럼 ㅂㅇ루

'재미로 하는 코딩' 카테고리의 다른 글
| 시각화 뽀개기2 (0) | 2023.02.04 |
|---|---|
| 시각화 뽀개기1 (0) | 2023.02.04 |
| 네이버 웹 스크래핑 해보기 (0) | 2023.01.10 |
| 로또가 당첨되려면 몇 번 뽑아야할까? (0) | 2023.01.09 |
| 정규표현식을 사용한 여러가지 유효성 검사 (3) | 2022.12.29 |




댓글