오늘은 네이버 웹툰의 베스트도전 페이지를 웹 스크래핑 해보기로 결정했습니다...
왜냐면...?
수업 실습 내용이랑 비슷하기 때문이쥬...ㅋㅋㅋ
일단 네이버 베스트도전 url은 아래와 같습니다...
https://comic.naver.com/genre/bestChallenge
네이버 웹툰 : 베스트도전만화
인기 도전만화를 만나보세요!
comic.naver.com
페이지 윗부분 입니다!

페이지 아랫부분은 이렇네여...

웹툰들이 번호가 넘어가면서 쓰여져 있네여...(오늘 배운 내용이랑 유사함)
일단 여러 페이지를 스크래핑 하려면 url을 알아야 하는데요!
웹툰들이 있는곳에 마우스 커서를 놓은 뒤...
마우스 오른쪽 버튼을 누르고 검사를 클릭합니다!

검사를 클릭하면...
아래와 같은 창이 뜨는데여...
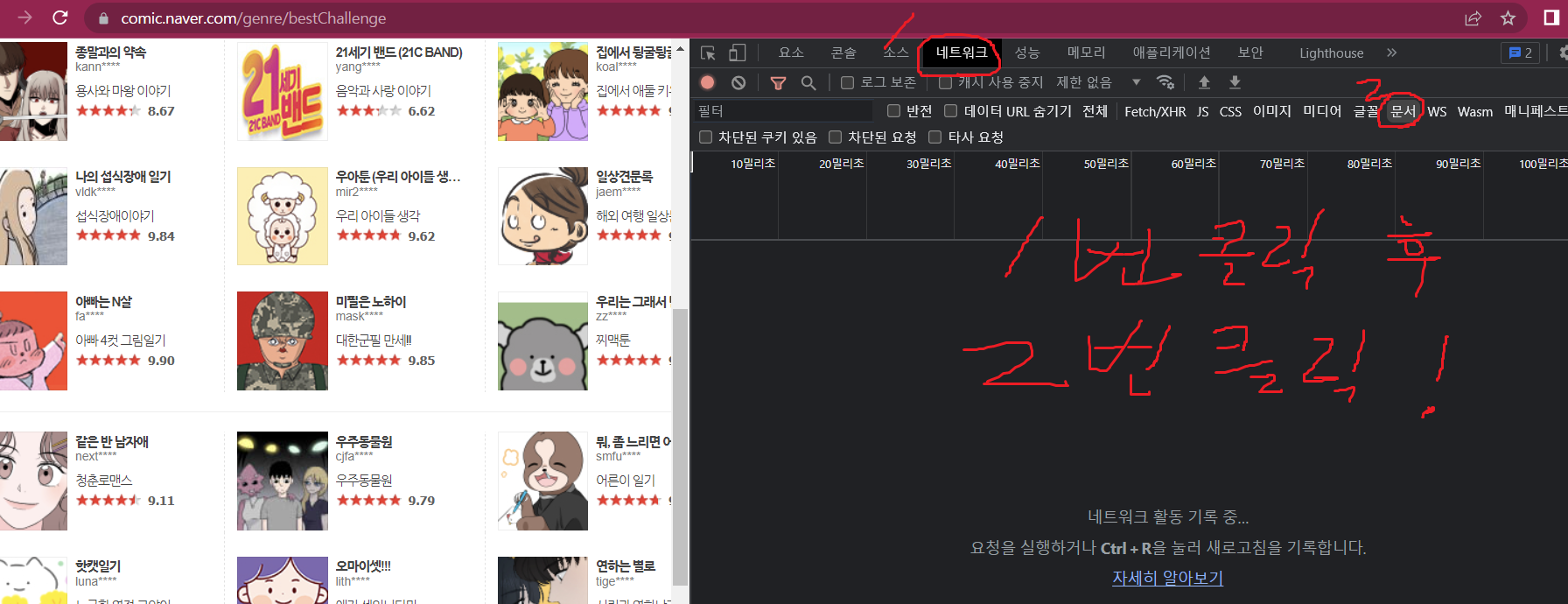
네트워크를 누룬 후 문서를 눌러주세요!
아무것도 나오지 않는다면...
화면창을 아래로 내려서...
번호를 클릭해주세요!

그러면 아래와 같은 창이 뜨고...

빨간 동그라미 부분을 클릭해주세요!
그러면 아래와 같이 요청 URL이 나오게 됩니다!

그러면 pd.read_html()을 이용해서 한 번 데이터를 뽑아봅시다!
import pandas as pd
url = 'https://comic.naver.com/genre/bestChallenge?&page=2'
table = pd.read_html(url)
table이렇게 코드를 작성해 주면...

이렇게 웹툰 제목, 작가아이디, 주제, 평점... 이 나옵니다!
총 24개의 웹툰이 리스트 2개에 담겨져 있네요...
이걸 어떻게 출력할까 하다가...
일단... 리스트 원소 두 개를 따로 출력해 봤습니다...
display(table[0])
display(table[1])그나마 보기가 낫네여...

찬찬히 살펴보다가...
table[0].iloc[0,0]이렇게 하면...
웹툰 하나의 정보가 나오네여...

그리고 띄어쓰기 2개로 항목들이 나눠진 것 같아서...
table[0].iloc[0,0].split(' ')이렇게 하니까...

항목들이 리스트안에 예쁘게 담겼네여...
이제 이짓을 각 웹툰마다 한 뒤...
각 페이지 마다 하면... 됩니다...

일단 한 페이지에 있는 웹툰으로 데이터프레임을 만들어 보쥬!!!
list = []
for i in range(0,4):
for j in [0, 2, 4]: # 열에서 NaN값은 빼고 가져옴...
list.append(table[0].iloc[i,j].split(' '))
list이렇게 하면 table[0]에 있던 데이터가 이쁘게 담기네여 ㅎㅎ

table[1]에 있던 데이터도 담으면 한 페이지의 웹툰 데이터가 모두 담기게 됩니다.
이렇게 3중 for문...?을 쓰면...
list = []
for k in [0, 1]:
for i in range(0,4):
for j in [0, 2, 4]: # 열에서 NaN값은 빼고 가져옴...
list.append(table[k].iloc[i,j].split(' '))
list한 페이지 웹툰의 데이터가 모두 담기게 됩니다!

이제 pd.DataFrame으로 데이터 프레임을 만들어 봅시다!!
df = pd.DataFrame(list)
df데이터프레임 완성!!

총 24개의 웹툰의 데이터가 정리되었습니다!!!
이제 컬럼의 이름을 넣어봅시다.
순서대로 제목, 작가ID, 주제, 평점으로 찬 줄은 드랍, 평점 이런 식으로 만들어 보겠습니다.
df = df.drop(columns = 3)
df.columns = ['제목', '작가ID', '주제', '평점']
df이렇게 하면...

굿잡! 입니다...
이제 이 과정과... 여러 페이지를 바꿀수 있는 코드을... 함수로 만들어 봅시다!
먼저 페이지마다 URL을 얻는 함수를 만들어 봅시다!
import pandas as pd
def get_url(page_no):
url = f'https://comic.naver.com/genre/bestChallenge?&page={page_no}'
return url
get_url(1)이렇게 함수를 작성한뒤...
페이지1을 불러오면...

url이 나오네여!
이제 페이지의 웹툰 데이터를 출력해주는 과정을 함수로 바꿔봅시다!
앞서 작성한 것을 복붙... 복붙... 해서...
def get_one_page_webtoon(page_no):
webtoon_url = get_url(page_no)
webtoon_table = pd.read_html(webtoon_url)
webtoon_list = []
for k in [0, 1]:
for i in range(0,4):
for j in [0, 2, 4]:
webtoon_list.append(webtoon_table[k].iloc[i,j].split(' '))
webtoon_df = pd.DataFrame(webtoon_list)
webtoon_df = webtoon_df.drop(columns = 3)
webtoon_df.columns = ['제목', '작가ID', '주제', '평점']
return webtoon_df
get_one_page_webtoon(1)페이지1을 출력해보면...

이렇게 잘 나온답니다!!
저는 10페이지까지 쓸건데...
3, 7, 9페이지가 오류가 뜨더라고요...

이렇게 오류가 컬럼길이가 맞지 않는다는 오류가 떠서...
오류난 코드를 빼고 확인해보니까...

이렇게 포텐업이 떠있는 작품은 한개씩 밀리더군요...

그래서... 포텐업이 떠있는 행은 삭제하기로 합니다...ㅜㅜ
관찰을 더 해보니...

이렇게 정식연재가 붙어있는 작품도 컬럼이 한개씩 밀려서...
이것도 삭제합니다...
코드를 추가해서...
def get_one_page_webtoon(page_no):
webtoon_url = get_url(page_no)
webtoon_table = pd.read_html(webtoon_url)
webtoon_list = []
for k in [0, 1]:
for i in range(0,4):
for j in [0, 2, 4]:
webtoon_list.append(webtoon_table[k].iloc[i,j].split(' '))
webtoon_df = pd.DataFrame(webtoon_list)
webtoon_df = webtoon_df[~webtoon_df[0].str.contains('포텐업')&
~webtoon_df[0].str.contains('정식연재')]
# 포텐업, 정식연재 작품 제외
webtoon_df = webtoon_df.iloc[:,:5] # 다섯번쨰 컬럼까지만 표시
webtoon_df = webtoon_df.drop(columns = 3)
webtoon_df.columns = ['제목', '작가ID', '주제', '평점']
return webtoon_df
get_one_page_webtoon(3)
포텐업, 정식연재가 들어간 행은 삭제하고!
마지막 결측치 덩어리인 컬럼도 삭제하면!

모든 페이지가 잘 나오게 됩니다!(7번 인덱스(포텐업)가 삭제된 것을 볼 수 있다!)
그럼 반복문으로 10페이지까지 수집해보면...
import time
from tqdm import trange
page_no = 10
webtoon_page_list = []
for i in trange(page_no):
webtoon_page_list.append(get_one_page_webtoon(i+1))
time.sleep(0.1)
webtoon_page_list
이렇게 잘 출력이 됩니다.
이제 데이터프레임들의 리스트를 하나의 데이터프레임으로 합치고 파일로 저장해봅시다!
df_webtoon_all = pd.concat(webtoon_page_list)
df_webtoon_all = df_webtoon_all.reset_index(drop = True)
df_webtoon_all.to_csv('webtoon_list_all', index = False)
이렇게 파일이 생기네여...
다시 파일을 읽어와서 데이터프레임을 확인해보면...
pd.read_csv('webtoon_list_1to10')
이렇게 잘 읽히네여...
오늘은 네이버 베스트도전 웹툰 페이지를 스크래핑 해봤는데여...
우여곡절을 겪으니 지칩니다...
그럼 다음에 더 좋은 컨텐츠로 돌아오겠습니다...

'재미로 하는 코딩' 카테고리의 다른 글
| 시각화 뽀개기1 (0) | 2023.02.04 |
|---|---|
| 네이버 영화별 평점 수집해보기 (0) | 2023.01.15 |
| 로또가 당첨되려면 몇 번 뽑아야할까? (0) | 2023.01.09 |
| 정규표현식을 사용한 여러가지 유효성 검사 (3) | 2022.12.29 |
| open API를 통해 코로나 감염현황을 알아보자 (0) | 2022.12.27 |




댓글