머신러닝 스터디에서 데이콘 자동차 가격 예측 대회를 참여해봤다!
대회 링크
https://dacon.io/competitions/official/236114/overview/description
데이콘 Basic 자동차 가격 예측 AI 경진대회 - DACON
분석시각화 대회 코드 공유 게시물은 내용 확인 후 좋아요(투표) 가능합니다.
dacon.io
트레인 데이터셋은
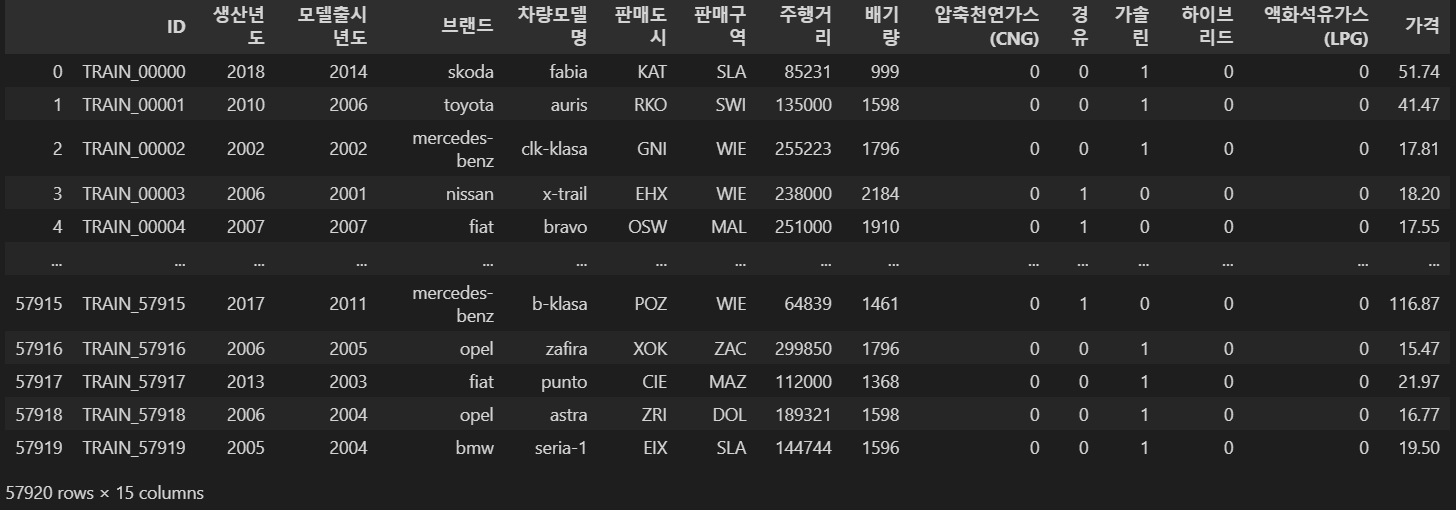
57920행이고...
테스트 데이터셋은
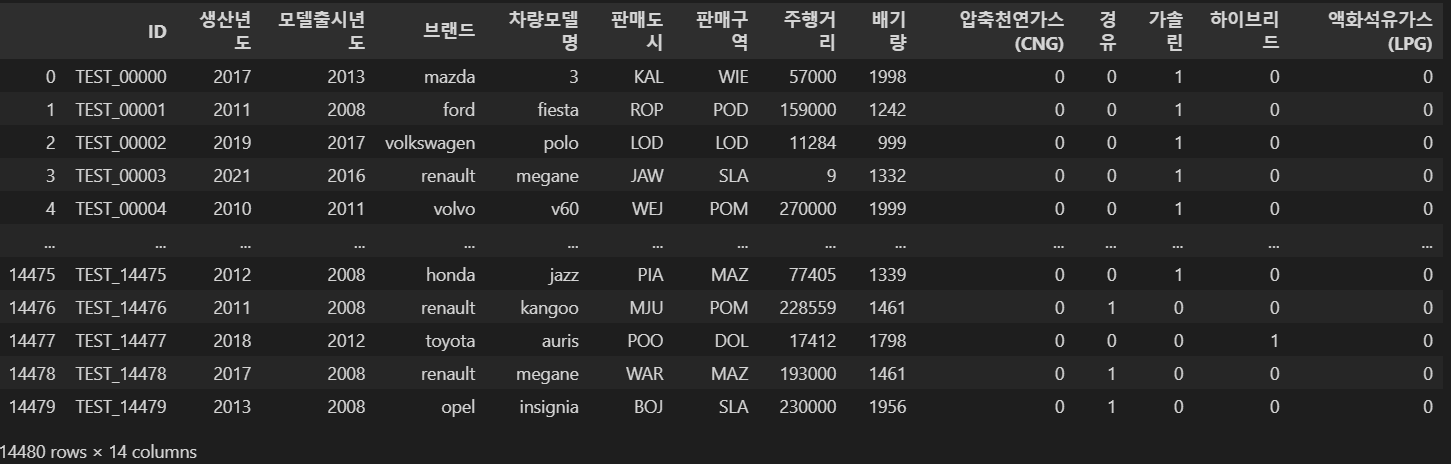
14480행이다!
info를 통해 train셋의 정보를 확인해보면...

결측치는 없는 것으로 보인다!
결측치를 확인해보면...
display(train.isnull().sum())
역시나 없다!
사실... 압축천연가스(CNG), 경유, 가솔린, 하이브리드, 액화석유가스(LPG)는 이미 원핫인코딩 된 값이므로!
EDA를 위한 데이터를 다시 만들어보자!
train_for_eda = train.copy()
test_for_eda = test.copy()
train_for_eda.loc[train_for_eda['압축천연가스(CNG)'] == 1, '연료'] = '압축천연가스(CNG)'
train_for_eda.loc[train_for_eda['경유'] == 1, '연료'] = '경유'
train_for_eda.loc[train_for_eda['가솔린'] == 1, '연료'] = '가솔린'
train_for_eda.loc[train_for_eda['하이브리드'] == 1, '연료'] = '하이브리드'
train_for_eda.loc[train_for_eda['액화석유가스(LPG)'] == 1, '연료'] = '액화석유가스(LPG)'
train_for_eda = train_for_eda.drop(columns=[
'압축천연가스(CNG)',
'경유',
'가솔린',
'하이브리드',
'액화석유가스(LPG)'
])
test_for_eda.loc[test_for_eda['압축천연가스(CNG)'] == 1, '연료'] = '압축천연가스(CNG)'
test_for_eda.loc[test_for_eda['경유'] == 1, '연료'] = '경유'
test_for_eda.loc[test_for_eda['가솔린'] == 1, '연료'] = '가솔린'
test_for_eda.loc[test_for_eda['하이브리드'] == 1, '연료'] = '하이브리드'
test_for_eda.loc[test_for_eda['액화석유가스(LPG)'] == 1, '연료'] = '액화석유가스(LPG)'
test_for_eda = test_for_eda.drop(columns=[
'압축천연가스(CNG)',
'경유',
'가솔린',
'하이브리드',
'액화석유가스(LPG)'
])5개의 컬럼을 연료 컬럼으로 합쳐줬다!
train과 test셋의 수치형 컬럼의 기술통계를 확인해 보면!
display(train_for_eda.describe())
test_for_eda.describe()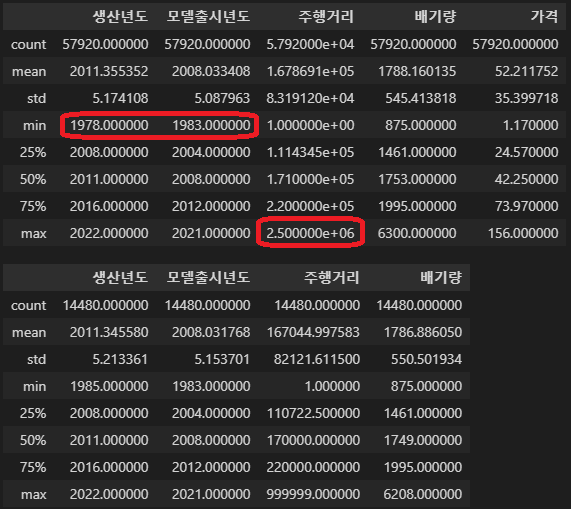
train셋에서 생산년도가 모델출시년도보다 앞선 데이터(오류)가 있는 것 같다!
그리고 250만 키로를 탄 max값 하나가 보인다!
전처리에서 처리해주기로 하자!
범주형 컬럼의 기술통계를 보면...
display(train_for_eda.describe(include='O'))
test_for_eda.describe(include='O')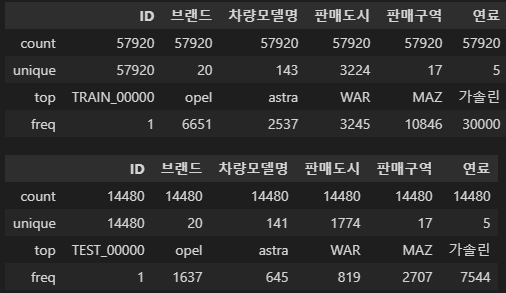
이미 인코딩이 되어있었던 연료빼고는 범주가 너무 많아...
원핫인코딩(컬럼 개수 폭발) 보다는 레이블인코딩을 하려 한다!
이번에는 용현이가 알려준... 코드로...
train과 test셋의 분포를 살펴보자!
plt.rcParams['font.family'] = 'NanumMyeongjo'
plt.rcParams['axes.unicode_minus'] = False
fig,ax = plt.subplots(ncols=3, nrows=2, figsize=(15, 10))
ax = ax.flatten()
palette = ['dodgerblue', 'salmon']
labels = ['Train', 'Test']
fig.subplots_adjust(hspace=0.3)
for _, graph in enumerate([train_for_eda[['생산년도', '모델출시년도', '주행거리', '배기량', '가격']],
test_for_eda[['생산년도', '모델출시년도', '주행거리', '배기량']]]):
for i, col in enumerate(graph.columns):
sns.histplot(
data=graph,
x=col,
ax=ax[i],
alpha=0.5,
color=palette[_],
kde=False,
label=labels[_]
)
ax[i].legend(loc='upper right')
if i % 3 != 0 :
ax[i].set_ylabel('')
ax[i].set_xlabel('')
ax[i].set_title(col, weight='bold')
fig.suptitle('Histplot of Trian & Test set', fontsize=20, weight='bold');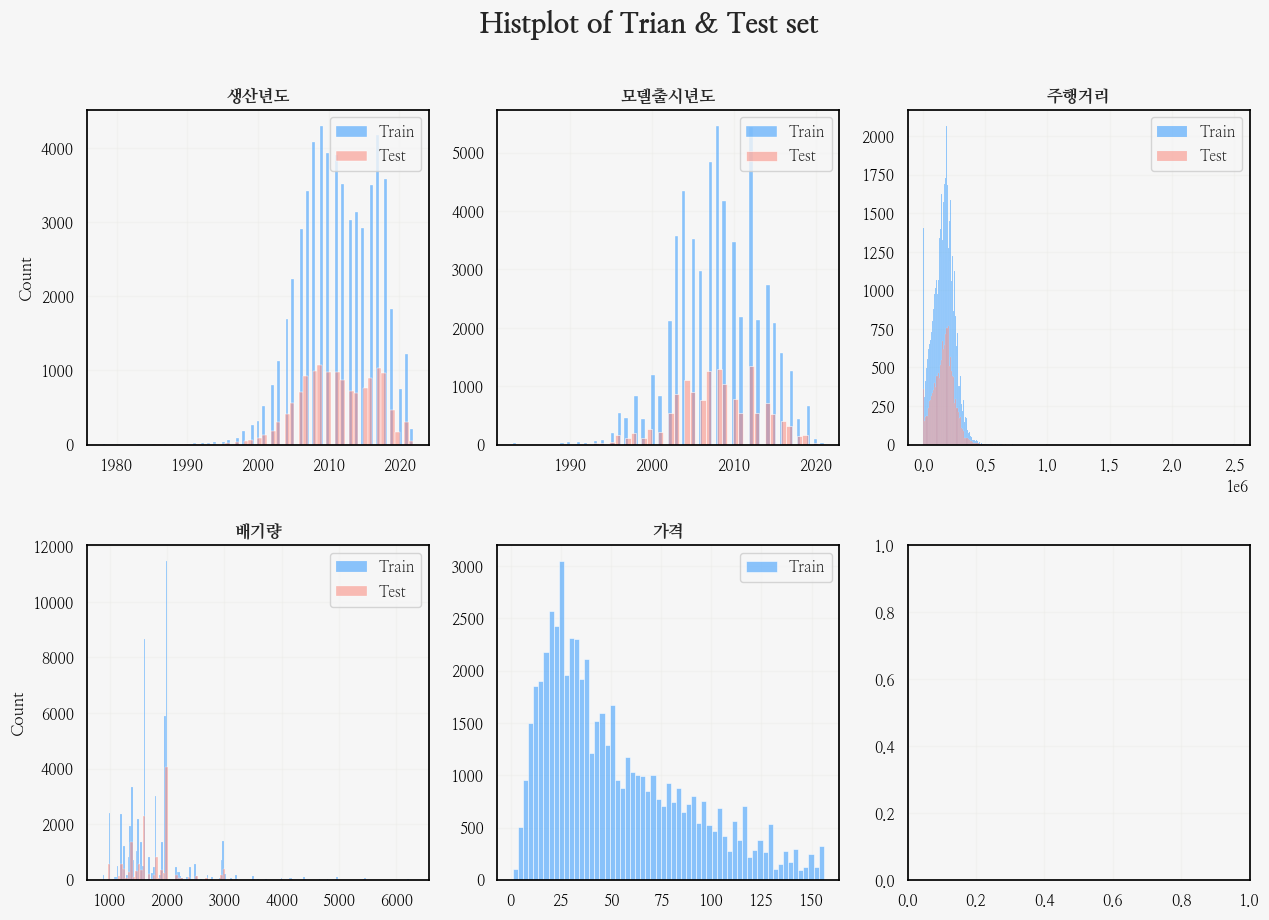
분포는 비슷한데...
주행거리 분포가 너무 왼쪽으로 쏠려있어 확인해보니...
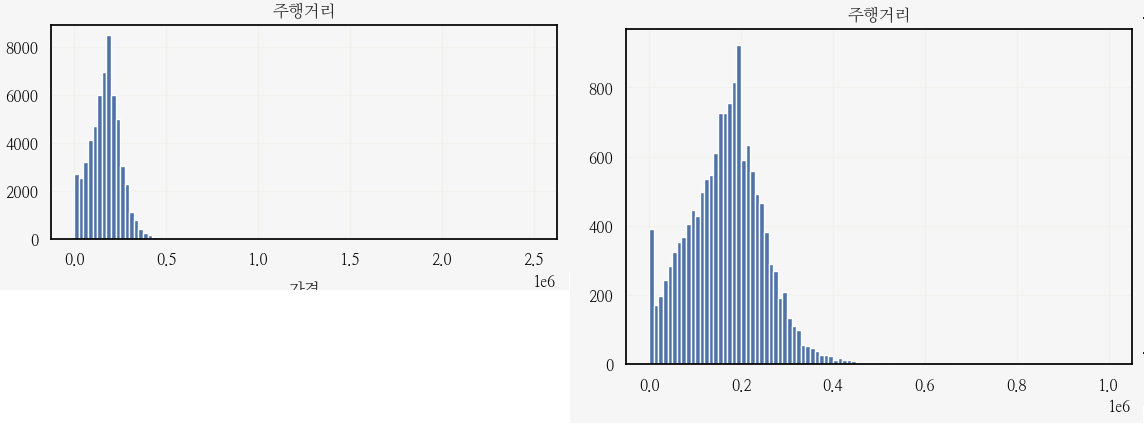
train셋의 주행거리 x축이 2.5배정도 큰 것을 발견...
대충 100만 킬로 정도 이상탄 것을 이상치라고 생각하고 전처리할 때 보자!
수치형 변수간 관계확인
산점도를 통한 수치형 변수간 관계 확인!
cmap = sns.diverging_palette(250, 10, as_cmap=True)
norm = mpl.colors.BoundaryNorm(boundaries=np.arange(-1, 1.2, 0.2), ncolors=cmap.N)
num_cols = train_for_eda.describe().columns
corr = train_for_eda[num_cols].corr()
mask = np.triu(np.ones_like(corr))
plt.figure(figsize=(10,10))
sns.heatmap(corr, mask=mask, cmap=cmap, norm=norm, annot=True, linewidths=5)
plt.title('Correalation Heatmap', fontsize=20, weight='bold');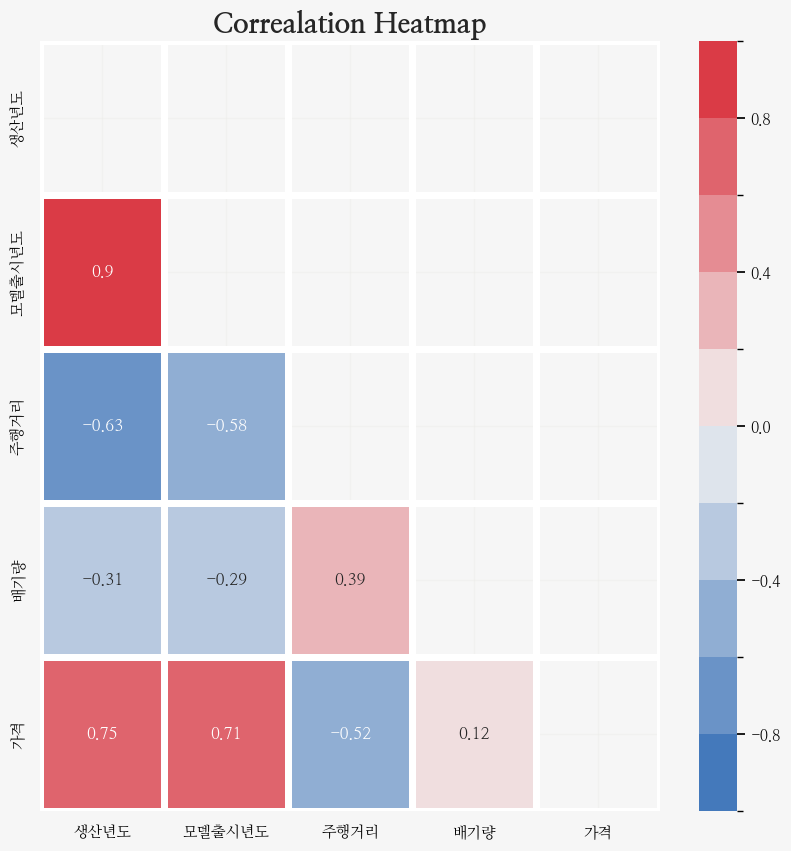
가격과 상관관계가
강한 것은 생산년도(양), 모델출시년도(양)
중간정도인 것은 주행거리(음)
약한 상관관계는(배기량)
정도 확인해 봤다!
이번엔 regplot을 통해 가격과 수치형 변수간 상관관계와 분포를 함께 봤다!
fig,ax = plt.subplots(ncols=2, nrows=2, figsize=(10, 10))
ax = ax.flatten()
fig.subplots_adjust(hspace=0.3)
for i, col in enumerate(num_cols[:-1]):
corr=round(train_for_eda[['가격', col]].corr().iloc[0, 1], 2)
sns.regplot(data=train_for_eda,
x=col,
y='가격',
scatter_kws={
'alpha': 0.3,
'color':'salmon'
},
line_kws={
'color':'blue',
'linestyle':':'
},
ax = ax[i])
ax[i].set_title(f'{col}(Corr : {corr})')
ax[i].set_xlabel('')
if i % 4 != 0:
ax[i].set_ylabel('')
fig.suptitle('Regplot of Numeric cols', fontsize=15, weight='bold');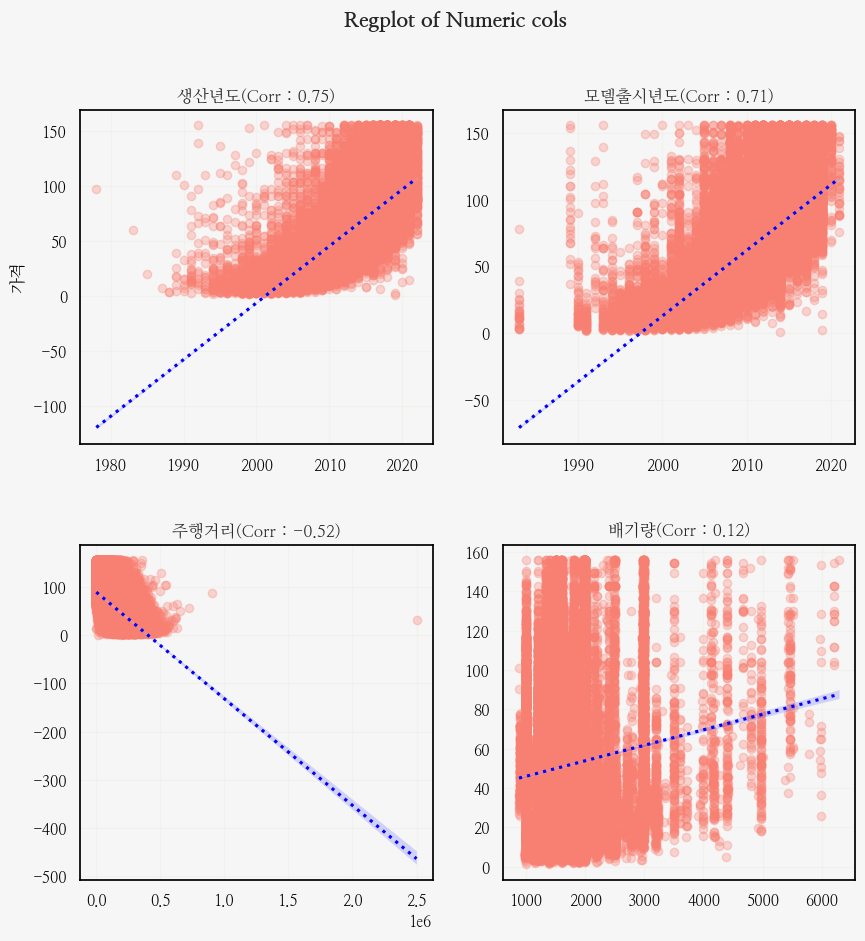
주행거리 regplot에서
아까 확인해보려 했던 250만 키로 탄 이상치 점이 한개가 보인다!
범주형 변수별 수치형 변수 분포 확인
먼저 브랜드별로 수치형 변수의 분포를 확인해보자!
fig,ax = plt.subplots(nrows=5, ncols=1, figsize=(20, 15))
ax = ax.flatten()
fig.subplots_adjust(hspace=0.3)
for i, col in enumerate(num_cols):
sns.boxplot(data=train_for_eda,
x='브랜드',
y=col,
palette='YlOrRd',
ax=ax[i])
if i != 4:
ax[i].set_xlabel('')
fig.suptitle('Boxplot of 브랜드 & num_cols', fontsize=20, weight='bold');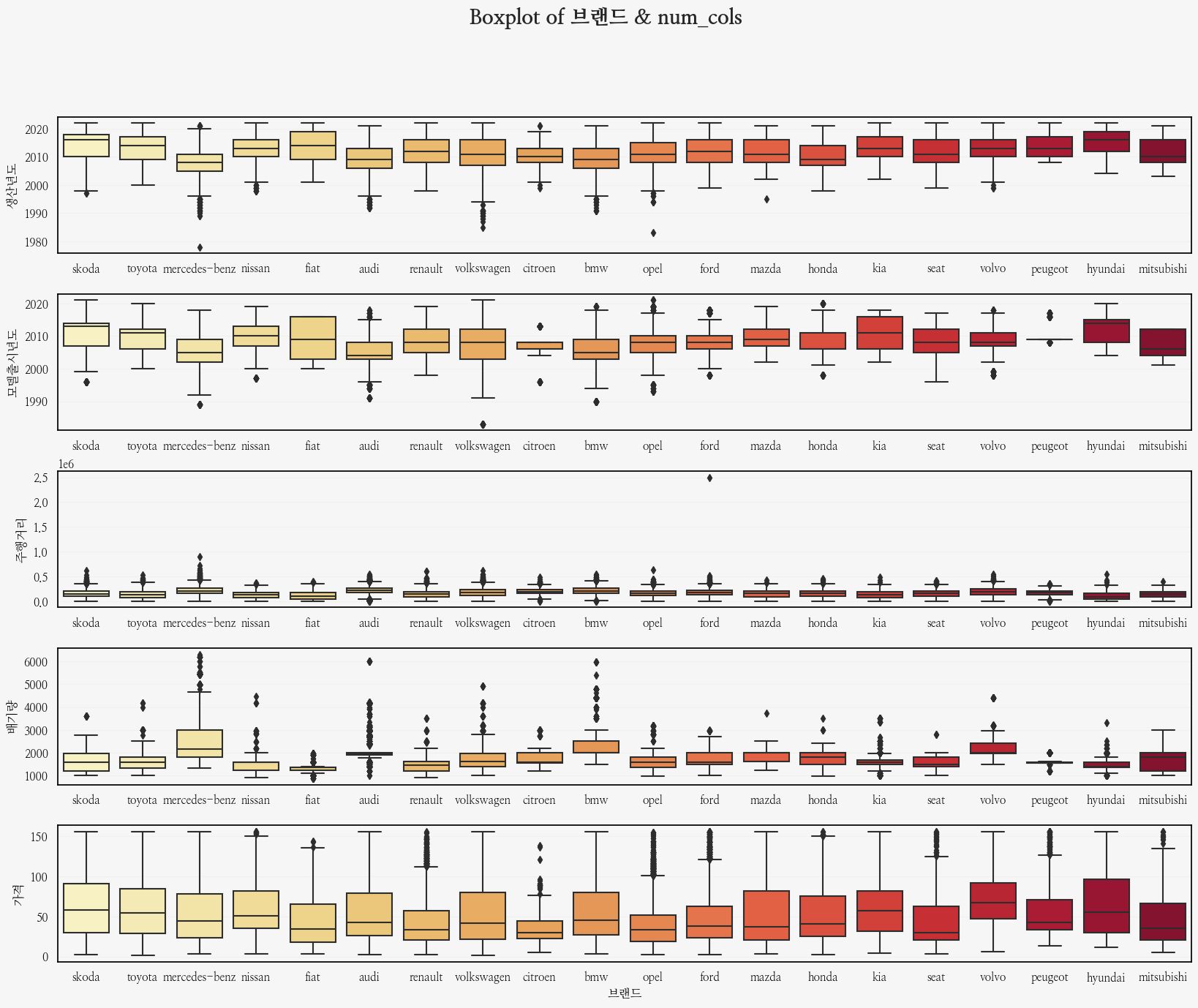
한 번에 눈에 안들어오지만...
simple EDA니깐...
이번엔 차량모델명별...
fig,ax = plt.subplots(nrows=5, ncols=1, figsize=(120, 20))
ax = ax.flatten()
fig.subplots_adjust(hspace=0.3)
for i, col in enumerate(num_cols):
sns.boxplot(data=train_for_eda,
x='차량모델명',
y=col,
palette='YlOrRd',
ax=ax[i])
if i != 4:
ax[i].set_xlabel('')
fig.suptitle('Boxplot of 차량모델명 & num_cols', fontsize=20, weight='bold');
어지럽다...?
판매도시는 범주가 너무 많아서 그리지 말자!
이번엔 판매구역별!
fig,ax = plt.subplots(nrows=5, ncols=1, figsize=(20, 15))
ax = ax.flatten()
fig.subplots_adjust(hspace=0.3)
for i, col in enumerate(num_cols):
sns.boxplot(data=train_for_eda,
x='판매구역',
y=col,
palette='YlOrRd',
ax=ax[i])
if i != 4:
ax[i].set_xlabel('')
fig.suptitle('Boxplot of 판매구역 & num_cols', fontsize=20, weight='bold');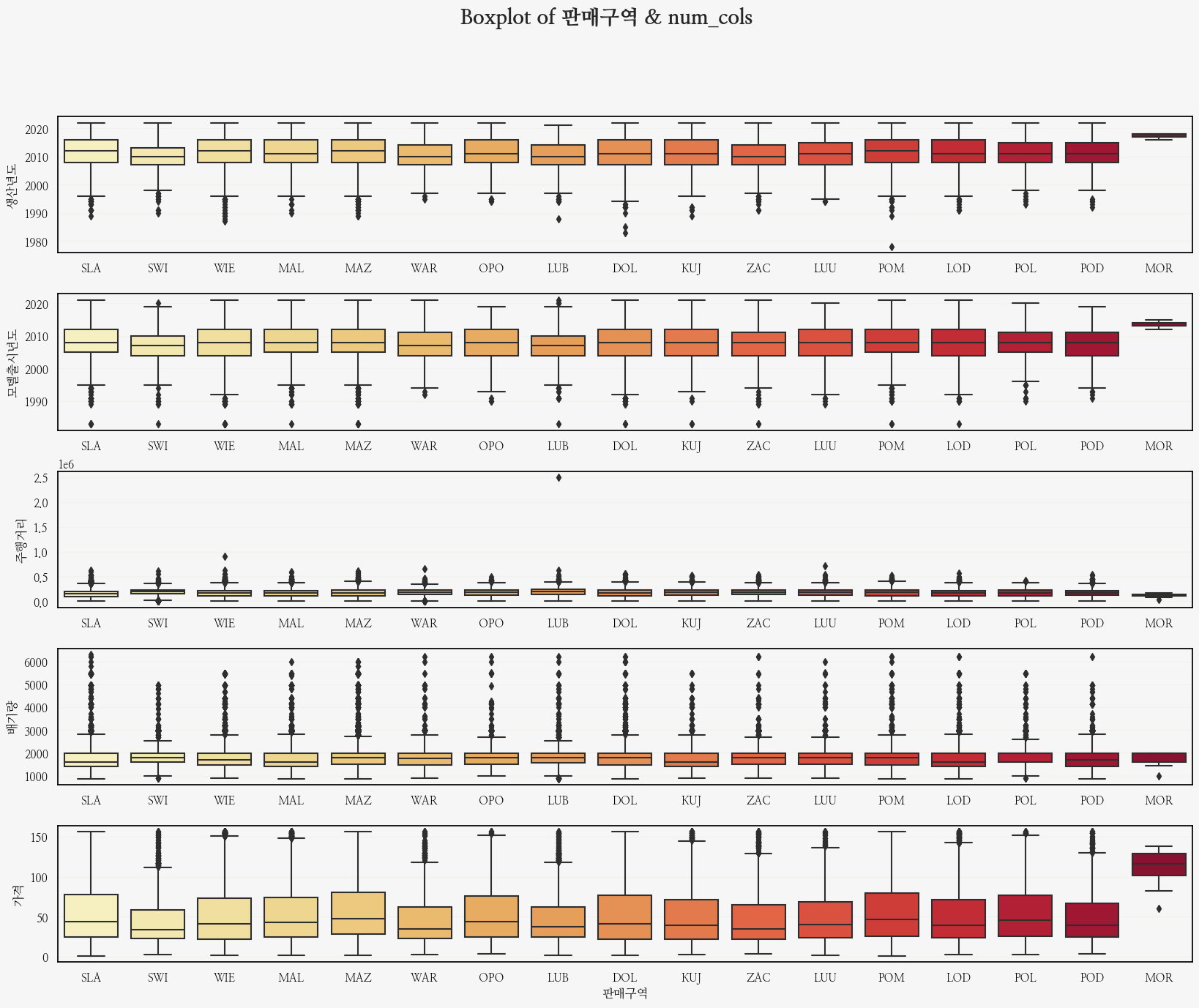
마지막으로 연료별!
fig,ax = plt.subplots(nrows=5, ncols=1, figsize=(15, 10))
ax = ax.flatten()
fig.subplots_adjust(hspace=0.3)
for i, col in enumerate(num_cols):
sns.boxplot(data=train_for_eda,
x='연료',
y=col,
palette='YlOrRd',
ax=ax[i])
if i != 2:
ax[i].set_xlabel('')
fig.suptitle('Boxplot of 연료 & num_cols', fontsize=20, weight='bold');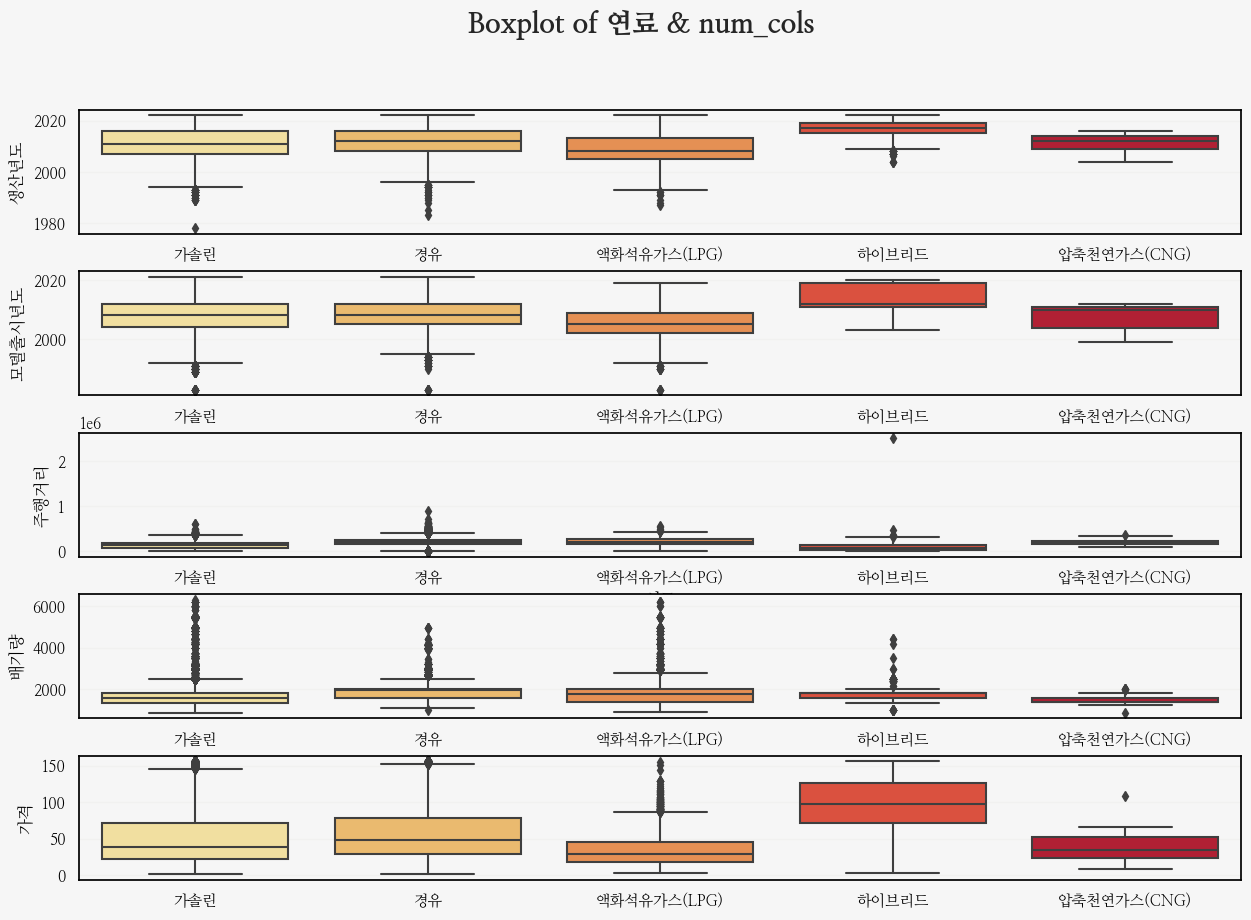
확실히 하이브리드 가격이 비싼 것, 출시년도와 생산년도가 최근인 것은 살펴볼 수 있었다!
이렇게 범주형 변수별 수치형 변수 분포를 확인해봤는데...
그냥 전체적인 분포를 살펴만 봤다...
피쳐엔지니어링...이 기다리고 있는데...
솔직히 무섭다...
'머신러닝' 카테고리의 다른 글
| 데이콘 Basic 자동차 가격 예측(모델링) (0) | 2023.06.28 |
|---|---|
| 데이콘 Basic 자동차 가격 예측(데이터 전처리) (0) | 2023.06.28 |


댓글