일단 늦었지만 우리나라의 월드컵 16강 축하합니다!!!
그럼... 16강 기념으로 epl의 득점 순위 데이터를 뽑아보고자 합니다...
그럼 시작~
저는 네이버 해외축구 기록/순위 창 중 프리미어리그 개인 순위 창(https://sports.news.naver.com/wfootball/record/index?category=epl&league=100&tab=player)에서 데이터를 크롤링 하기로 했습니더 ㅎㅎ

저는 초보니까 간단하게 선수 이름이랑 골 순위, 소속팀, 골 정도만 뽑아보려고 합니다!
음... 일단 기본적인 코드로 텍스트 데이터를 다 뽑아봅시다.
from bs4 import BeautifulSoup
import requests
url = "https://sports.news.naver.com/wfootball/record/index?category=epl&league=100&tab=player"
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
print(soup)그러면 어지럽게...

이런 데이터들이 스크롤바 죽도록 내릴만큼 나오는데여....
스크롤을 내리면서... 잘 관찰관찰...
선수들의 데이터를 찾았습니다!!!
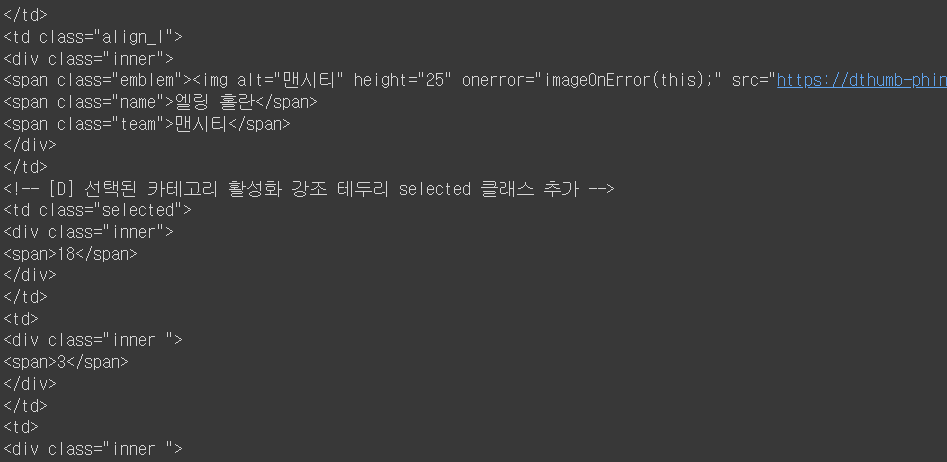

흠... 공통점을 찾으셨나여...? 힌트는 가장 먼저 보이는 글자입니다!
바로 td태그! 찾아보니 td태그는 표를 만드는 태그라고 하더라구요!!
그럼 findAll() 메서드를 통해 표 내용을 뽑아봅시다!
from bs4 import BeautifulSoup
import requests
url = "https://sports.news.naver.com/wfootball/record/index?category=epl&league=100&tab=player"
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
results = soup.findAll('td') #td태그 데이터만 찾아서
for result in results :
print(result.get_text()) #results는 리스트 형식이기 때문에 for 반복문으로 텍스트만 추출!!!!
이런 식으로 쭈욱 선수들의 순위 소속팀 스탯들이 나옵니다.
저는 간단하게 순위, 이름, 소속팀, 골 정도만 뽑으려고 하니까 어떻게 해야할지 고민하다가...
일단 split 함수로 각 스탯들을 리스트를 만들어 준 뒤...(인덱스로 뽑기 쉽게 하려고...ㅋㅋ)
빈 데이터 리스트를 만들어 삽입하기로 결정했습니다...
from bs4 import BeautifulSoup
import requests
url = "https://sports.news.naver.com/wfootball/record/index?category=epl&league=100&tab=player"
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
results = soup.findAll('td')
data = []
for result in results :
data.append(result.get_text().split('\n')) #엔터키를 구분자로 사용함
print(data)그럼 이런식으로 리스트 안에 리스트가 있는 그리 복잡하지 않은?? 리스트가 생성됩니다..

이제 남은 것은 원하는 데이터만 뽑아내기!!! for 반복문을 이용해 뽑아봅시다...
선수 한명 당 리스트 개수가 14개 인 것을 이용합니다!
그리고 오늘 날짜까지 출력해 줍니다!
그리하여 완성된 코드는...?
from bs4 import BeautifulSoup
import requests
from datetime import datetime #오늘 날짜를 이용하기 위해 datetime모듈 import
url = "https://sports.news.naver.com/wfootball/record/index?category=epl&league=100&tab=player"
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
results = soup.findAll('td')
data = []
for result in results :
data.append(result.get_text().split('\n'))
print(datetime.today().strftime("%Y년 %m월 %d일의 epl득점 순위입니다.\n"))
for i in range(len(data)) :
if (i % 14 == 0) :
print(data[i][2]+'위 : ', end = '')
#순위는 14개의 리스트 중 첫번째 데이터의 3번 칸에 위치
elif (i % 14 == 1) :
print(data[i][4]+'의', data[i][3], end = '')
#선수 이름과 팀 이름은 14개의 리스트 중 두번째 데이터의 각각 4번 5번 칸에 위치
elif (i % 14 == 2) :
print(' '+ data[i][2]+'골')
#골 수는 14개의 리스트 중 세번째 데이터의 3번 칸에 위치결과는...? 두둥!!!

총 20명의 순위가 나오네여 ㅎㅎ
손흥민 선수가 없는 것이 아쉽다면 아쉽군요...
손흥민 선수가 얼른 순위권 안에 안착하길 빌면서... 코딩을 마치네여
오늘은 재미로 크리스마스날의 epl 득점 순위를 알아보았는데여...
표로 된 데이터는 처음 크롤링 해봐서 예쁘게 출력하는데 많은 시간이 들었습니다...
하지만 가장 중요한 것은.......
카페에서 크리스마스에 이 것을 했다는 것...
현타가 오네여...

그럼 다음 게시물에서 봐요!!

'재미로 하는 코딩' 카테고리의 다른 글
| 네이버 웹 스크래핑 해보기 (0) | 2023.01.10 |
|---|---|
| 로또가 당첨되려면 몇 번 뽑아야할까? (0) | 2023.01.09 |
| 정규표현식을 사용한 여러가지 유효성 검사 (3) | 2022.12.29 |
| open API를 통해 코로나 감염현황을 알아보자 (0) | 2022.12.27 |
| random모듈을 사용해 롤 라인 정하기 (0) | 2022.12.26 |




댓글