Data structures accepted by seaborn(seaborn에서 받는 데이터 구조)
데이터 시각화 라이브러리로써 사용자는 seaborn에게 데이터를 제공할 필요가 있다. 이 챕터는 그렇게 하기 위한 다양한 방법을 설명한다. seaborn은 몇 가지 다른 데이터셋 형태를 지지하는데.. 대부분의 함수는 판다스나 넘피 라이브러리로부터의 객체뿐만 아니라 리스트와 딕셔너리같은 파이썬 내장 데이터 타입으로 표현되는 객체를 받는다. 다른 데이터셋과 관련된 사용패턴을 이해하는 것은 거의 모든 데이터셋에 대한 유용한 시각화를 빠르게 만들도록 도와준다!
NOTE!
v0.11.0버전에서 전체 옵션은 seaborn모듈의 하위 집합(관계형과 분포 모듈)에서만 지원된다. 다른 모듈은 대부분 동일한 유연성을 제공하지만 catplot과 lmplot은 명명된 긴 형태의 데이터에만 제한된다. 데이터 수집 코드는 다음 릴리스 주기에 걸쳐서 표준화 될 것이지만 그때까지는 데이터 세트에서 기대한 대로 작동하지 않는 각 함수의 특정 문서를 주의해애 한다!
Long-form vs wide-form data(긴 형태의 데이터 vs 넓은 형태의 데이터)
seaborn의 대부분 플롯 함수는 데이터 벡터를 지향한다. y에 대해 x를 그릴 때 각 변수는 벡터여야 한다. seaborn은 일부 표형식으로 구성된 둘 이상의 백터를 가진 데이터셋을 허용한다. 긴 형태의 데이터와 넓은 형태의 데이터는 근본적인 차이가 있고 seaborn은 각각을 다르게 처리한다!
Long-form data(긴 형태의 데이터)
긴 형태의 데이터는 각각의 변수가 열이고, 각 관찰값이 행인 특징을 가진다!
seaborn 내장 데이터셋인 flights는 1949년 부터 1960년 까지 각 달에 비행기를 탄 승객의 수을 기록했다.
일단 필요라이브러리 import
import seaborn as sns
%matplotlib inline
flights데이터 셋을 보자!
flights = sns.load_dataset("flights")
flights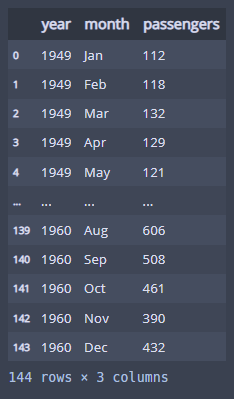
년, 월, 승객수의 3가지 변수가 있다!
이렇게 긴 형식의 데이터는 변수 중 하나에 명시적으로 주어진 역할을 부여함으로써 플롯에서 컬럼의 역할이 주어진다!
연도별 월별 승객수 relplot을 그려보면...
sns.relplot(data=flights, x="year", y="passengers", hue="month", kind="line");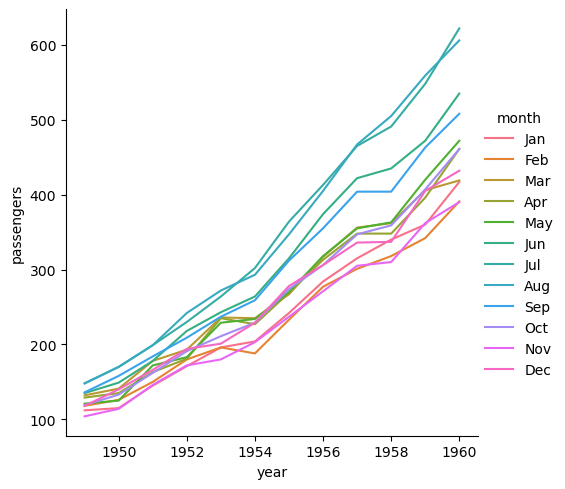
이렇게 그려진다...
x='year', y='passengers', hue='month'이렇게 명시적으로 컬럼의 역할이 주어진 것을 볼 수 있다!
이 그림에서 알 수 있듯 긴 형식 데이터의 장점은 플롯의 명시적인 명세에 적합하다는 것이다. 변수와 관찰이 명확하게 정의될 수 있는 한 임의의 복잡성을 가진 데이터셋을 수용할 수 있다. 그러나 이런 형식은 머리속에 있는 데이터 모델이 아닌 경우가 종종 있어서 익숙해지는데 시간이 걸린다!
Wide-form data(넓은 형태의 데이터)
간단한 데이터셋에서는 종종 스프레드시트(스프레드시트에서는 열과 행이 다양한 변수의 수준을 포함한다.)에서 보여지는 방식으로 데이터를 생각하는 것이 더 직관적이다.
위에서 본 flights데이터 세트를 피벗해 넓은 형태의 데이터로 변환하여 각 열에 연도별 월별 시계열이 포함되도록 해보자!
flights_wide = flights.pivot(index="year", columns="month", values="passengers")
flights_wide
이렇게 넓은 형태의 데이터에서도 3가지 변수가 있지만 다르게 구성되어 있다. 데이터셋의 변수는 명명된 필드가 아닌 테이블의 차원에 연결되어 있다. 각각의 관측치는 테이블의 셀에 있는 값과 행, 열 인덱스에 대한 해당 셀의 좌표 둘 다로 정의된다!
긴 형태의 데이터에서는 변수의 이름으로 데이터셋의 변수에 접근할 수 있다. 그러나 넓은 형태의 데이터에서는 아니다. 그럼에도 불구하고 테이블의 차원과 데이터셋의 변수간에는 명확한 관련이 있기때문에, seaborn은 플롯에서 긴 형태의 데이터, 넓은 형태의 데이터 모두 변수에 할당할 수 있다!
NOTE!
seaborn은 x와 y가 모두 할당 되지 않았을 때 데이터를 넓은 형식의 데이터로 취급한다!
아래의 예를 보자!
아까 만든 넓은 형태의 flights데이터를 relplot으로 그려보면...
sns.relplot(data=flights_wide, kind="line");
신기하게도 긴 형태의 데이터와 그린 것과 매우 유사하다. seaborn은 데이터프레임의 인덱스를 x에, 데이터 프레임의 값을 y에 할당했고 달마다 별도의 선을 그렸다. 그러나 두 그림에는 주목할만한 차이가 있다. 데이터셋이 긴 형태에서 넓은 형태로 바꾸는 피봇을 거칠 때 값이 의미하는 정보가 사라졌다. 결과적으로 y축 이름이 없다. 넓은 데이터로 그린 그림에서는 replot이 열 변수를 색상 및 스타일 시멘틱 모두에 매핑해서 플롯을 더 보기 쉽도록 선이 대쉬선으로 되어있다.
긴 형태로 만든 플롯에서도 style='month'로 지정하면 대쉬선으로 그릴 수 있다!
sns.relplot(data=flights, x="year", y="passengers", hue="month", style='month', kind="line");
이렇게!
지금까지 살펴본 바로는... 거의 같은 그림을 만드는데 넓은 형태의 데이터를 쓰는 것이 타이핑이 적었다. 그러나 긴 형태 데이터의 큰 장점은 올바른 형식의 데이터를 가지고 있으면 그 구조에 대해 더 이상 생각 안해도 된다는 것이다. 오직 데이터 안에 포함된 변수들에 대해서만 생각하면서 플롯을 디자인할 수 있다.
이번에는 각 년도의 월별 타임시리즈를 표현하는 선을 그릴건데... 단순히 변수를 재할당하면 된다!
이렇게 변수를 재할당 해주면...
sns.relplot(data=flights, x="month", y="passengers", hue="year", kind="line");
연도별 월별타임시리즈를 표현하는 선이 그려진다!
넓은 형태의 데이터로 비슷한 그림을 그리려면 데이터프레임을 전치행렬로 해줘야한다!
즉, 테이블의 구조에 대해서 다시 생각해야한다!
sns.relplot(data=flights_wide.T, kind="line");
이 예시는 또 하나의 결점을 보여주는데... seaborn이 현재 긴 형태의 데이터셋에서 열 변수를 데이터타입에 상관없이 범주형으로 취급한다는 것이다. 그래서 year가 범주형으로 취급되었다. 반면 긴 형태의 데이터에서 year는 숫자형이기 떄문에 양적인 컬러 팔레트와 범례가 배정되었다!(긴 형태의 데이터로 만든 플롯 참조)
명시적 변수 할당이 없는 것은 또한 각각의 플롯 타입이 넓은 형태 데이터의 차원과 플롯에서의 역할 사이에 고정된 매핑을 정의해야 하는 것을 의미한다. 이 자연스러운 매핑은 플롯 타입에 따라 달라질 수 있기 때문에 넓은 형태의 데이터를 사용할 때 결과가 덜 예측가능하다.
예를들면 catplot은 테이블의 열차원을 x에 할당하고, 인덱스를 무시하고 행을 따라 집계한다.
넓은 형태의 데이터를 catplot으로 그려보자!
sns.catplot(data=flights_wide, kind="box");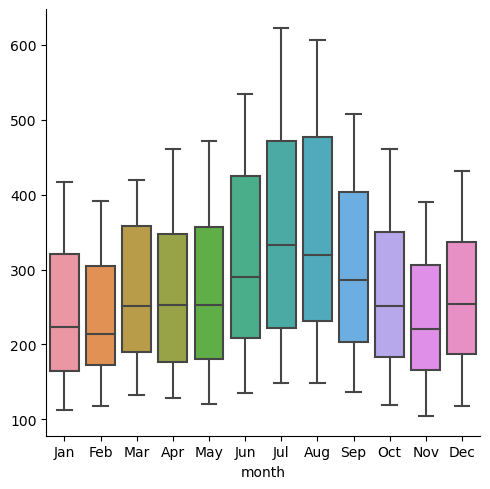
연도(인덱스)를 무시하고 월별로 분포를 표시하 것을 볼 수 있다!
넓은 형태의 데이터를 pandas를 이용해서 표시할 때, 3개 이하의 변수로 제한이 된다. 이것은 seaborn이 멀티 인덱스 정보를 사용하지 않기 때문인데... 멀티 인덱스는 판다스가 표 형식으로 추가적인 변수를 표현할 때 쓰는 방법이다. xarray 프로젝트는 레이블이 지정된 N차원 배열 객체를 제공하는데... xarray는 넓은 형태의 데이터를 더 높은 차원으로 일반화 한 것으로 간주된다. 현재 seaborn은 직접적으로 xarray로 된 객체를 지원하지는 않지만 xarray로 된 객체는 to_pandas 메서드를 사용해 긴 형태의 판다스 데이터프레임 으로 변환된 다음 seaborn으로 그려질 수 있다.
xarray 참고사이트
Xarray: N-D labeled arrays and datasets in Python
xarray.dev
요약해서 그림을 그려보면...

출처 : https://seaborn.pydata.org/tutorial/data_structure.html#wide-form-data
이렇다...
Messy data(지저분한 데이터)
많은 데이터셋은 긴 형태의 데이터와 넓은 형태의 데이터 규칙을 사용해서는 명확하게 해석할 수 없다. 데이터셋이 명확하게 긴 형태거나 넓은 형태인 경우가 말끔하다고 한다면 좀 더 모호한 데이터셋은 지저분하다고 말할 수 있다. 지저분한 데이터셋에서는 변수가 키나 테이블 차원에 의해 유일하게 정의되지 않는다. 이는 각 행이 데이터 수집 단위에 일치하도록 테이블을 구성하는 것이 자연스러운 측정 데이터에서 종종 발생한다.
그럼 20명의 피험자가 주의가 분산되거나 집중하는 동안 애너그램(단어나 문구의 글자를 재벼열해 새로운 단어나 문구를 형성하는 방식)을 연구하는 기억 과제를 수행한 심리학실험의 데이터셋을 보자!
anagrams = sns.load_dataset("anagrams")
anagrams
attr 변수는 피험자간의 변수지만 피험자 안에서 변수도 있는데... 1에서 3까지 가능한 애너그램 해답의 수(num1, num2, num3)이다. 암기 능력 점수는 종속변수이다. 이 두 개의 변수(수와 점수)는 여러 열에서 공동으로 인코딩된다. 결과적으로 데이터셋 전체는 분명히 긴 형태의 데이터도 아니고 넓은 형태의 데이터도 아니다.
그럼 어떻게 seaborn에게 해답의 수 변수와 주의 변수의 함수로 평균점수를 그리도로 할 수 있을까? 먼저 데이터를 긴 형태나 넓은 형태로 강제로 변환해줘야 한다. 말끔한 긴 형태의 데이터 테이블로 변환시켜 각 변수가 열이되고 각 행이 관측치가 되게끔 해보자!
melt함수를 사용해 anagrams 데이터를 녹여보면...
anagrams_long = anagrams.melt(id_vars=["subidr", "attnr"], var_name="solutions", value_name="score")
anagrams_long


이렇게 긴 형태의 데이터가 만들어졌다!
이것을 가지고 catplot을 만들건데...
x는 solutions, y는 score, hue는 attr, kind='point'로 해서 그려보자!
sns.catplot(data=anagrams_long, x="solutions", y="score", hue="attnr", kind="point");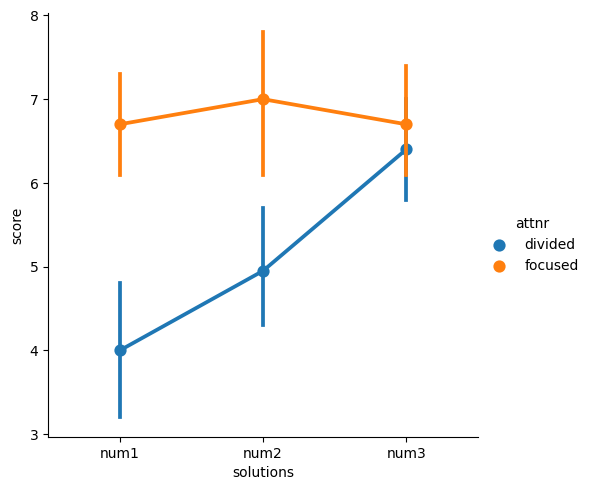
이런 식으로 그릴 수 있다!
Further reading and take-home points(추가 읽을 거리와 기억할 포인트)
표 형식 데이터 구조에 대한 더 자세한 내용은 Hadley Whickham의 Tidy Data문서를 참조하는데... seaborn에서 사용하는 개념은 Tidy Data문서에 정의된 것과는 약간 다른 것을 주의하자! 문서에서는 깔끔을 긴 형태의 구조와 연관시키지만, 여기서는 데이터셋의 변수와 테이블의 차원간 분명한 매핑이 있는 것을 깔끔한 넓은 형태의 데이터로, 이런 매핑이 없는 것을 지저분한 데이터로 구별했다!
긴 형태의 구조는 확실한 장점이있다. 그림에서 데이터셋의 변수에게 역할을 분명하게 할당함으로써 그림을 만들 수 있고, 3개 이상의 변수로도 가능하다는 것이다. 가능하다면, 심각한 분석을 시작할 때는 긴 형태의 구조로 데이터를 나타내도록 하자! seaborn문서의 대부분의 예제들은 긴 형태의 데이터를 사용할 것이다. 그러나 데이터셋을 넓은 구조로 놔두는 것이 더 자연스러운 경우에는 seaborn이 유용할 수 있다는 것을 명심하자!
Options for visualizing long-form data(긴 형태의 데이터 시각화 옵션)
긴 형태의 데이터는 정확한 정의가 있는 반면, seaborn은 메모리상의 데이터 구조 전체에 걸쳐 실제 구성되는 방법 측면에서 상당이 유연하다. 문서의 남은 예제들은 플롯의 변수에 열의 이름을 지정함으로써 일반적으로 판다스 데이터프레임 객체와 데이터프레임 안의 참조 변수들을 사용한다. 그러나 파이썬 딕셔너리나 인터페이스를 구현하는 클레스 안에서 벡터를 저장하는 것도 가능하다.
일단 flights데이터를 dict형식으로 변경하면...
flights_dict = flights.to_dict()
flights_dict
이렇게 dictionary형식으로 변했다!
이 데이터로 연도별 월별 승객 시각화를 해보면...
앞에서 한 것과 똑같이 하면 된다!
sns.relplot(data=flights_dict, x="year", y="passengers", hue="month", kind="line");
분할하고, 적용하고, 결합하는 groupby 연산과 같이 많은 pandas의 연산은 정보가 입력한 데이터프레임의 열에서 결과 데이터프레임의 인덱스로 이동한 데이터프레임을 생성한다. 이름이 유지되는 한 정상적으로 데이터를 참조할 수 있다!
아래의 예를 보면...
groupby를 사용하여 연도별 승객의 평균을 구한 데이터프레임을 만들었다!
flights_avg = flights.groupby("year").mean()
flights_avg
원래 year은 flights 데이터프레임에서 열(column)에 있었는데... 인덱스로 이동했다!
이 데이터프레임으로 x는 year, y는 passengers로 relplot을 그려보면...
sns.relplot(data=flights_avg, x="year", y="passengers", kind="line");
이렇다!
추가적으로 데이터의 벡터를 x, y, 다른 변수에 직접 아규먼트로서 전달하는 것이 가능하다. 이런 백터들이 pandas객체 라면, 이름 속성은 플롯에 레이블을 지정한다.
즉 이렇게...
year변수에 flights_avg데이터프레임의 인덱스를 할당하고...
passengers변수에 flights_avg의 passengers컬럼을 할당해서 플롯에 직접 변수를 넣어줄 수 있다!
또 year변수와 passengers변수는 x축 이름과 y축 이름으로 각각 지정된다!
year = flights_avg.index
passengers = flights_avg["passengers"]
sns.relplot(x=year, y=passengers, kind="line");
파이썬 시퀀스 인터페이스를 구현하는 Numpy배열과 다른 객체도 쓸 수 있지만, 이름이 없으면 추가 조정 없이는 플롯이 그리 유용하지 않다!
이렇게 x에 year시퀀스를 지정하고 y에 passengers를 리스트로 만들어 넣어서 그림을 그리면...
year = flights_avg.index
passengers = flights_avg["passengers"]
sns.relplot(x=year.to_numpy(), y=passengers.to_list(), kind="line")
이렇게 x축 이름과 y축 이름이 없어서 유용한 그림은 아니다!
Options for visualizing wide-form data(넓은 형태의 데이터 시각화 옵션)
넓은 형태의 데이터에 대한 옵션은 더 유동적이다. 긴 형태의 데이터와 마찬가지로 이름 정보나 인덱스 정보가 사용될 수 있기 때문에 pandas 객체가 선호된다. 그러나 본질적으로 단일 벡터나 여러 벡터의 단일 집합으로 여기질 수 있는 한 어느 형태든 데이터에 전달되어 보통 유효한그림이 만들어진다.
위에서 본 예제는 열의 집합으로서 여겨질 수 있는 직사각형의 pandas 데이터프레임을 사용했다. 판다스의 딕셔너리와 리스트 객체도 사용할 수 있는데 축 이름을 잃는다.
일단... flights_wide_list를 만들어주는데...
아까 만들었던 넓은 형태의 데이터인 flights_wide를 이용해서 만들어준다.
flights_wide_list = [col for _, col in flights_wide.items()]
flights_wide_list
이런 식으로 월별로 리스트에 담겨있다!
이 데이터로 relplot을 그려보자!
sns.relplot(data=flights_wide_list, kind="line");
이렇게 그려진다.
이 flights_wide에 있는 벡터는 같은 길이를 가질 필요가 없다. 인덱스가 있으면, 인덱스가 벡터를 정렬하는데 사용된다.
flights_wide에서 인덱스는 year이다! 서로 다른 년도 범위 년도를 가진 1월과 8월 승객수를 그려보자!
첫 원소는 1월, 1954년까지의 데이터...
두번째 원소는 8월, 1952년부터시작하는 데이터...
를 가진 two_series라는 리스트를 만들어준다!
two_series = [flights_wide.loc[:1955, "Jan"], flights_wide.loc[1952:, "Aug"]]
two_series
이런 데이터(인덱스가 있지만 길이는 다른 벡터를 가진)로 그림을 그려보면...
sns.relplot(data=two_series, kind="line");
이런 식으로 데이터가 있는 부분만 그려진다!
반면 numpy배열이나 단순한 파이썬 시퀀스의 경우 서수 인덱스가 사용된다.
이렇게 two_series의 원소를 numpy배열로 바꿔 two_arrays에 담아주면...
two_arrays = [s.to_numpy() for s in two_series]
two_arrays
이런 식인데 이것으로 그림을 그려보면...
sns.relplot(data=two_arrays, kind="line");
원하는 그림을 얻을 수 없을 뿐더러 x축이 그냥 서수형태로 된다.
범례도 0과 1로 표시된다.
이번엔 딕셔너리 형태로 만들어 그림을 그려볼건데...
two_arrays_dict = {s.name: s.to_numpy() for s in two_series}
two_arrays_dict
키에 이름이 들어가있다!

그래서 그나마 범례가 표시는 된다..
직사각형 numpy배열은 인덱스정보가 없는 데이터형태처럼 취급되므로 열 벡터의 집합으로 볼 수 있다.(세로방향 벡터) 이것은 단일 인덱서가 한 행에 접근하는 numpy인덱싱과는 다르다는 것을 주의하자!(가로방향 벡터) 그러나 판다스가 배열을 데이터프레임으로 바꾸는 방식 또는 matplotlib이 플롯 그리는 방식과는 일치한다.
flights_wide를 아래처럼 numpy배열로 바꿔보자!
flights_array = flights_wide.to_numpy()
flights_array
이렇게 년도별로 한 리스트에 담겨있다!
이 배열로 그림을 그려보면...
sns.relplot(data=flights_array, kind="line");
이렇게 flights_wide로 그린 것과 모양은 똑같이 그려지는데...
한 선이 그려질 때 각 array의 행벡터가 아니라 열벡터(세로방향)로 그림이 그려진 것을 확인할 수 있다!
참고 사이트
https://seaborn.pydata.org/tutorial/data_structure.html#
Data structures accepted by seaborn — seaborn 0.12.2 documentation
Data structures accepted by seaborn As a data visualization library, seaborn requires that you provide it with data. This chapter explains the various ways to accomplish that task. Seaborn supports several different dataset formats, and most functions acce
seaborn.pydata.org




댓글