
과제를 하다가 내용랭크까지만 수집하고...
내용은 수집 못했었는데요...
또 날짜를 빼놓고 수집했습니다...
import pandas as pd
import requests
from bs4 import BeautifulSoup as bs
def get_end_page(item_code):
url_for_end = 'https://finance.naver.com'
url_for_end = f'{url_for_end}/item/board.naver?code={item_code}'
response = requests.get(url_for_end,
headers = {'User-Agent':'Mozilla/5.0'})
html = bs(response.text)
step1 = html.select('tbody > tr > td > table > tbody > tr > td > a')
step2 = step1[-1]['href'].split('=')[-1]
end_page = int(step2)
return end_page
def get_pages(item_code, item_name):
pages = []
for page_no in range(1, get_end_page(item_code)+1):
url = f'https://finance.naver.com/item/board.naver?'
url = f'{url}code={item_code}&page={page_no}'
headers = {'User-Agent':'Mozilla/5.0'}
response = requests.get(url, headers = headers)
page = pd.read_html(response.text)[1]
page = page.drop('Unnamed: 6', axis=1)
page = page.dropna()
html = bs(response.text)
links = html.select('div > table.type2 > tbody > tr > td > a')
links_list = []
for link in range(len(links)):
links_list.append('https://finance.naver.com/'+links[link]['href'])
page['내용링크'] = links_list
pages.append(page)
pages = pd.concat(pages)
pages['종목코드'] = item_code
pages['종목이름'] = item_name
pages['조회'] = pages['조회'].astype(int)
pages['공감'] = pages['공감'].astype(int)
pages['비공감'] = pages['비공감'].astype(int)
cols = ['종목코드', '종목이름', '제목', '글쓴이','내용링크',
'조회', '공감', '비공감']
pages = pages[cols]
pages = pages.drop_duplicates()
file_name = f'{item_name}-{item_code}.csv'
pages.to_csv(file_name, index=False)
return pd.read_csv(file_name)

여기까지 했었습니다...
오늘의 목표는...
날짜도 수집해보고...
과제를 보충해서 내용까지 수집하고...
원하는 페이지까지 수집하는 함수를 만들고...
마지막으로 만들어진 여러 함수들을 묶어 클래스로 만들어보려고 합니다!
일단 날짜도 수집하게 코드를 고치면...
import pandas as pd
import requests
from bs4 import BeautifulSoup as bs
def get_end_page(item_code):
url_for_end = 'https://finance.naver.com'
url_for_end = f'{url_for_end}/item/board.naver?code={item_code}'
response = requests.get(url_for_end,
headers = {'User-Agent':'Mozilla/5.0'})
html = bs(response.text)
step1 = html.select('tbody > tr > td > table > tbody > tr > td > a')
step2 = step1[-1]['href'].split('=')[-1]
end_page = int(step2)
return end_page
def get_all_pages(item_code, item_name):
pages = []
for page_no in range(1, get_end_page(item_code)+1):
url = f'https://finance.naver.com/item/board.naver?'
url = f'{url}code={item_code}&page={page_no}'
headers = {'User-Agent':'Mozilla/5.0'}
response = requests.get(url, headers = headers)
page = pd.read_html(response.text)[1]
page = page.drop('Unnamed: 6', axis=1)
page = page.dropna()
html = bs(response.text)
links = html.select('div > table.type2 > tbody > tr > td > a')
links_list = []
for link in range(len(links)):
links_list.append('https://finance.naver.com/'+links[link]['href'])
page['내용링크'] = links_list
pages.append(page)
pages = pd.concat(pages)
pages['종목코드'] = item_code
pages['종목이름'] = item_name
pages['조회'] = pages['조회'].astype(int)
pages['공감'] = pages['공감'].astype(int)
pages['비공감'] = pages['비공감'].astype(int)
cols = ['종목코드', '종목이름', '날짜', '제목', '글쓴이','내용링크',
'조회', '공감', '비공감']
pages = pages[cols]
pages = pages.drop_duplicates()
file_name = f'{item_name}-{item_code}.csv'
pages.to_csv(file_name, index=False)
return pd.read_csv(file_name)컬럼에 날짜도 넣어주고..
모든 페이지를 수집하기때문에 함수이름도 get_page() -> get_all_page()로 바꿨습니다.
get_all_pages('206950', '볼빅')한번 실행해보면...
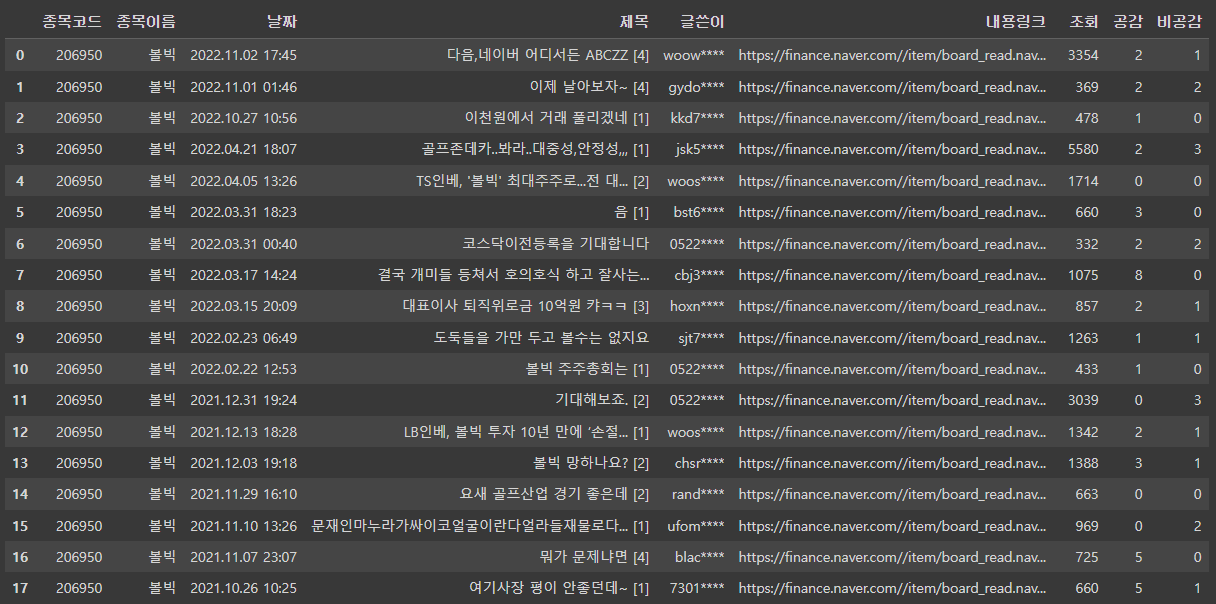
날짜도 잘 나옵니다!
그 다음 내용링크를 통해 링크를 불러오는 함수를 작성했습니다.
import pandas as pd
import requests
from bs4 import BeautifulSoup as bs
def get_content(url):
headers = {'User-Agent':'Mozilla/5.0'}
response = requests.post(url, headers=headers)
html = bs(response.text)
lines = []
for line in html.select('#body'):
lines.append(line.text)
lines = lines[0].replace('\r', ' ')
return lines
url = 'https://finance.naver.com/item/board_read.naver'
url = f'{url}?code=206950&nid=233960819&st=&sw=&page=1'
get_content(url)
이렇게 나오는데여...
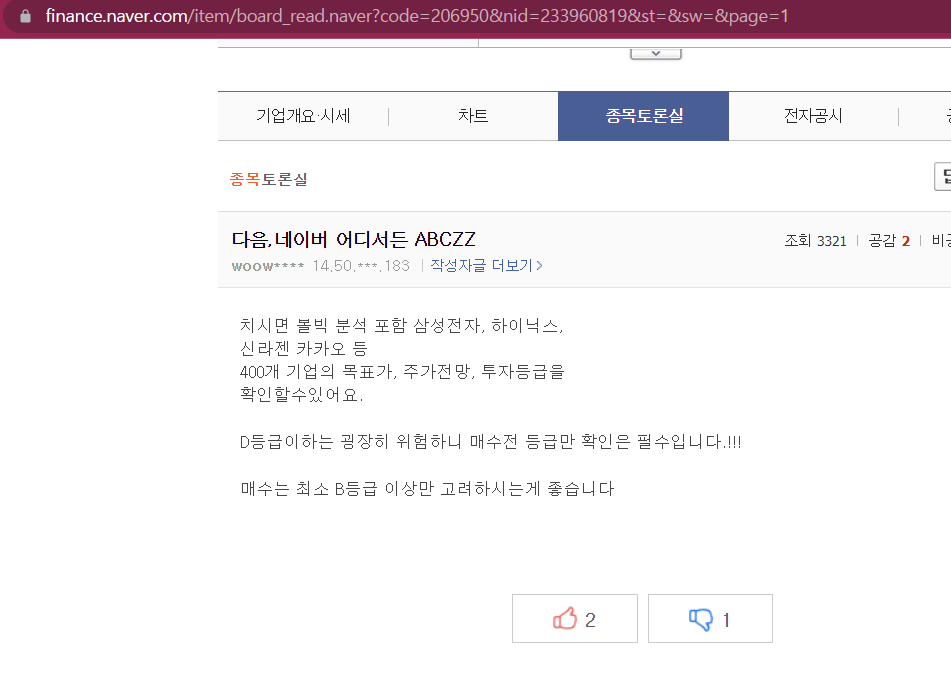
페이지를 직접 들어가 확인하면 내용이 잘 불러와진 것을 확인할 수 있쥬!!
이제 내용링크는 필요없으니... 내용링크를 삭제하구... 내용을 직접넣어주게 함수를 적용해 봅시다~~
이렇게 내용을 찾아주는 함수를 페이지를 얻는 함수에서 적용시키면...
import pandas as pd
import requests
from bs4 import BeautifulSoup as bs
def get_end_page(item_code):
url_for_end = 'https://finance.naver.com'
url_for_end = f'{url_for_end}/item/board.naver?code={item_code}'
response = requests.get(url_for_end,
headers = {'User-Agent':'Mozilla/5.0'})
html = bs(response.text)
step1 = html.select('tbody > tr > td > table > tbody > tr > td > a')
step2 = step1[-1]['href'].split('=')[-1]
end_page = int(step2)
return end_page
def get_content(url):
headers = {'User-Agent':'Mozilla/5.0'}
response = requests.post(url, headers=headers)
html = bs(response.text)
lines = []
for line in html.select('#body'):
lines.append(line.text)
lines = lines[0].replace('\r', ' ')
return lines
def get_all_pages(item_code, item_name):
pages = []
for page_no in range(1, get_end_page(item_code)+1):
url = f'https://finance.naver.com/item/board.naver?'
url = f'{url}code={item_code}&page={page_no}'
headers = {'User-Agent':'Mozilla/5.0'}
response = requests.get(url, headers = headers)
page = pd.read_html(response.text)[1]
page = page.drop('Unnamed: 6', axis=1)
page = page.dropna()
html = bs(response.text)
links = html.select('div > table.type2 > tbody > tr > td > a')
links_list = []
for link in range(len(links)):
links_list.append('https://finance.naver.com/'+links[link]['href'])
page['내용링크'] = links_list
pages.append(page)
pages = pd.concat(pages)
pages['내용'] = pages['내용링크'].map(get_content)
pages = pages.drop('내용링크', axis=1)
pages['종목코드'] = item_code
pages['종목이름'] = item_name
pages['조회'] = pages['조회'].astype(int)
pages['공감'] = pages['공감'].astype(int)
pages['비공감'] = pages['비공감'].astype(int)
cols = ['종목코드', '종목이름', '날짜', '제목', '글쓴이','내용',
'조회', '공감', '비공감']
pages = pages[cols]
pages = pages.drop_duplicates()
file_name = f'{item_name}-{item_code}.csv'
pages.to_csv(file_name, index=False)
return pd.read_csv(file_name)그리고 실행!
get_pages('206950', '볼빅')볼빅이 페이지가 3페이지 밖에 없어서...
이 종목을 수집했습니다!
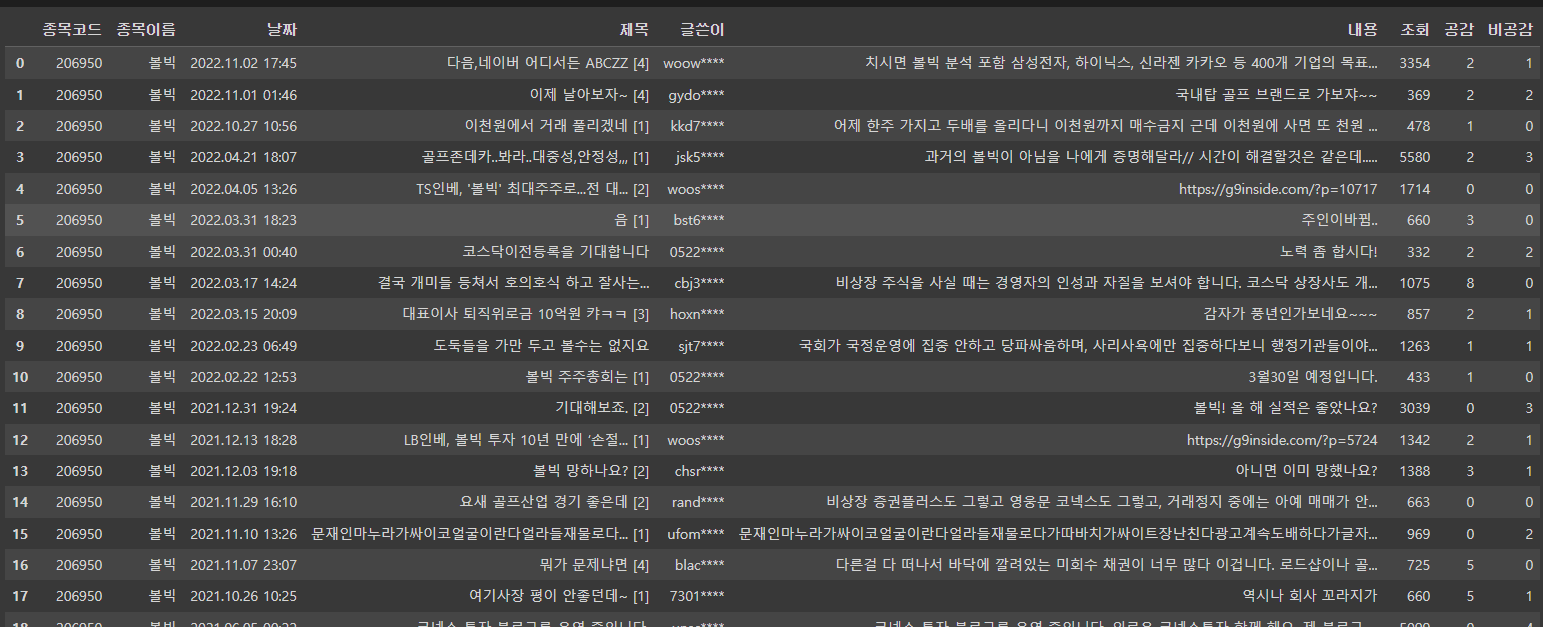
내용링크가 빠지구 내용이 잘 수집된 것 같네여!
그 다음으로 원하는 페이지까지 수집하는 함수를 만들어 봅시당!
짠!
def get_pages_want(item_code, item_name, page_want):
url_for_link = 'https://finance.naver.com/'
if page_want <= get_end_page(item_code):
pages = []
for page_no in range(1, page_want+1):
url = f'https://finance.naver.com/item/board.naver?'
url = f'{url}code={item_code}&page={page_no}'
headers = {'User-Agent':'Mozilla/5.0'}
response = requests.get(url, headers = headers)
page = pd.read_html(response.text)[1]
page = page.drop('Unnamed: 6', axis=1)
page = page.dropna()
html = bs(response.text)
links = html.select('div > table.type2 > tbody > tr > td > a')
links_list = []
for link in range(len(links)):
links_list.append(url_for_link+links[link]['href'])
page['내용링크'] = links_list
pages.append(page)
pages = pd.concat(pages)
pages['내용'] = pages['내용링크'].map(get_content)
pages = pages.drop('내용링크', axis=1)
pages['종목코드'] = item_code
pages['종목이름'] = item_name
pages['조회'] = pages['조회'].astype(int)
pages['공감'] = pages['공감'].astype(int)
pages['비공감'] = pages['비공감'].astype(int)
cols = ['종목코드', '종목이름', '날짜', '제목', '글쓴이','내용',
'조회', '공감', '비공감']
pages = pages[cols]
pages = pages.drop_duplicates()
file_name = f'{item_name}-{item_code}-{page_want}.csv'
pages.to_csv(file_name, index=False)
return pd.read_csv(file_name)
else:
print('페이지가 끝페이지를 초과했습니다.')이렇게 페이지가 끝페이지를 넘으면 초과했다고 나오게 함수를 만들었습니다.
한번 태양금속우의 종목토론실 5페이지까지 수집해볼까요?
get_pages_want('004105', '태양금속우', 5)이렇게 잘 수집이 되었네여...
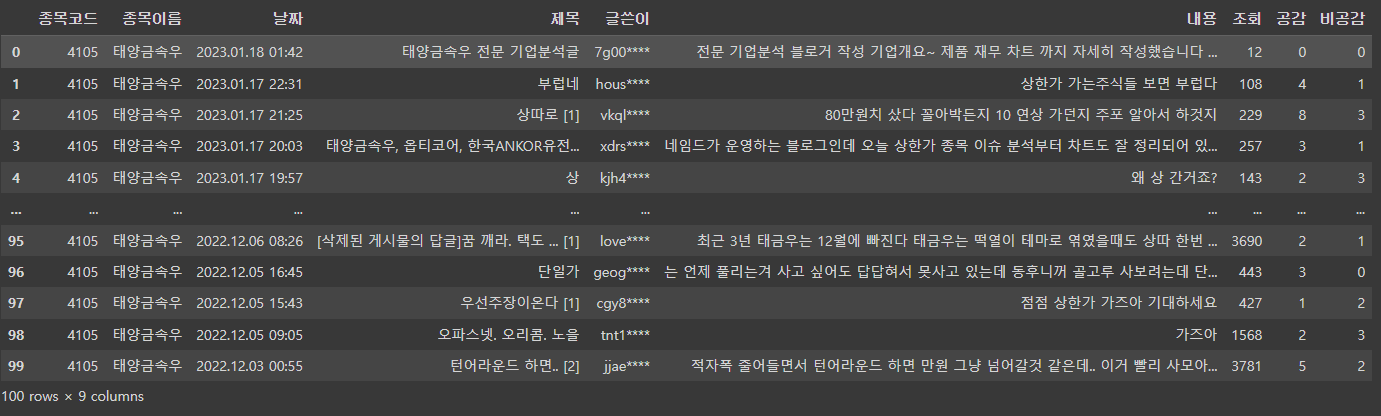
페이지가 306페이지까지 있는데여...
get_pages_want('004105', '태양금속우', 500)500을 넣으면...?
페이지가 초과했다고 나오네여

일단 지금까지 한 코드를 모두 종합해봅시다!
import pandas as pd
import requests
from bs4 import BeautifulSoup as bs
def get_end_page(item_code):
url_for_end = 'https://finance.naver.com'
url_for_end = f'{url_for_end}/item/board.naver?code={item_code}'
response = requests.get(url_for_end,
headers = {'User-Agent':'Mozilla/5.0'})
html = bs(response.text)
step1 = html.select('tbody > tr > td > table > tbody > tr > td > a')
step2 = step1[-1]['href'].split('=')[-1]
end_page = int(step2)
return end_page
def get_content(url):
headers = {'User-Agent':'Mozilla/5.0'}
response = requests.post(url, headers=headers)
html = bs(response.text)
lines = []
for line in html.select('#body'):
lines.append(line.text)
lines = lines[0].replace('\r', ' ')
return lines
def get_pages_want(item_code, item_name, page_want):
url_for_link = 'https://finance.naver.com/'
if page_want <= get_end_page(item_code):
pages = []
for page_no in range(1, page_want+1):
url = f'https://finance.naver.com/item/board.naver?'
url = f'{url}code={item_code}&page={page_no}'
headers = {'User-Agent':'Mozilla/5.0'}
response = requests.get(url, headers = headers)
page = pd.read_html(response.text)[1]
page = page.drop('Unnamed: 6', axis=1)
page = page.dropna()
html = bs(response.text)
links = html.select('div > table.type2 > tbody > tr > td > a')
links_list = []
for link in range(len(links)):
links_list.append(url_for_link+links[link]['href'])
page['내용링크'] = links_list
pages.append(page)
pages = pd.concat(pages)
pages['내용'] = pages['내용링크'].map(get_content)
pages = pages.drop('내용링크', axis=1)
pages['종목코드'] = item_code
pages['종목이름'] = item_name
pages['조회'] = pages['조회'].astype(int)
pages['공감'] = pages['공감'].astype(int)
pages['비공감'] = pages['비공감'].astype(int)
cols = ['종목코드', '종목이름', '날짜', '제목', '글쓴이','내용',
'조회', '공감', '비공감']
pages = pages[cols]
pages = pages.drop_duplicates()
file_name = f'{item_name}-{item_code}-{page-want}.csv'
pages.to_csv(file_name, index=False)
return pd.read_csv(file_name)
else:
print('페이지가 끝페이지를 초과했습니다.')
def get_all_pages(item_code, item_name):
url_for_link = 'https://finance.naver.com/'
pages = []
for page_no in range(1, get_end_page(item_code)+1):
url = f'https://finance.naver.com/item/board.naver?'
url = f'{url}code={item_code}&page={page_no}'
headers = {'User-Agent':'Mozilla/5.0'}
response = requests.get(url, headers = headers)
page = pd.read_html(response.text)[1]
page = page.drop('Unnamed: 6', axis=1)
page = page.dropna()
html = bs(response.text)
links = html.select('div > table.type2 > tbody > tr > td > a')
links_list = []
for link in range(len(links)):
links_list.append(url_for_link+links[link]['href'])
page['내용링크'] = links_list
pages.append(page)
pages = pd.concat(pages)
pages['내용'] = pages['내용링크'].map(get_content)
pages = pages.drop('내용링크', axis=1)
pages['종목코드'] = item_code
pages['종목이름'] = item_name
pages['조회'] = pages['조회'].astype(int)
pages['공감'] = pages['공감'].astype(int)
pages['비공감'] = pages['비공감'].astype(int)
cols = ['종목코드', '종목이름', '날짜', '제목', '글쓴이','내용',
'조회', '공감', '비공감']
pages = pages[cols]
pages = pages.drop_duplicates()
file_name = f'{item_name}-{item_code}.csv'
pages.to_csv(file_name, index=False)
return pd.read_csv(file_name)코드가 좀 기네여... 이제 이것을 클래스로 만들어주면 됩니다...ㅎㅎ
이렇게 클래스를 작성했습니다...
import pandas as pd
import requests
from bs4 import BeautifulSoup as bs
def get_content(url):
headers = {'User-Agent':'Mozilla/5.0'}
response = requests.post(url, headers=headers)
html = bs(response.text)
lines = []
for line in html.select('#body'):
lines.append(line.text)
lines = lines[0].replace('\r', ' ')
return lines
class Stock():
def __init__(self, item_code, item_name):
self.item_code = item_code
self.item_name = item_name
def get_end_page(self):
url_for_end = 'https://finance.naver.com/'
url_for_end = f'{url_for_end}item/board.naver?code={self.item_code}'
response = requests.get(url_for_end,
headers = {'User-Agent':'Mozilla/5.0'})
html = bs(response.text)
step1 = html.select('tbody > tr > td > table > tbody > tr > td > a')
step2 = step1[-1]['href'].split('=')[-1]
end_page = int(step2)
return end_page
def get_pages_want(self, page_want):
url_for_link = 'https://finance.naver.com/'
if page_want <= Stock.get_end_page(self):
pages = []
for page_no in range(1, page_want+1):
url = f'https://finance.naver.com/item/board.naver?'
url = f'{url}code={self.item_code}&page={page_no}'
headers = {'User-Agent':'Mozilla/5.0'}
response = requests.get(url, headers = headers)
page = pd.read_html(response.text)[1]
page = page.drop('Unnamed: 6', axis=1)
page = page.dropna()
html = bs(response.text)
links = html.select('div > table.type2 > tbody > tr > td > a')
links_list = []
for link in range(len(links)):
links_list.append(url_for_link+links[link]['href'])
page['내용링크'] = links_list
pages.append(page)
pages = pd.concat(pages)
pages['내용'] = pages['내용링크'].map(get_content)
pages = pages.drop('내용링크', axis=1)
pages['종목코드'] = self.item_code
pages['종목이름'] = self.item_name
pages['조회'] = pages['조회'].astype(int)
pages['공감'] = pages['공감'].astype(int)
pages['비공감'] = pages['비공감'].astype(int)
cols = ['종목코드', '종목이름', '날짜', '제목', '글쓴이','내용',
'조회', '공감', '비공감']
pages = pages[cols]
pages = pages.drop_duplicates()
file_name = f'{self.item_name}-{self.item_code}-{page_want}.csv'
pages.to_csv(file_name, index=False)
return pd.read_csv(file_name)
else:
print('페이지가 끝페이지를 초과했습니다.')
def get_all_pages(self):
url_for_link = 'https://finance.naver.com/'
pages = []
for page_no in range(1, Stock.get_end_page(self)+1):
url = f'https://finance.naver.com/item/board.naver?'
url = f'{url}code={self.item_code}&page={page_no}'
headers = {'User-Agent':'Mozilla/5.0'}
response = requests.get(url, headers = headers)
page = pd.read_html(response.text)[1]
page = page.drop('Unnamed: 6', axis=1)
page = page.dropna()
html = bs(response.text)
links = html.select('div > table.type2 > tbody > tr > td > a')
links_list = []
for link in range(len(links)):
links_list.append(url_for_link+links[link]['href'])
page['내용링크'] = links_list
pages.append(page)
pages = pd.concat(pages)
pages['내용'] = pages['내용링크'].map(get_content)
pages = pages.drop('내용링크', axis=1)
pages['종목코드'] = self.item_code
pages['종목이름'] = self.item_name
pages['조회'] = pages['조회'].astype(int)
pages['공감'] = pages['공감'].astype(int)
pages['비공감'] = pages['비공감'].astype(int)
cols = ['종목코드', '종목이름', '날짜', '제목', '글쓴이','내용',
'조회', '공감', '비공감']
pages = pages[cols]
pages = pages.drop_duplicates()
file_name = f'{self.item_name}-{self.item_code}.csv'
pages.to_csv(file_name, index=False)
return pd.read_csv(file_name)그럼 객체를 생성하고...
볼빅 = Stock('206950', '볼빅')끝페이지를 알아보면...
볼빅.get_end_page()
3페이지네여...
2번째 페이지까지 수집해보면...?
볼빅.get_pages_want(2)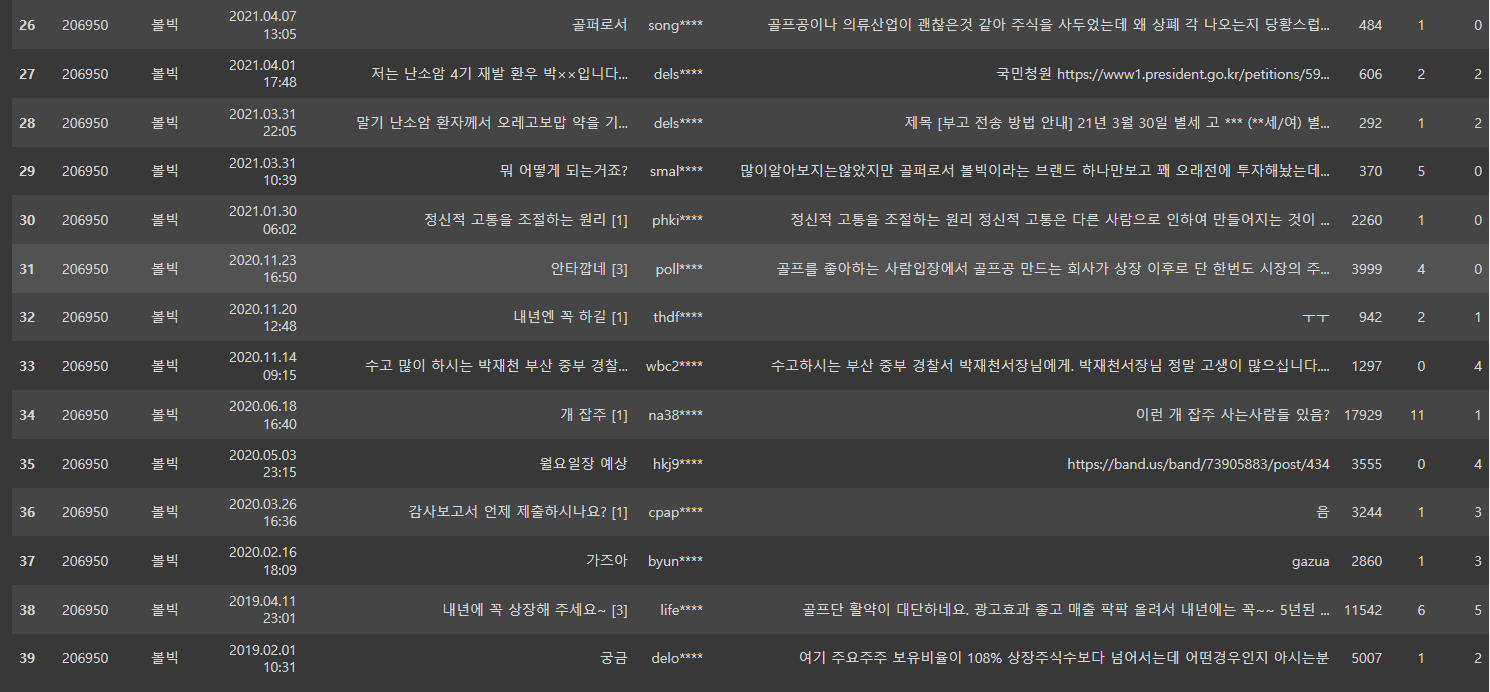
이렇게 2페이지까지 수집이 됩니다.
마지막페이지까지 수집해보면?
볼빅.get_all_pages()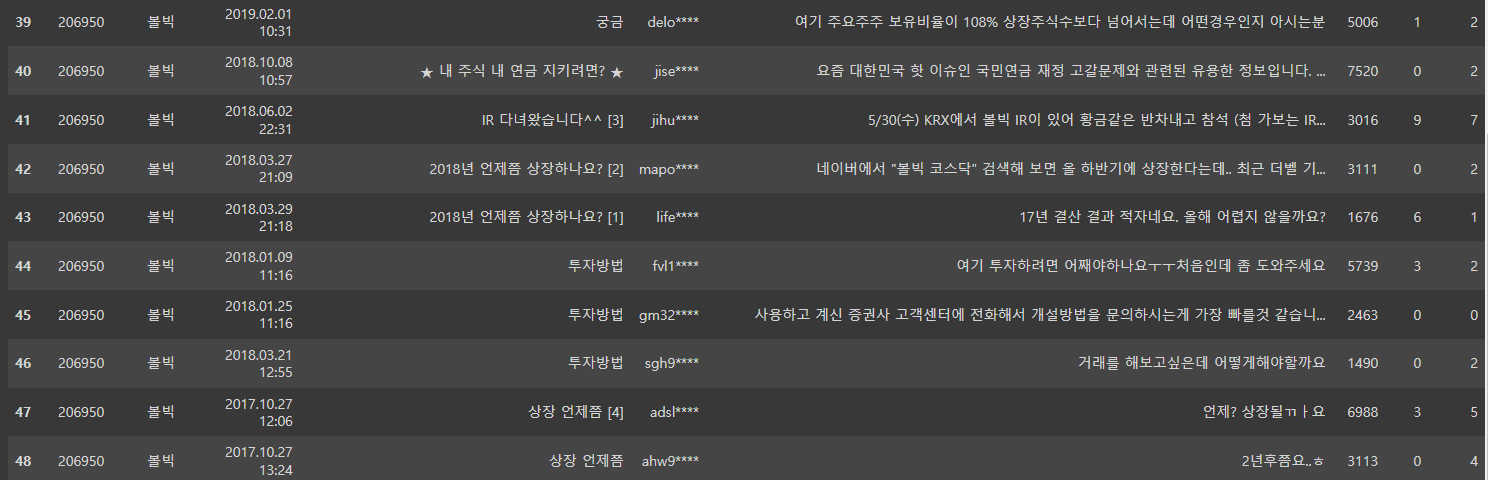
잘 수집이 됩니다.
마지막으로 삼성전자의 마지막 페이지를 알아보고...
5페이지까지 수집해봅시다!
먼저 객체를 생성해주고
삼성전자 = Stock('005930', '삼성전자')
함수 실행!
삼성전자.get_end_page()
팔만대장경이 따로없네여 ㅎㄷㄷ
5페이지까지 수집!
삼성전자.get_pages_want(5)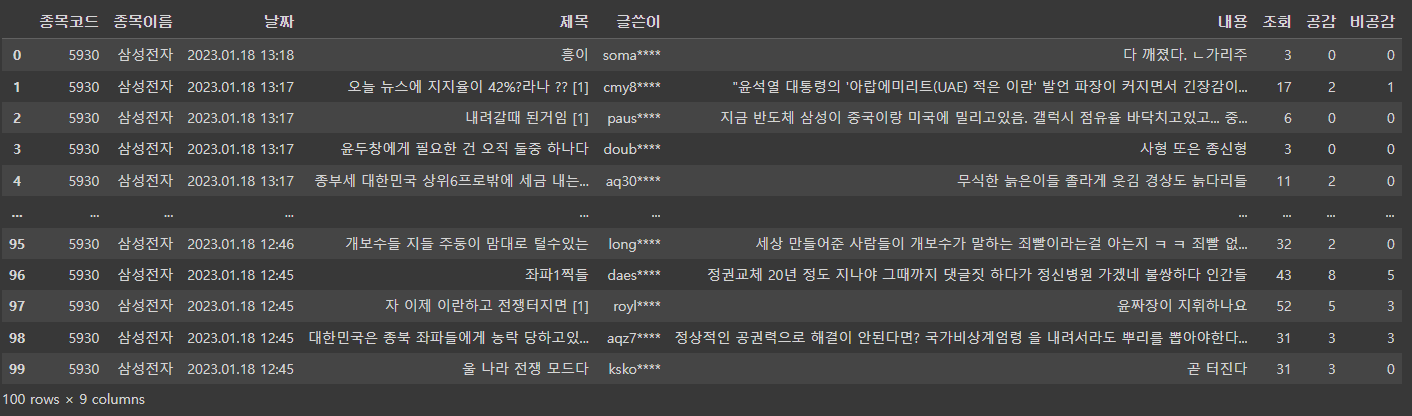
50페이지 총 100개의 글이 수집되었네여...
오늘은 저번에 했던 과제 보충을 해봤습니다...
나머지공부 힘드네여...

'멋쟁이사자처럼 AI스쿨' 카테고리의 다른 글
| 멋쟁이사자처럼 miniproject1(스타벅스 매장 정보 수집하기) (0) | 2023.01.31 |
|---|---|
| 멋쟁이사자처럼 AI스쿨 5주차 회고 (0) | 2023.01.19 |
| 네이버 증권 종목토론실수집(과제) (2) | 2023.01.13 |
| 멋쟁이사자처럼 4주차 회고 (0) | 2023.01.12 |
| 예외처리(파이썬 강의 Day5) (0) | 2023.01.08 |




댓글